This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computervision, enabling automated and intelligent data extraction. Context-Aware Data Extraction LLMs possess strong contextual understanding, honed through extensive training on large datasets.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. An S3 bucket prepared to store the custom model. Choose Import model.
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced largelanguagemodel (LLM) distinguished by its innovative, multi-stage training process. The model employs a chain-of-thought (CoT) approach that systematically breaks down complex queries into clear, logical steps. 24xlarge , followed by ml.g6e.48xlarge
The FedML framework is model agnostic, including recently added support for largelanguagemodels (LLMs). For more information, refer to Releasing FedLLM: Build Your Own LargeLanguageModels on Proprietary Data using the FedML Platform. Choose New Application.
Foundation models are a class of generative AI models that are capable of understanding and generating human-like content, thanks to the vast amounts of unstructured data they have been trained on. You need to first register your endpoint variant with Application Auto Scaling, define a scaling policy, and then apply the scaling policy.
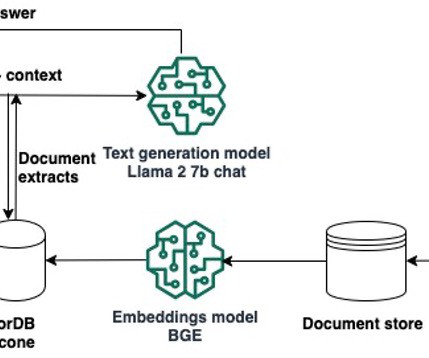
Retrieval Augmented Generation (RAG) allows you to provide a largelanguagemodel (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. The same approach can be used with different models and vector databases.
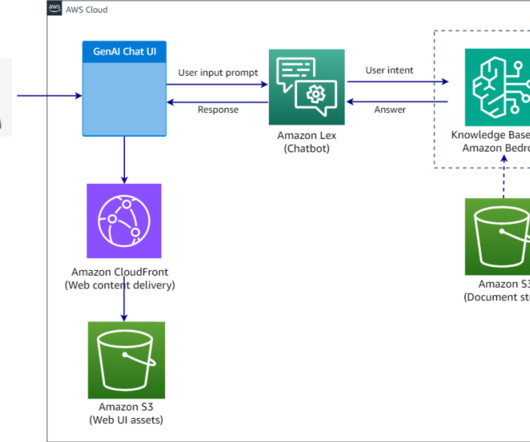
It features natural language understanding capabilities to recognize more accurate identification of user intent and fulfills the user intent faster. Amazon Bedrock simplifies the process of developing and scaling generative AI applications powered by largelanguagemodels (LLMs) and other foundation models (FMs).
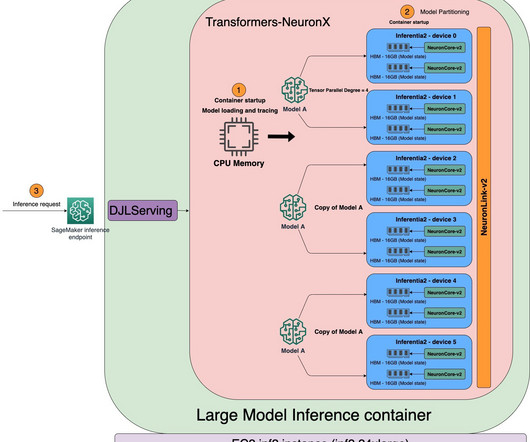
Transformers are slow and memory-hungry on generating long text sequences due to the sheer size of the models. Largelanguagemodels (LLMs) used to generate text sequences need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity.
Today we introduce PaLM-E , a new generalist robotics model that overcomes these issues by transferring knowledge from varied visual and language domains to a robotics system. We began with PaLM , a powerful largelanguagemodel, and “embodied” it (the “ E ” in PaLM-E), by complementing it with sensor data from the robotic agent.
What is the optimal framework and configuration for hosting largelanguagemodels (LLMs) for text-generating generative AI applications? The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The default is 32.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics.
Text-Encoder Design: Authors utilize Gemma -2, a small decoder-based largelanguagemodel. Its small architecture has better instruction following and reasoning abilities with Chain of Thought, and Context Learning provides better performance than huge encoder-based models like T5.
Einstein has a list of over 60 features, unlocked at different price points and segmented into four main categories: machine learning (ML), natural language processing (NLP), computervision, and automatic speech recognition. These models are designed to provide advanced NLP capabilities for various business applications.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. An S3 bucket prepared to store the custom model. Choose Import model.
When you create an AWS account, you get a single sign-on (SSO) identity that has complete access to all the AWS services and resources in the account. Signing in to the AWS Management Console using the email address and password that you used to create the account gives you complete access to all the AWS resources in your account.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
It’s a next generation model in the Falcon family—a more efficient and accessible largelanguagemodel (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Deploy the model in SageMaker JumpStart Deployment starts when you choose Deploy.
Today, we are excited to announce that Amazon SageMaker supports AWS Inferentia2 (ml.inf2) and AWS Trainium (ml.trn1) based SageMaker instances to host generative AI models for real-time and asynchronous inference. ml.inf2 instances are available for model deployment on SageMaker in US East (Ohio) and ml.trn1 instances in US East (N.
SupportGPT leverages state-of-the-art Information Retrieval (IR) systems and largelanguagemodels (LLMs) to power over 30 million customer interactions annually. Forethought uses per-customer fine-tuned models to detect customer intents in order to solve customer interactions. 2xlarge instances.
The Test inference tab enables you to test your model by sending test requests to one of the in-service models directly from the SageMaker Studio interface. You can also edit the auto scaling policy on the Auto-scaling tab on this page. Some familiarity with SageMaker Studio is also assumed.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive languagemodel developed on a sophisticated transformer foundation. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion.
