This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This new capability integrates the power of graph data modeling with advanced natural language processing (NLP). By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Configure your knowledge base by adding filters or guardrails.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computervision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
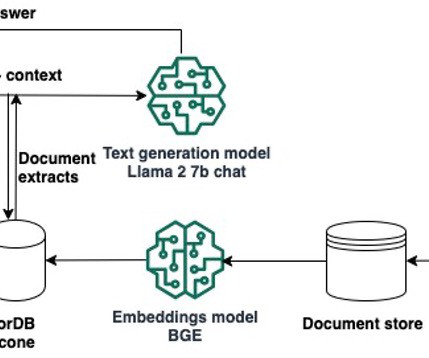
We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat. Llama 2 7b chat is available under the Llama 2 license.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deep learning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
MAX_BATCH_PREFILL_TOKENS : This parameter caps the total number of tokens processed during the prefill stage across all batched requests, a phase that is both memory-intensive and compute-bound, thereby optimizing resource utilization and preventing out-of-memory errors. The best performance was observed on ml.p4dn.24xlarge 48xlarge , ml.g6e.12xlarge
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
Large language models (LLMs) used to generate text sequences need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity. Values include auto , scheduler , and lmi-dist. It improves throughput and doesn’t sacrifice the time to first byte latency.
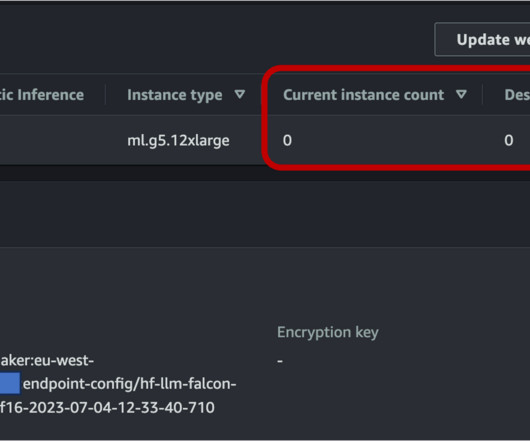
These models have revolutionized various computervision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
Einstein has a list of over 60 features, unlocked at different price points and segmented into four main categories: machine learning (ML), natural language processing (NLP), computervision, and automatic speech recognition. These models are designed to provide advanced NLP capabilities for various business applications.
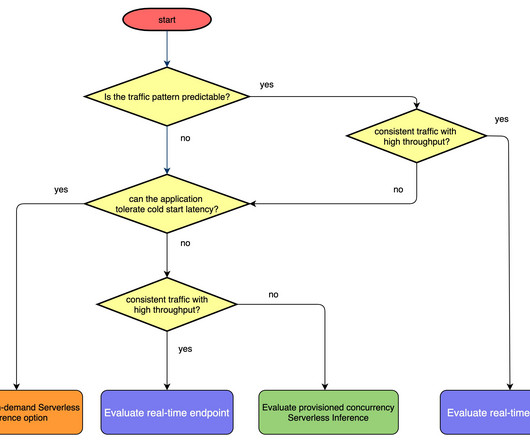
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight.
We orchestrate our ML training and deployment pipelines using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which enables us to focus more on programmatically authoring workflows and pipelines without having to worry about auto scaling or infrastructure maintenance. Sahil Thapar is an Enterprise Solutions Architect.
To remove an element, omit the text parameter completely. A compact 5-cup single serve coffee maker in matt black with travel mug auto-dispensing feature. - Experienced in AI/ML, NLP, and Search, he is interested in building products that solves customer pain points with innovative technology. Parse and decode the response.
We focused our internal tech on computervision to detect things in images and video (fires, accidents, logos, objects, etc.) and NLP to determine what people were talking about. Is the foundation of summaries, agent coaching, auto qualification, to name a few. to triangulate and validate when an “event” happens.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. You can monitor the status of the endpoint by calling DescribeEndpoint , which will tell you when everything is complete. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and ComputerVision.
Set up the environment To deploy a complete infrastructure including networking and a Studio domain, complete the following steps: Clone the GitHub repository. Provide a name for the stack (for example, networking-stack ), and complete the remaining steps to create the stack. something: '1.0'
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created. The output shows the expected JSON file content, illustrating the model’s natural language processing (NLP) and code generation capabilities.
Prerequisites Before getting started, complete the following prerequisites: Create an AWS account or use an existing AWS account. Set up your resources After you complete all the prerequisites, you’re ready to deploy the solution. He is passionate about computervision, NLP, Generative AI and MLOps.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. Feel free to share your thoughts in the comments.
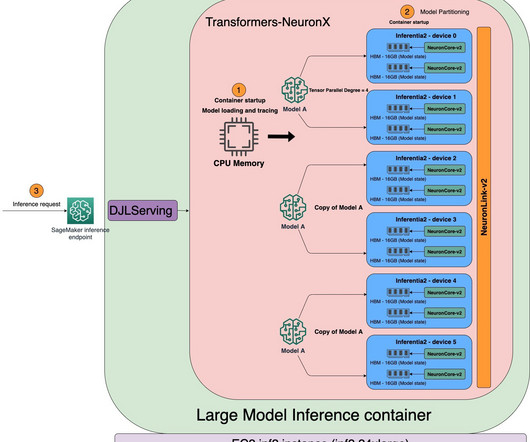
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. These endpoints are fully managed and support auto scaling. When the tracing is complete, the model is partitioned across the NeuronCores based on the tensor parallel degree.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
Organizations can easily source data to promote the development, deployment, and scaling of their computervision applications. Viso Suite is the End-to-End, No-Code ComputerVision Platform – Learn more What is Synthetic Data? 1: Variational Auto-Encoder. Get a demo. Technique No.1:
Furthermore, the CPUUtilization metric shows a classic pattern of periodic high and low CPU demand, which makes this endpoint a good candidate for auto scaling. You can start with a smaller instance and scale out first as your compute demand changes. If all are successful, then the batch transform job is marked as complete.
