This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud. With this feature, you can closely match your compute resource usage to your actual needs, potentially reducing costs during times of low demand.
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Key features of Katana: Live Inventory Control: Real-time tracking of raw materials and products with auto-booking to allocate stock to orders efficiently.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. If the image is completely unmodified, then all 8×8 squares should have similar error potentials.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Figure 2: CLIP matches text and images in a shared embedding space, enabling text-to-image and image-to-text tasks(source: Multi-modal ML with OpenAI’s CLIP | Pinecone ). Thats not the case.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. xlarge instance.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. For more information, refer to Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 1: PySDK Improvements.
MAX_BATCH_PREFILL_TOKENS : This parameter caps the total number of tokens processed during the prefill stage across all batched requests, a phase that is both memory-intensive and compute-bound, thereby optimizing resource utilization and preventing out-of-memory errors. The best performance was observed on ml.p4dn.24xlarge 48xlarge , ml.g6e.12xlarge
Video The complete content that enables analysis at the full video level. Along with the summary, BDA generates a complete audio transcript that includes speaker identification. helping customers design and build AI/ML solutions. This API requires input/output S3 locations and a cross-Region profile ARN in your request.
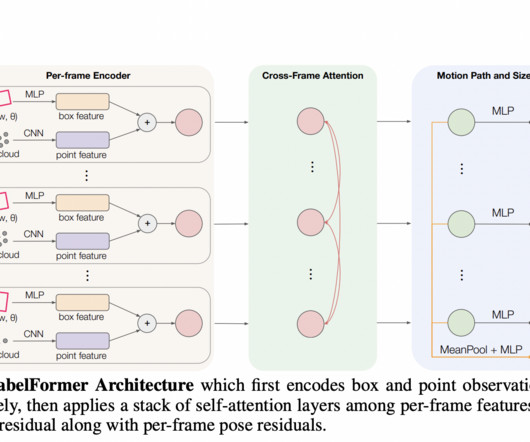
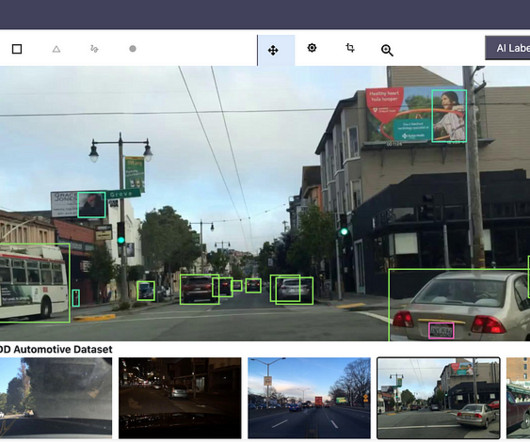
Auto-labeling methods that automatically produce sensor data labels have recently gained more attention. Auto-labeling may provide far bigger datasets at a fraction of the expense of human annotation if its computational cost is less than that of human annotation and the labels it produces are of comparable quality.
With HouseCanary, agents and investors can instantly obtain a data-driven valuation for any residential property, complete with a confidence score and 3-year appreciation forecast. The platform also provides robust marketing tools like branded video ads, AI-crafted listing flyers, and social media auto-posting.
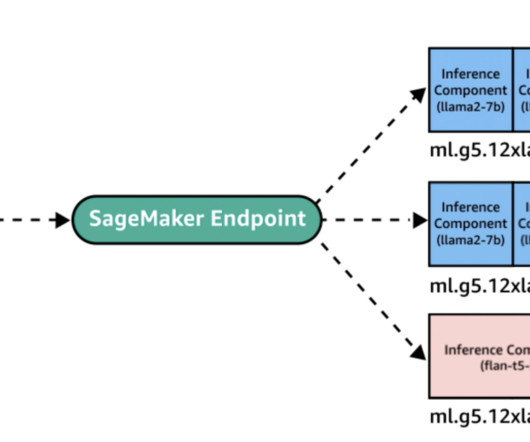
Amazon SageMaker provides a number of options for users who are looking for a solution to host their machine learning (ML) models. For that use case, SageMaker provides SageMaker single model endpoints (SMEs), which allow you to deploy a single ML model against a logical endpoint.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
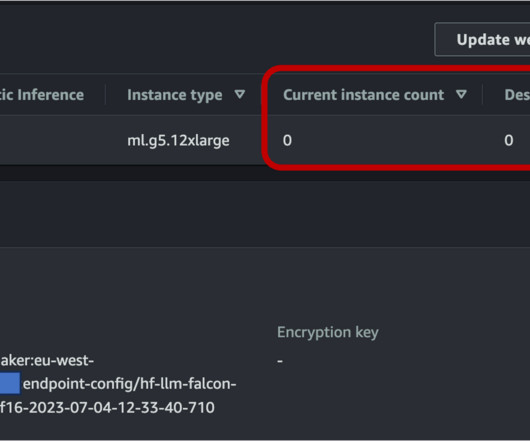
Because FM outputs could range from a single sentence to multiple paragraphs, the time it takes to complete the inference request varies significantly, leading to unpredictable spikes in latency if the requests are routed randomly between instances. You can scale down to zero copies of a model to free up resources for other models.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
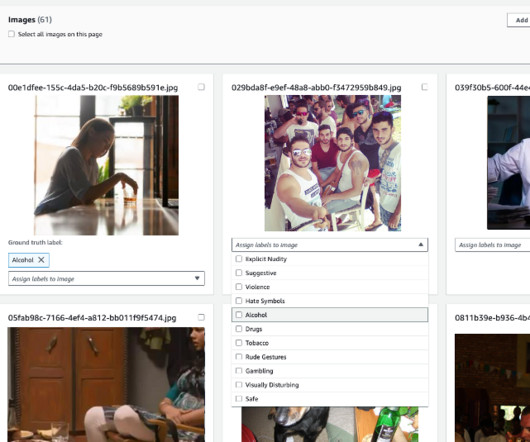
Content moderation in Amazon Rekognition Amazon Rekognition is a managed artificial intelligence (AI) service that offers pre-trained and customizable computervision capabilities to extract information and insights from images and videos. Upload images from your computer and provide labels. Choose Create project.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects.