Last week, Technology Innovation Institute (TII) launched TII Falcon LLM , an open-source foundational largelanguagemodel (LLM). Legacy hosting solutions used for smaller models typically don’t offer this type of functionality, adding to the difficulty. code_falcon40b_deepspeed/model.py add_as_json(result) That’s it!
However, they’re unable to gain insights such as using the information locked in the documents for largelanguagemodels (LLMs) or search until they extract the text, forms, tables, and other structured data. When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console.
What is Falcon 180B Falcon 180B is a model released by TII that follows previous releases in the Falcon family. It’s an auto-regressive languagemodel that uses an optimized transformer architecture. Inference and example prompts for Falcon 180B Falcon models can be used for text completion for any piece of text.
We see the model error rate has increased, from an RMSE of 282K to an RMSE of 352K. From this, we can conclude that three simple questions from the images improved model accuracy by about 20%. In social media platforms, photos could be auto-tagged for subsequent use.
Is it accessible from your language/framework/infrastructure, framework, or infrastructure? Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the completemodel lineage with data/models/experiments used downstream? Can you render audio/video?
Complete the following steps to edit an existing space: On the space details page, choose Stop space. Reconfigure the compute, storage, or runtime. To start using Amazon CodeWhisperer, make sure that the Resume Auto-Suggestions feature is activated. Choose Create JupyterLab space. For Name , enter a name for your Space.
The diagram shows the workflow for building and deploying models using the AutoMLV2 API. In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. Data preparation The foundation of any machine learning project is data preparation.
Today, we are excited to announce that Llama 2 foundation models developed by Meta are available for customers through Amazon SageMaker JumpStart. The Llama 2 family of largelanguagemodels (LLMs) is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. Manage Amazon SageMaker endpoints – Similarly, for organizations that aim for inference type selection and endpoints running time management, you can deploy open source models on Amazon SageMaker.
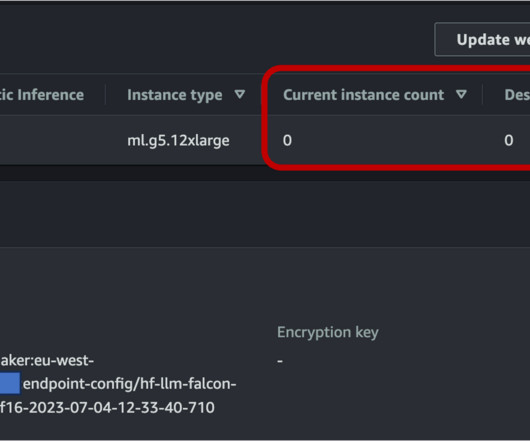
Furthermore, the CPUUtilization metric shows a classic pattern of periodic high and low CPU demand, which makes this endpoint a good candidate for auto scaling. You can start with a smaller instance and scale out first as your compute demand changes. For information, see Automatically Scale Amazon SageMaker Models.
Today, we are excited to announce the capability to fine-tune Llama 2 models by Meta using Amazon SageMaker JumpStart. The Llama 2 family of largelanguagemodels (LLMs) is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters.
Quantization and compression can reduce model size and serving cost by reducing the precision of weights or reducing the number of parameters via pruning or distillation. Compilation can optimize the computation graph and fuse operators to reduce memory and compute requirements of a model.
Some original Tesla features are embedded into the robot, such as a self-running computer, autopilot cameras, a set of AI tools, neural network planning , auto-labeling for objects, etc. The data from multiple sensors are combined and processed to create a complete understanding of the environment.
Then we show how you can enhance the in-notebook SQL experience using Text-to-SQL capabilities provided by advanced largelanguagemodels (LLMs) to write complex SQL queries using natural language text as input. Complete the following steps: On the Secrets Manager console, choose Store a new secret.
The rise of LargeLanguageModels (LLMs) is sparking the imagination of developers worldwide, with new generative AI applications reaching hundreds of millions of people around the world. These models are trained on massive datasets, and used to solve a variety of tasks, from natural language processing to image generation.
Imagine you’re facing the following challenge: you want to develop a LargeLanguageModel (LLM) that can proficiently respond to inquiries in Portuguese. You have a valuable dataset and can choose from various base models. These models are usually based on an architecture called transformers.
With this feature, you can closely match your compute resource usage to your actual needs, potentially reducing costs during times of low demand. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
Fine-tuning largelanguagemodels (LLMs) allows you to adjust open-source foundational models to achieve improved performance on your domain-specific tasks. In this post, we discuss the advantages of using Amazon SageMaker notebooks to fine-tune state-of-the-art open-source models.
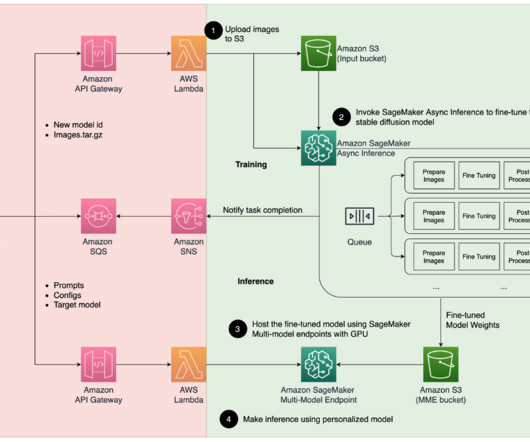
The fine-tuning process starts with preparing the images, including face cropping, background variation, and resizing for the model. Then we use Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning technique for largelanguagemodels (LLMs), to fine-tune the model. The first is to define our model server.
collection of multilingual largelanguagemodels (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. is an auto-regressive languagemodel that uses an optimized transformer architecture.
Prime Air (our drones) and the computervision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deep learning. To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content