This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In computervision (CV), adding tags to identify objects of interest or bounding boxes to locate the objects is called labeling. It’s one of the prerequisite tasks to prepare training data to train a deeplearning model. Active learning is another concept that is closely related to auto-labeling.
Recent advancements in hardware such as Nvidia H100 GPU, have significantly enhanced computational capabilities. With nine times the speed of the Nvidia A100, these GPUs excel in handling deeplearning workloads. Image and Document Processing Multimodal LLMs have completely replaced OCR.
Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g., If you are a regular PyImageSearch reader and have even basic knowledge of DeepLearning in ComputerVision, then this tutorial should be easy to understand. That’s not the case.
MAX_BATCH_PREFILL_TOKENS : This parameter caps the total number of tokens processed during the prefill stage across all batched requests, a phase that is both memory-intensive and compute-bound, thereby optimizing resource utilization and preventing out-of-memory errors. The best performance was observed on ml.p4dn.24xlarge 48xlarge , ml.g6e.12xlarge
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
Furthermore, we define the autotune parameter ( AUTO ) with the help of tf.data.AUTOTUNE on Line 17. Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
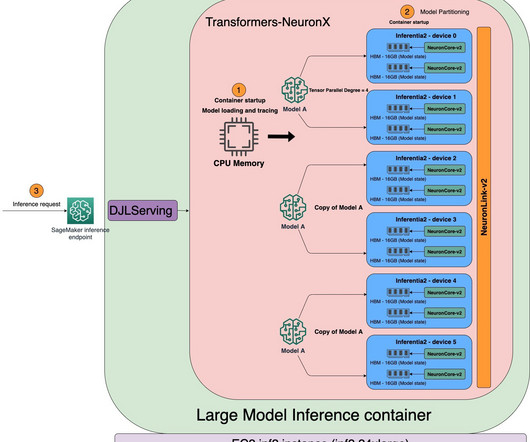
Large language models (LLMs) used to generate text sequences need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity. The goal is to fully use hardware like HBM and accelerators to overcome bottlenecks in memory, I/O, and computation.
In this post, we demonstrate how to deploy Falcon for applications like language understanding and automated writing assistance using large model inference deeplearning containers on SageMaker. SageMaker large model inference (LMI) deeplearning containers (DLCs) can help. code_falcon40b_deepspeed/model.py
of Large Model Inference (LMI) DeepLearning Containers (DLCs). The complete notebook with detailed instructions is available in the GitHub repo. For the TensorRT-LLM container, we use auto. In January 2024, Amazon SageMaker launched a new version (0.26.0) It is returned with the last streamed sequence chunk.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. xlarge instance. She is passionate about innovation and inclusion.
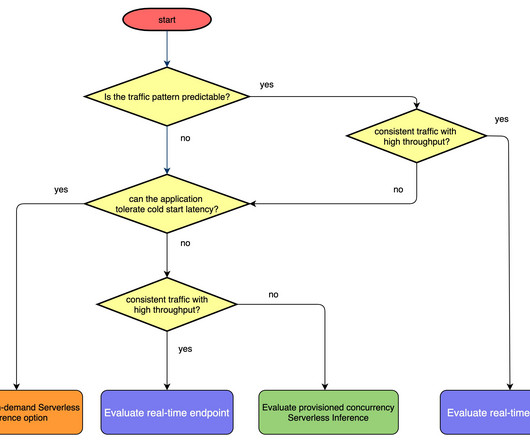
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
You can use ml.trn1 and ml.inf2 compatible AWS DeepLearning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started. For the full list with versions, see Available DeepLearning Containers Images. petaflops of FP16/BF16 compute power.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. The torch.nn
Different Graph neural networks tasks [ Source ] Convolution Neural Networks in the context of computervision can be seen as GNNs that are applied to a grid (or graph) of pixels. There are three different types of learning tasks that are associated with GNN. Want to get the most up-to-date news on all things DeepLearning?
Dive into DeepLearning ( D2L.ai ) is an open-source textbook that makes deeplearning accessible to everyone. When the job is complete, the parallel data status shows as Active and is ready to use. Rachel Hu is an applied scientist at AWS Machine Learning University (MLU).
Einstein has a list of over 60 features, unlocked at different price points and segmented into four main categories: machine learning (ML), natural language processing (NLP), computervision, and automatic speech recognition. LMI containers are a set of high-performance Docker Containers purpose built for LLM inference.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deeplearning analysis. Cool, we learned what NLP is in this section. Our model gets a prompt and auto-completes it. One of these libraries is Hugging Face.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created. It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. amazonaws.com/ :latest Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Download the CloudFormation template kendrablog-sam-template.yml.
Can you see the complete model lineage with data/models/experiments used downstream? Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. MLOps workflows for computervision and ML teams Use-case-centric annotations.
