This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? Jump Right To The Downloads Section Introduction to FastAPI Python What Is FastAPI? reload : Enables auto-reloading, so the server restarts automatically when you make changes to your code.
Jump Right To The Downloads Section Building on FastAPI Foundations In the previous lesson , we laid the groundwork for understanding and working with FastAPI. Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Or requires a degree in computer science?
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
11B-Vision-Instruct ) or Simple Storage Service (S3) URI containing the model files. HF_TOKEN : This parameter variable provides the access token required to download gated models from the Hugging Face Hub, such as Llama or Mistral. For a complete list of runtime configurations, please refer to text-generation-launcher arguments.
If you are a regular PyImageSearch reader and have even basic knowledge of Deep Learning in ComputerVision, then this tutorial should be easy to understand. Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images. Before you load this data, you need to download it from Kaggle.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
Jump Right To The Downloads Section Building a Dataset for Triplet Loss with Keras and TensorFlow In the previous tutorial , we looked into the formulation of the simplest form of contrastive loss. Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images. The crop_faces.py
In computervision (CV), adding tags to identify objects of interest or bounding boxes to locate the objects is called labeling. One technique used to solve this problem today is auto-labeling, which is highlighted in the following diagram for a modular functions design for ADAS on AWS.
EKS Blueprints helps compose complete EKS clusters that are fully bootstrapped with the operational software that is needed to deploy and operate workloads. Trigger federated training To run federated training, complete the following steps: On the FedML UI, choose Project List in the navigation pane. Choose New Application.
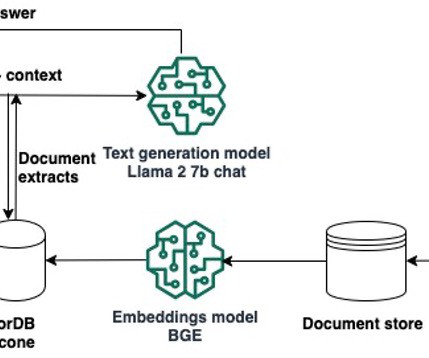
We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat. Download and save the model in the local directory in Studio.
These models have revolutionized various computervision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times.
It also overcomes complex challenges in speech recognition and computervision, such as creating a transcript of a sound sample or a description of an image. It allows you to easily download and train state-of-the-art pre-trained models. Next, when creating the classifier object, the model was downloaded. Let me explain.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. yaml locally.
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. The LMI container will help address much of the undifferentiated heavy lifting associated with hosting LLMs, including downloading the model and partitioning the model artifact so that its comprising parameters can be spread across multiple GPUs.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. Looking for the source code to this post?
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. xlarge instance. You can also run this example on a Studio notebook instance.
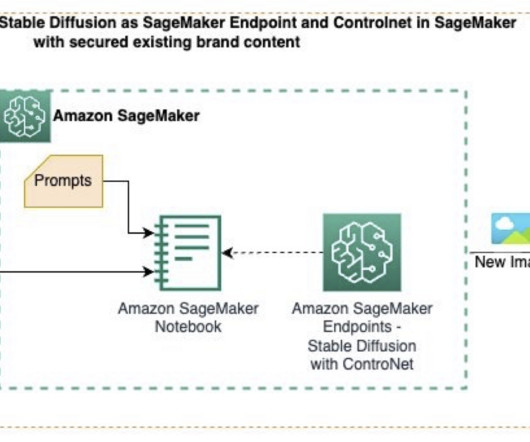
SageMaker endpoints also have auto scaling features and are highly available. For this post, we use the following GitHub sample , which uses Amazon SageMaker Studio with foundation models (Stable Diffusion), prompts, computervision techniques, and a SageMaker endpoint to generate new images from existing images.
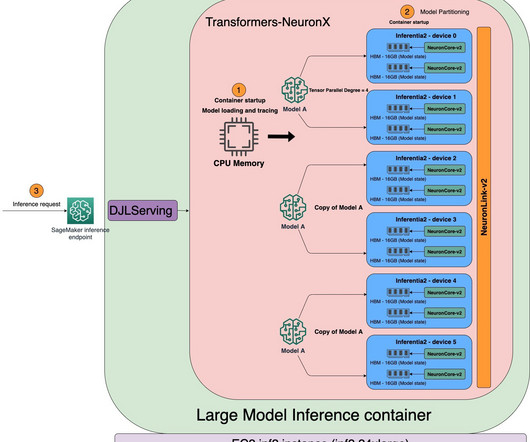
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. These endpoints are fully managed and support auto scaling. When the tracing is complete, the model is partitioned across the NeuronCores based on the tensor parallel degree.
Jump Right To The Downloads Section CycleGAN: Unpaired Image-to-Image Translation (Part 3) In the first tutorial of this series on unpaired image-to-image translation, we introduced the CycleGAN model. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. batch(config.TRAIN_BATCH_SIZE).repeat()
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Always make sure that sensitive data is handled securely to avoid potential security risks.
