This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Key features of Katana: Live Inventory Control: Real-time tracking of raw materials and products with auto-booking to allocate stock to orders efficiently.
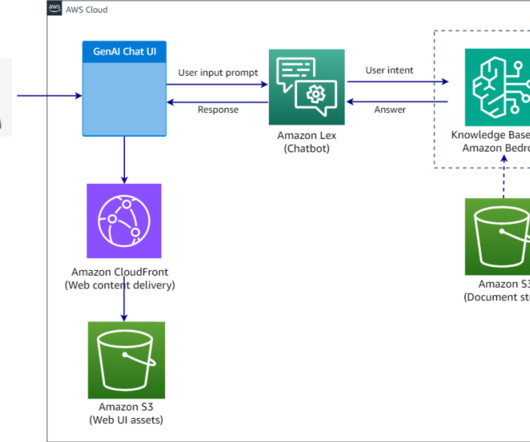
By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Test the knowledge base Once the data sync is complete: Choose the expansion icon to expand the full view of the testing area.
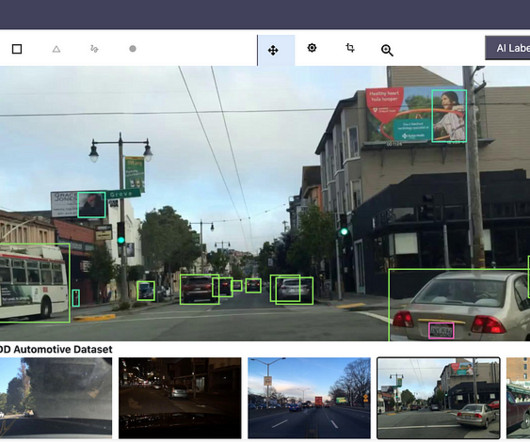
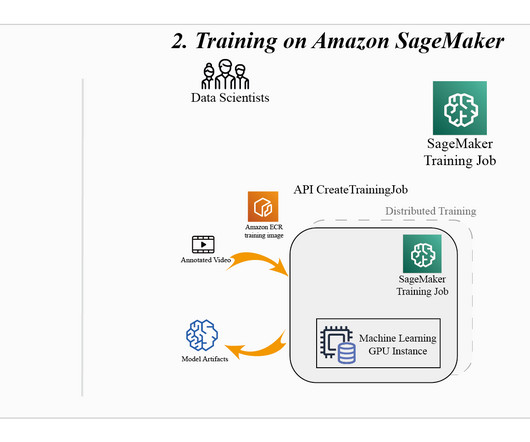
Auto-labeling methods that automatically produce sensor data labels have recently gained more attention. Auto-labeling may provide far bigger datasets at a fraction of the expense of human annotation if its computational cost is less than that of human annotation and the labels it produces are of comparable quality.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
With HouseCanary, agents and investors can instantly obtain a data-driven valuation for any residential property, complete with a confidence score and 3-year appreciation forecast. The platform also provides robust marketing tools like branded video ads, AI-crafted listing flyers, and social media auto-posting.
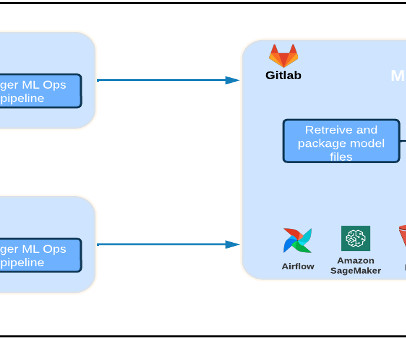
EKS Blueprints helps compose complete EKS clusters that are fully bootstrapped with the operational software that is needed to deploy and operate workloads. Trigger federated training To run federated training, complete the following steps: On the FedML UI, choose Project List in the navigation pane. Choose New Application.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computervision, enabling automated and intelligent data extraction. Image and Document Processing Multimodal LLMs have completely replaced OCR.
