This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? Your First Python FastAPI Endpoint Writing a Simple “Hello, World!” Jump Right To The Downloads Section Introduction to FastAPI Python What Is FastAPI?
The Amazon SageMaker Python SDK is an open-source library for training and deploying machine learning (ML) models on Amazon SageMaker. Starting with SageMaker Python SDK version 2.148.0, Provide a name for the stack (for example, networking-stack ), and complete the remaining steps to create the stack.
These models have revolutionized various computervision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. Python 3.10 The notebook queries the endpoint in three ways: the SageMaker Python SDK, the AWS SDK for Python (Boto3), and LangChain.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
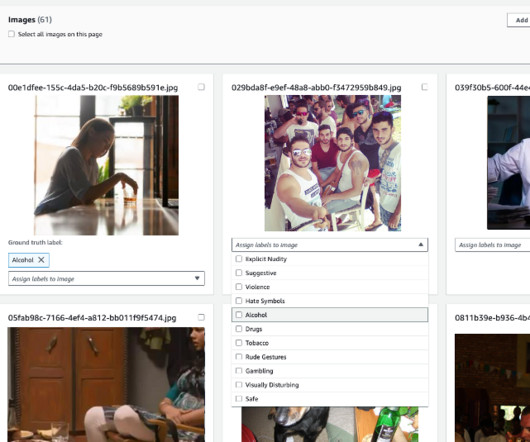
Content moderation in Amazon Rekognition Amazon Rekognition is a managed artificial intelligence (AI) service that offers pre-trained and customizable computervision capabilities to extract information and insights from images and videos. Upload images from your computer and provide labels. Choose Create project.
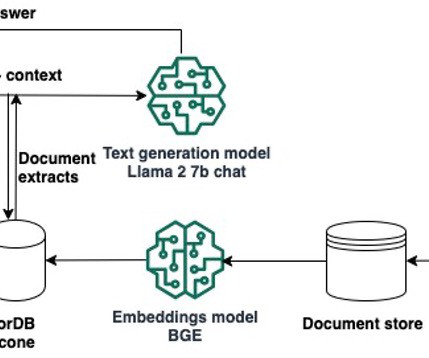
We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat. Python 3.10 transformers==4.33.0 accelerate==0.21.0
Luckily, OpenCV is pip-installable: $ pip install opencv-contrib-python If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes. . Or requires a degree in computer science? EPOCHS ) on Lines 20-23.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
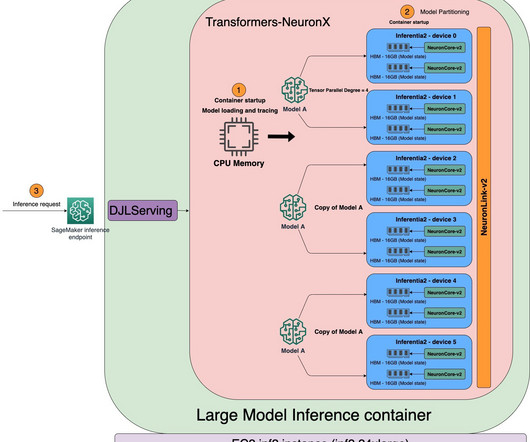
Large language models (LLMs) used to generate text sequences need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity. The inference server handles this automatically, so no client-side code changes are needed.
If you are a regular PyImageSearch reader and have even basic knowledge of Deep Learning in ComputerVision, then this tutorial should be easy to understand. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science?
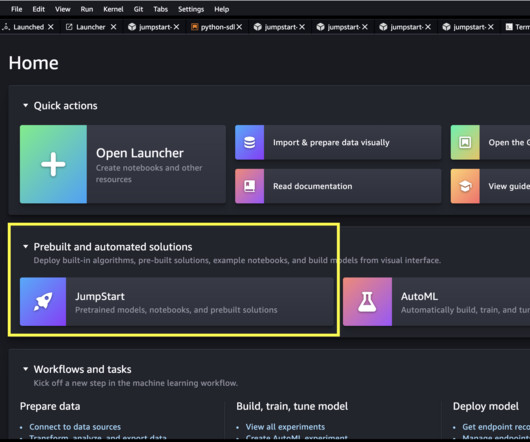
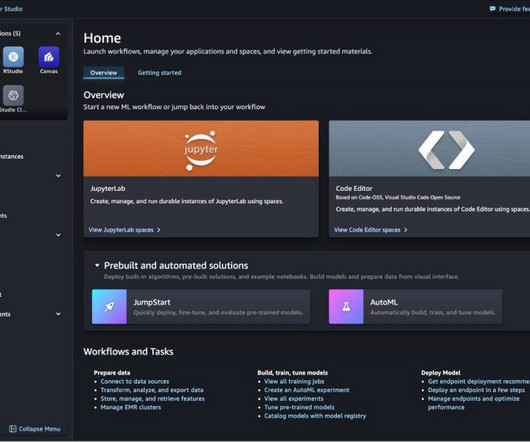
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Discover Falcon 2 11B in SageMaker JumpStart You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. After deployment is complete, you will see that an endpoint is created.