In computervision (CV), adding tags to identify objects of interest or bounding boxes to locate the objects is called labeling. One technique used to solve this problem today is auto-labeling, which is highlighted in the following diagram for a modular functions design for ADAS on AWS.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. Start the model version when training is complete.
These models have revolutionized various computervision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. It provides access to a wide range of pre-trained models for different problem types, allowing you to start your ML tasks with a solid foundation.
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. amazonaws.com/ :latest Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Download the CloudFormation template kendrablog-sam-template.yml.
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of scalable compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are transforming their businesses.
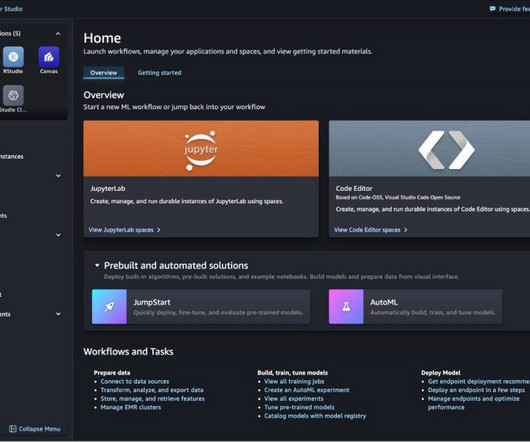
In SageMaker Studio, the integrated development environment (IDE) purpose-built for ML, you can launch notebooks that run on different instance types and with different configurations, collaborate with colleagues, and access additional purpose-built features for machine learning (ML).
Using notebooks to fine-tune LLMs SageMaker comes with two options to spin up fully managed notebooks for exploring data and building machine learning (ML) models. The first option is fast start, collaborative notebooks accessible within Amazon SageMaker Studio , a fully integrated development environment (IDE) for ML.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
Create a knowledge base To create a new knowledge base in Amazon Bedrock, complete the following steps. For Data source name , Amazon Bedrock prepopulates the auto-generated data source name; however, you can change it to your requirements. You should see a Successfully built message when the build is complete. Choose Next.
With terabytes of data generated by the product, the security analytics team focuses on building machine learning (ML) solutions to surface critical attacks and spotlight emerging threats from noise. Solution overview The following diagram illustrates the ML platform architecture.
We’re at an exciting inflection point in the widespread adoption of machine learning (ML), and we believe most customer experiences and applications will be reinvented with generative AI. Generative AI can create new content and ideas, including conversations, stories, images, videos, and music. This is not memory and cost efficient.
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
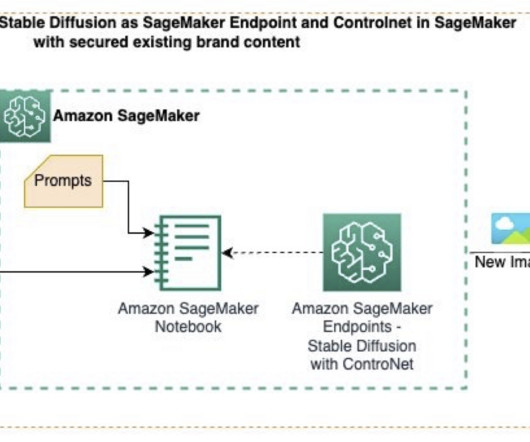
In this post, we demonstrate how you can generate new images from existing base images using Amazon SageMaker , a fully managed service to build, train, and deploy ML models for at scale. SageMaker endpoints also have auto scaling features and are highly available. The following diagram illustrates the solution architecture.
Because selecting it judicially reduces the data movement, data processing computation, and data labeling costs downstream Then once the data is collected, synchronized, and selected, it needs to be labeled, which, again, no one from the AI team wants to do. SAM from Meta AI — the chatGPT moment for computervision AI It’s a disruption.