Organizations can easily source data to promote the development, deployment, and scaling of their computervision applications. Viso Suite is the End-to-End, No-Code ComputerVision Platform – Learn more What is Synthetic Data? 1: Variational Auto-Encoder. Get a demo. Technique No.1: Technique No.
However, as the size and complexity of the deeplearning models that power generative AI continue to grow, deployment can be a challenging task. Then, we highlight how Amazon SageMaker large model inference deeplearning containers (LMI DLCs) can help with optimization and deployment.
Furthermore, the CPUUtilization metric shows a classic pattern of periodic high and low CPU demand, which makes this endpoint a good candidate for auto scaling. You can start with a smaller instance and scale out first as your compute demand changes. If all are successful, then the batch transform job is marked as complete.
It is mainly used for deeplearning applications. Provides modularity as a series of completely configurable, independent modules that can be combined with the fewest restrictions possible. It is developed in collaboration with the general public and the Berkeley Vision & Learning Center (BVLC).
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
provides the world’s only end-to-end computervision platform Viso Suite. The solution enables leading companies to build, deploy and scale real-world computervision systems. The vision task of recognizing text from the cropped regions is called Scene Text Recognition (STR). Get a demo here.
ZeRO DeepSpeed is a deeplearning optimization library that aims to make distributed training easy, efficient, and effective. As a managed service with auto scaling, SageMaker makes parallel generation of multiple videos possible using either the same reference image with different reference videos or the reverse.
Although this post focuses on LLMs, most of its best practices are relevant for any kind of large-model training, including computervision and multi-modal models, such as Stable Diffusion. This results in faster restarts and workload completion. The following GitHub repos offer examples with PyTorch and TensorFlow.
About us: At viso.ai, we’ve built the end-to-end machine learning infrastructure for enterprises to scale their computervision applications easily. To learn more about Viso Suite, book a demo. Viso Suite, the end-to-end computervision solution What is Streamlit? What’s Next?
We also help make global conferences accessible to more researchers around the world, for example, by funding 24 students this year to attend DeepLearning Indaba in Tunisia. Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M
The huge progress in AI-enabled by deeplearning enhances robots’ interactions with people in all environments. Some original Tesla features are embedded into the robot, such as a self-running computer, autopilot cameras, a set of AI tools, neural network planning , auto-labeling for objects, etc.
Once the exploratory steps are completed, the cleansed data is subjected to various algorithms like predictive analysis, regression, text mining, recognition patterns, etc depending on the requirements. It is the discounting of those subjects that did not complete the trial. What is deeplearning? What are auto-encoders?
Large language models Large Language Models (LLMs) are huge deep-learning models pre-trained on vast data. But nowadays, it is used for various tasks, ranging from language modeling to computervision and generative AI. This helps in training large AI models, even on computers with little memory. <pre
That’s why the clinic wants to harness the power of deeplearning in a bid to help healthcare professionals in an automated way. Tile embedding Computervision is a complex problem. But it’s not easy to spot the tell-tale signs in scans. A CSV file guides execution.
s2v_most_similar(3) # [(('machine learning', 'NOUN'), 0.8986967), # (('computervision', 'NOUN'), 0.8636297), # (('deeplearning', 'NOUN'), 0.8573361)] Evaluating the vectors Word vectors are often evaluated with a mix of small quantitative test sets , and informal qualitative review. assert doc[3:6].text
“In order to deliver the best flying experience for our passengers and make our internal business process as efficient as possible, we have developed an automated machine learning-based document processing pipeline in AWS. As part of this strategy, they developed an in-house passport analysis model to verify passenger IDs.
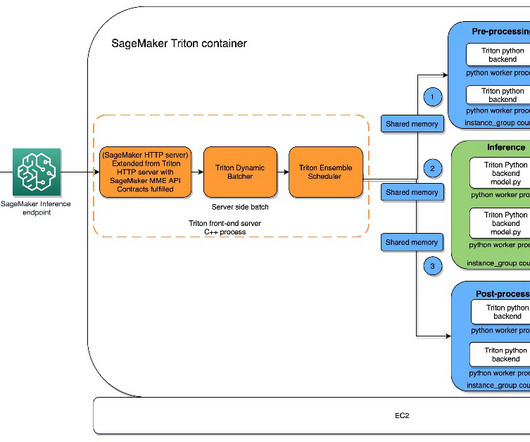
SageMaker MMEs offer capabilities for running multiple deeplearning or ML models on the GPU at the same time with Triton Inference Server, which has been extended to implement the MME API contract. One option supported by SageMaker single and multi-model endpoints is NVIDIA Triton Inference Server.
With this feature, you can closely match your compute resource usage to your actual needs, potentially reducing costs during times of low demand. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content