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. Choose Next.
Model downloading and loading Large language models incur long download times (for example, 40 minutes to download BLOOM-176B). The faster option is to download the model weights into Amazon S3 and then use the LMI container to download them to the container from Amazon S3.
Prerequisites Before getting started, complete the following prerequisites: Create an AWS account or use an existing AWS account. Set up your resources After you complete all the prerequisites, you’re ready to deploy the solution. He is passionate about computervision, NLP, Generative AI and MLOps. medium instance type.
that comply to YOLOv5 with specific requirement on model output, which easily got mess up thru conversion of model from PyTorch > ONNX > Tensorflow > TensorflowJS) ComputerVision Annotation Tool (CVAT) CVAT is build by Intel for doing computervision annotation which put together openCV, OpenVino (to speed up CPU inference).
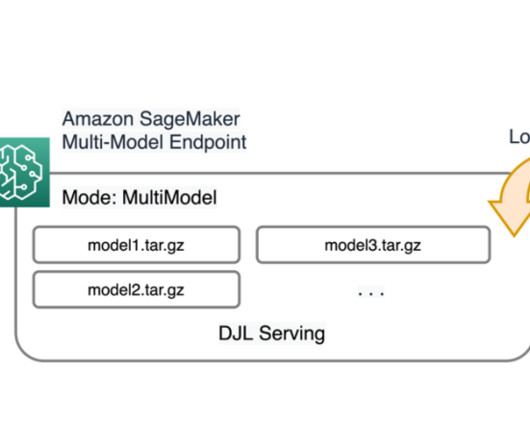
It dynamically downloads models from Amazon S3 to the instance’s storage volume if the invoked model isn’t available on the instance storage volume. SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics.
This tool’s AI-powered auto-detect functionality makes data collecting as simple as point-and-click by automatically recognizing data fields on the majority of websites. For developers seeking a complete and dependable scraping solution, ScrapingBee is the best option, with monthly prices starting at $49 per month.
We selected the model with the most downloads at the time of this writing. Not shown, but to be complete, the R 2 value for the following model deteriorated as well, dropping to a value of 62% from a value of 76% with the VQA features provided. In social media platforms, photos could be auto-tagged for subsequent use.
After you have achieved your desired results with filters and groupings, you can either download your results by choosing Download as CSV or save the report by choosing Save to report library. You can start with a smaller instance and scale out first as your compute demand changes.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Write a response that appropriately completes the request.nn### Instruction:nWhen did Felix Luna die?nn### In this post, we walk through how to fine-tune Llama 2 pre-trained text generation models via SageMaker JumpStart.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The pre-trained models (Llama-2-7b, Llama-2-13b, Llama-2-70b) requires a string prompt and perform text completion on the provided prompt. You can also download the license agreement.
Can you see the complete model lineage with data/models/experiments used downstream? Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. MLOps workflows for computervision and ML teams Use-case-centric annotations.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M Bazel GitHub Metrics A dataset with GitHub download counts of release artifacts from selected bazelbuild repositories. UGIF A multi-lingual, multi-modal UI grounded dataset for step-by-step task completion on the smartphone.
Although this post focuses on LLMs, most of its best practices are relevant for any kind of large-model training, including computervision and multi-modal models, such as Stable Diffusion. This results in faster restarts and workload completion. Cluster update is currently enabled for P and G GPU-based instance types.
But nowadays, it is used for various tasks, ranging from language modeling to computervision and generative AI. This helps in training large AI models, even on computers with little memory. <pre <pre class =" hljs " style =" display : block; overflow-x: auto; padding: 0.5
s2v_most_similar(3) # [(('machine learning', 'NOUN'), 0.8986967), # (('computervision', 'NOUN'), 0.8636297), # (('deep learning', 'NOUN'), 0.8573361)] Evaluating the vectors Word vectors are often evaluated with a mix of small quantitative test sets , and informal qualitative review. from sense2vec import Sense2Vec s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
With this feature, you can closely match your compute resource usage to your actual needs, potentially reducing costs during times of low demand. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
The models can be completely heterogenous, with their own independent serving stack. This includes loading the model from Amazon Simple Storage Service (Amazon S3), for example, database lookups to validate the input, obtaining pre-computed features from the feature store, and so on. ML inference options.
A SageMaker MME dynamically loads models from Amazon Simple Storage Service (Amazon S3) when invoked, instead of downloading all the models when the endpoint is first created. As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency.
This satisfies the strong MME demand for deep neural network (DNN) models that benefit from accelerated compute with GPUs. These include computervision (CV), natural language processing (NLP), and generative AI models. There are two notebooks provided in the repo: one for load testing CV models and another for NLP.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content