In this post, we walk through how to use the Titan Image Generator and Titan Multimodal Embeddings models via the AWS Python SDK. Code examples are provided in Python, and JavaScript (Node.js) is also available in this GitHub repository. For Python scripts, you can use the AWS SDK for Python (Boto3).
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. We provide you with two different solutions for this use case.
It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. The SageMaker Python SDK is a high-level Python API that abstracts some of the steps and configuration, and makes it easier to deploy models. For that, we are offering improvements in the Python SDK.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. xlarge instance.
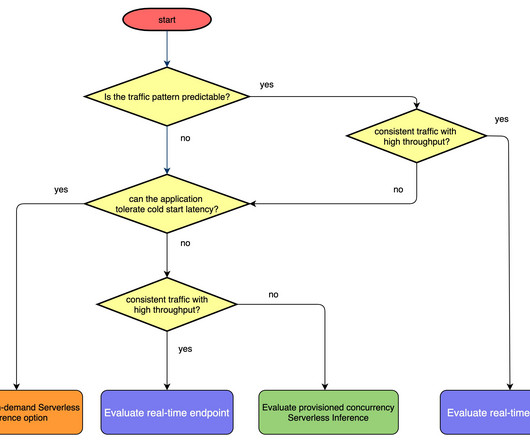
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
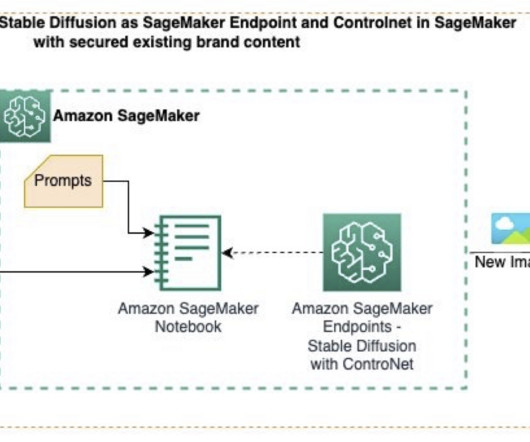
SageMaker endpoints also have auto scaling features and are highly available. For this post, we use the following GitHub sample , which uses Amazon SageMaker Studio with foundation models (Stable Diffusion), prompts, computervision techniques, and a SageMaker endpoint to generate new images from existing images.
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
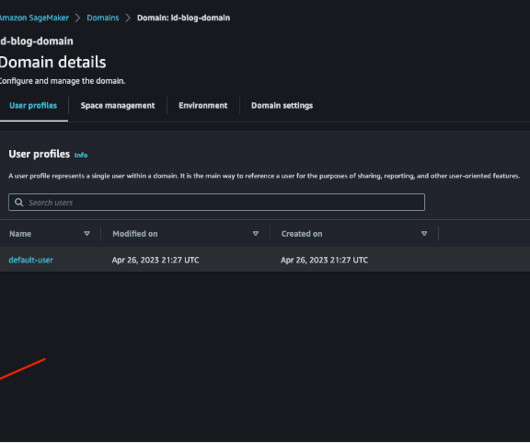
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
It also overcomes complex challenges in speech recognition and computervision, such as creating a transcript of a sound sample or a description of an image. Our model gets a prompt and auto-completes it. NLP doesn’t just deal with written text. Cool, we learned what NLP is in this section. Note that this […]
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. You can use a SageMaker notebook or an Amazon Elastic Compute Cloud (Amazon EC2) instance to compile the model. These endpoints are fully managed and support auto scaling.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
Einstein has a list of over 60 features, unlocked at different price points and segmented into four main categories: machine learning (ML), natural language processing (NLP), computervision, and automatic speech recognition. This is particularly valuable given the current market shortages of high-end GPUs.
LangChain is an open source Python library designed to build applications with LLMs. When you create an AWS account, you get a single sign-on (SSO) identity that has complete access to all the AWS services and resources in the account. There was no monitoring, load balancing, auto-scaling, or persistent storage at the time.
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. You can monitor the status of the endpoint by calling DescribeEndpoint , which will tell you when everything is complete. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and ComputerVision.
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. amazonaws.com/ :latest Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Download the CloudFormation template kendrablog-sam-template.yml.