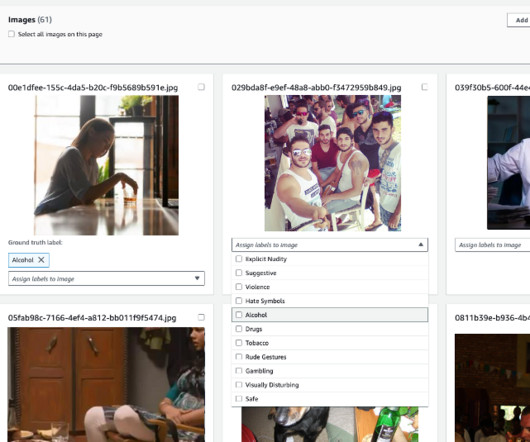
Content moderation in Amazon Rekognition Amazon Rekognition is a managed artificial intelligence (AI) service that offers pre-trained and customizable computervision capabilities to extract information and insights from images and videos. Upload images from your computer and provide labels. Choose Create project.
Image inpainting is one of the classic problems in computervision, and it aims to restore masked regions in an image with plausible and natural content. Despite the advancements, research, and development of these models over the past few years, image inpainting is still a major hurdle for computervision developers.
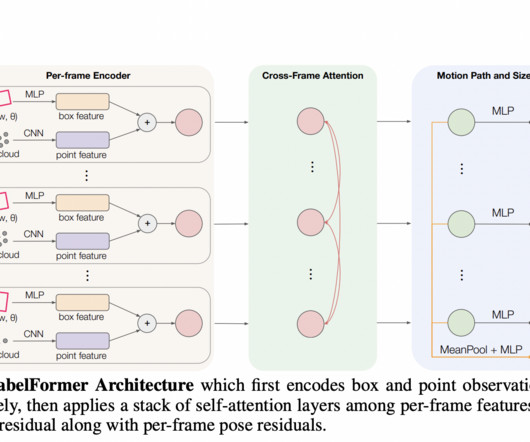
In computervision (CV), adding tags to identify objects of interest or bounding boxes to locate the objects is called labeling. One technique used to solve this problem today is auto-labeling, which is highlighted in the following diagram for a modular functions design for ADAS on AWS.
These models have revolutionized various computervision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
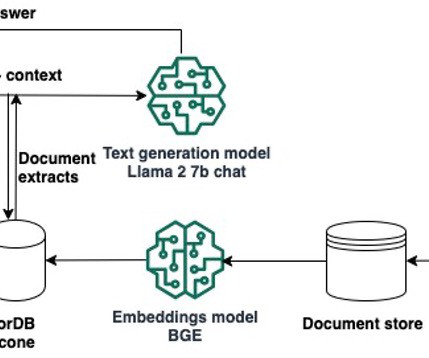
We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat. Llama 2 7b chat is available under the Llama 2 license.
Create a knowledge base To create a new knowledge base in Amazon Bedrock, complete the following steps. For Data source name , Amazon Bedrock prepopulates the auto-generated data source name; however, you can change it to your requirements. You should see a Successfully built message when the build is complete. Choose Next.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
If you are a regular PyImageSearch reader and have even basic knowledge of Deep Learning in ComputerVision, then this tutorial should be easy to understand. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science?
Furthermore, we define the autotune parameter ( AUTO ) with the help of tf.data.AUTOTUNE on Line 17. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery.
Large language models (LLMs) used to generate text sequences need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity. Values include auto , scheduler , and lmi-dist. It improves throughput and doesn’t sacrifice the time to first byte latency.