Complete the following steps to edit an existing space: On the space details page, choose Stop space. Reconfigure the compute, storage, or runtime. To start using Amazon CodeWhisperer, make sure that the Resume Auto-Suggestions feature is activated. Choose Create JupyterLab space. For Name , enter a name for your Space.
provides the world’s only end-to-end computervision platform Viso Suite. The solution enables leading companies to build, deploy and scale real-world computervision systems. The vision task of recognizing text from the cropped regions is called Scene Text Recognition (STR). Get a demo here.
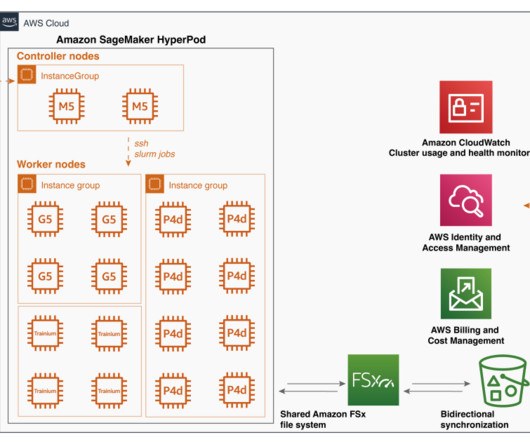
As a managed service with auto scaling, SageMaker makes parallel generation of multiple videos possible using either the same reference image with different reference videos or the reverse. Once the SageMaker HyperPod cluster deletion is complete, delete the CloudFormation stack. In his spare time, he loves running and hiking.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Always make sure that sensitive data is handled securely to avoid potential security risks.
Although this post focuses on LLMs, most of its best practices are relevant for any kind of large-model training, including computervision and multi-modal models, such as Stable Diffusion. The preparation of a natural language processing (NLP) dataset abounds with share-nothing parallelism opportunities.
SageMaker LMI containers includes model download optimization by using the s5cmd library to speed up the model download time and container startup times, and eventually speed up auto scaling on SageMaker. A complete example that illustrates the no-code option can be found in the following notebook.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M Re-contextualizing Fairness in NLP for India A dataset of region and religion-based societal stereotypes in India, with a list of identity terms and templates for reproducing the results from the " Re-contextualizing Fairness in NLP " paper.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. The complete example is shown in the accompanying notebook. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion.
But nowadays, it is used for various tasks, ranging from language modeling to computervision and generative AI. Related post Tokenization in NLP: Types, Challenges, Examples, Tools Read more For training, we’ll create a so-called prompt that contains not only the question and the context but also the answer.
Once the exploratory steps are completed, the cleansed data is subjected to various algorithms like predictive analysis, regression, text mining, recognition patterns, etc depending on the requirements. It is the discounting of those subjects that did not complete the trial. What are auto-encoders?
In order to power these applications, as well as those using other data modalities like computervision, we need a robust and efficient workflow to quickly annotate data, train and evaluate models, and iterate quickly. As part of this strategy, they developed an in-house passport analysis model to verify passenger IDs.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Write a response that appropriately completes the request.nn### Instruction:nWhen did Felix Luna die?nn### In this post, we walk through how to fine-tune Llama 2 pre-trained text generation models via SageMaker JumpStart.
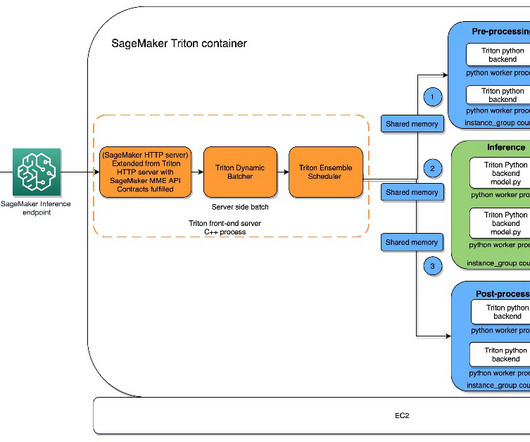
SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics. Returns - pb_utils.ModelConfig An object containing the auto-completed model configuration """ def initialize(self, args): `initialize` is called only once when the model is being loaded.
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. Multiple methods exist for assigning importance scores to the inputs of an NLP model. A breakdown of this architecture is provided here. This is the first article in the series.
With this feature, you can closely match your compute resource usage to your actual needs, potentially reducing costs during times of low demand. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
The models can be completely heterogenous, with their own independent serving stack. This includes loading the model from Amazon Simple Storage Service (Amazon S3), for example, database lookups to validate the input, obtaining pre-computed features from the feature store, and so on. ML inference options.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content