Scrapy A powerful, open-source Python framework called Scrapy was created for highly effective web scraping and data extraction. This tool’s AI-powered auto-detect functionality makes data collecting as simple as point-and-click by automatically recognizing data fields on the majority of websites. Puppeteer A robust Node.js
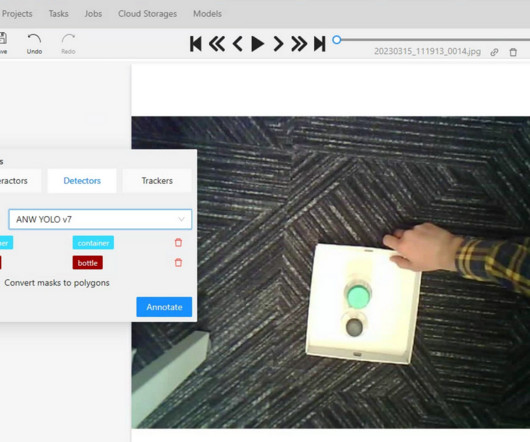
that comply to YOLOv5 with specific requirement on model output, which easily got mess up thru conversion of model from PyTorch > ONNX > Tensorflow > TensorflowJS) ComputerVision Annotation Tool (CVAT) CVAT is build by Intel for doing computervision annotation which put together openCV, OpenVino (to speed up CPU inference).
It’s an auto-regressive language model that uses an optimized transformer architecture. Discover models You can access the foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. Eiffel Tower: No trip to Paris is complete without a visit to the iconic Eiffel Tower.
in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. With that, we’ve completed the training of a variational autoencoder on the Fashion-MNIST dataset. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? The torch.nn
Complete the following steps to edit an existing space: On the space details page, choose Stop space. Reconfigure the compute, storage, or runtime. EFS mounts provide a solid alternative for sharing Python environments like conda or virtualenv across multiple workspaces. Choose Create JupyterLab space. Choose Create space.
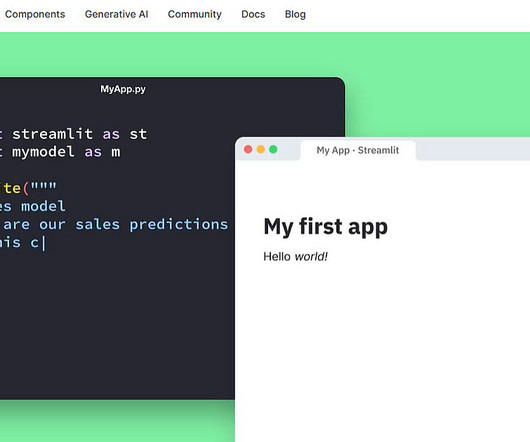
About us: At viso.ai, we’ve built the end-to-end machine learning infrastructure for enterprises to scale their computervision applications easily. Viso Suite, the end-to-end computervision solution What is Streamlit? Streamlit is a Python-based library specifically developed for machine learning engineers.
It supports languages like Python and R and processes the data with the help of data flow graphs. It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. Keras supports a high-level neural network API written in Python. Cons Low level computation cannot be handled by keras.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. For Secret type , choose Other type of secret.
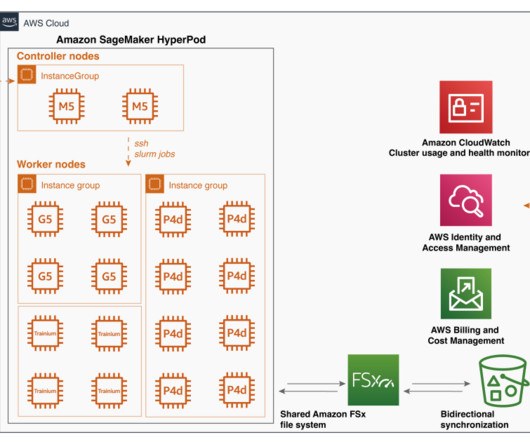
You can also split your training data and model across all nodes for parallel processing, fully using the cluster’s compute and network infrastructure. Moreover, you have full control over the execution environment, including the ability to easily install and customize virtual Python environments for each project.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Can you see the complete model lineage with data/models/experiments used downstream? Auto-annotation tools such as Meta’s Segment Anything Model and other AI-assisted labeling techniques.
Although this post focuses on LLMs, most of its best practices are relevant for any kind of large-model training, including computervision and multi-modal models, such as Stable Diffusion. The AWS Python SDK Boto3 may also be combined with Torch Dataset classes to create custom data loading code.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Discover models You can access the foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this post, we walk through how to use Llama 2 models via SageMaker JumpStart.
SageMaker LMI containers includes model download optimization by using the s5cmd library to speed up the model download time and container startup times, and eventually speed up auto scaling on SageMaker. It has faster loading and uses multi-process loading on Python. It supports AOT compilation and uses CPU to partition the model.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M UGIF A multi-lingual, multi-modal UI grounded dataset for step-by-step task completion on the smartphone. We also continued to release sustainability data via Data Commons and invite others to use it for their research.
The lines are then parsed into pythonic dictionaries. We decided to analyze the images in the following ways: Split the image into tiles and use tiles as input to a computervision model Extract histograms of colors in images Tile generation The raw TIFF input images are too big to use for processing directly.
But nowadays, it is used for various tasks, ranging from language modeling to computervision and generative AI. You can find all the code in two Colab notebooks: Fine-tuning Model selection Related post How to Version and Organize ML Experiments That You Run in Google Colab Read more We will use Python 3.10 in our codes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content