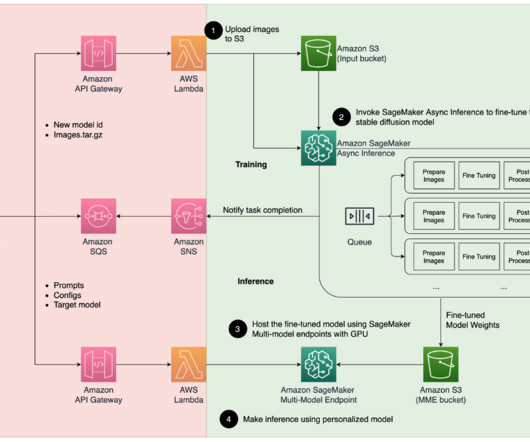
It also provides a built-in queuing mechanism for queuing up requests, and a task completion notification mechanism via Amazon SNS, in addition to other native features of SageMaker hosting such as auto scaling. To host the asynchronous endpoint, we must complete several steps. helping customers design and build AI/ML solutions.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
The Amazon SageMaker Python SDK is an open-source library for training and deploying machine learning (ML) models on Amazon SageMaker. In such cases, data scientists have to provide these parameters to their ML model training and deployment code manually, by noting down subnets, security groups, and KMS keys. something: '1.0'
is an auto-regressive language model that uses an optimized transformer architecture. You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch. 405B-Instruct You can use Llama models for text completion for any piece of text.
Provides modularity as a series of completely configurable, independent modules that can be combined with the fewest restrictions possible. Most of the organizations make use of Caffe in order to deal with computervision and classification related problems. Pros It’s very efficient to perform autoML along with H2O.
SageMaker is a fully managed service that provides every developer and data scientist with the ability to prepare, build, train, and deploy machine learning (ML) models quickly. SageMaker provides several built-in algorithms and container images that you can use to accelerate training and deployment of ML models. medium instance type.
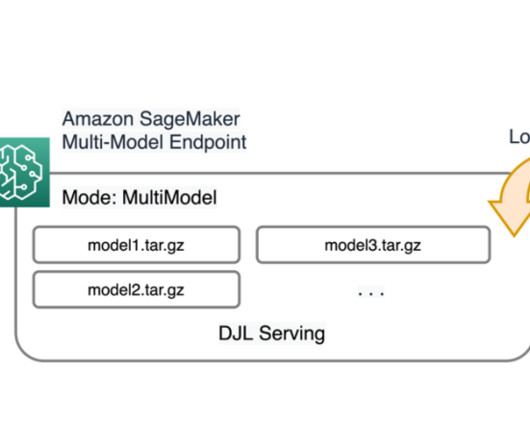
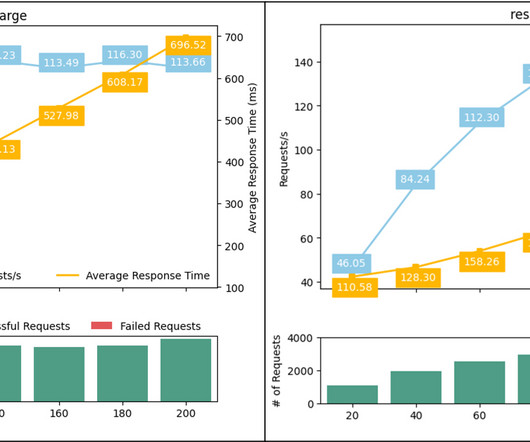
Amazon SageMaker multi-model endpoints (MMEs) provide a scalable and cost-effective way to deploy a large number of machine learning (ML) models. It gives you the ability to deploy multiple ML models in a single serving container behind a single endpoint. The bottom bar charts show the count of successful and failed requests.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
Amazon SageMaker Studio offers a broad set of fully managed integrated development environments (IDEs) for machine learning (ML) development, including JupyterLab, Code Editor based on Code-OSS (Visual Studio Code Open Source), and RStudio. It’s attached to a MLcompute instance whenever a Space is run. Choose Create space.
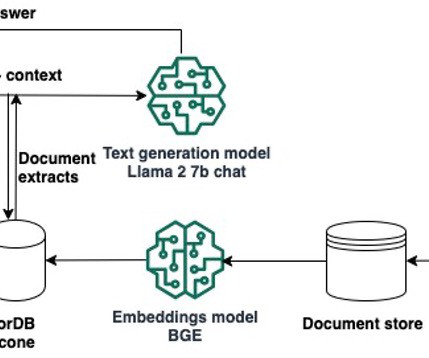
and Salina Wu, Senior ML Engineer at Forethought Technologies, Inc. Infrastructure challenges To help bring these capabilities to market, Forethought efficiently scales its ML workloads and provides hyper-personalized solutions tailored to each customer’s specific use case. The following diagram illustrates our legacy architecture.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content