MAX_BATCH_PREFILL_TOKENS : This parameter caps the total number of tokens processed during the prefill stage across all batched requests, a phase that is both memory-intensive and compute-bound, thereby optimizing resource utilization and preventing out-of-memory errors. The best performance was observed on ml.p4dn.24xlarge 48xlarge , ml.g6e.12xlarge
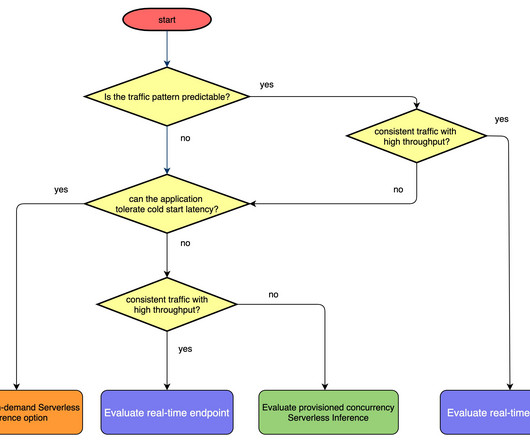
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
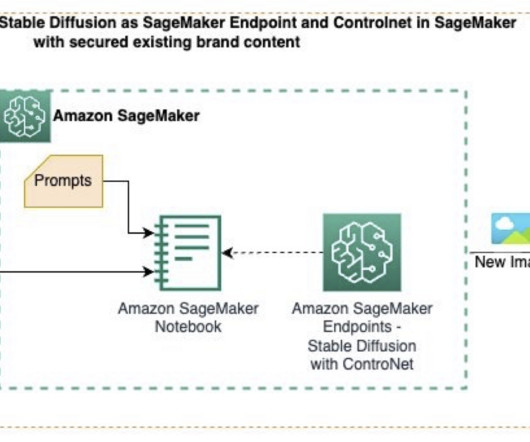
SageMaker endpoints also have auto scaling features and are highly available. For this post, we use the following GitHub sample , which uses Amazon SageMaker Studio with foundation models (Stable Diffusion), prompts, computervision techniques, and a SageMaker endpoint to generate new images from existing images.
Now if you see, it's a complete workflow optimization challenge centered around the ability to execute data-related operations 10x faster. SAM from Meta AI — the chatGPT moment for computervision AI It’s a disruption. Within this data, annotation and its quality is the messiest part of the problem.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime. xlarge instance. You can also run this example on a Studio notebook instance.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
When you create an AWS account, you get a single sign-on (SSO) identity that has complete access to all the AWS services and resources in the account. Signing in to the AWS Management Console using the email address and password that you used to create the account gives you complete access to all the AWS resources in your account.
We orchestrate our ML training and deployment pipelines using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which enables us to focus more on programmatically authoring workflows and pipelines without having to worry about auto scaling or infrastructure maintenance. Sahil Thapar is an Enterprise Solutions Architect.
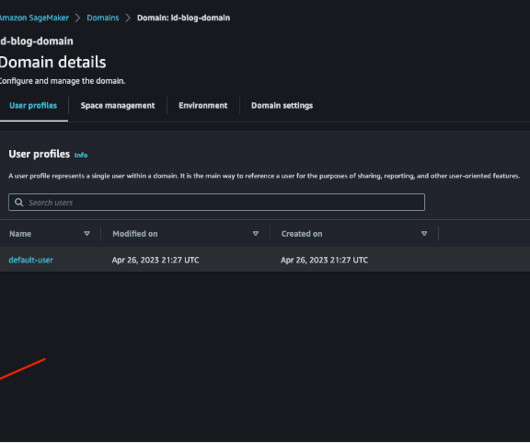
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
To remove an element, omit the text parameter completely. A compact 5-cup single serve coffee maker in matt black with travel mug auto-dispensing feature. - Specify the new content to be generated using one of the following options: To add or replace an element, set the text parameter to a description of the new content.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
It also overcomes complex challenges in speech recognition and computervision, such as creating a transcript of a sound sample or a description of an image. Our model gets a prompt and auto-completes it. NLP doesn’t just deal with written text. Cool, we learned what NLP is in this section.
Einstein has a list of over 60 features, unlocked at different price points and segmented into four main categories: machine learning (ML), natural language processing (NLP), computervision, and automatic speech recognition. Salesforce Apex is a certified framework for building SaaS apps on top of Salesforce’s CRM functionality.
We focused our internal tech on computervision to detect things in images and video (fires, accidents, logos, objects, etc.) Using AI-powered insights, businesses arm themselves with a complete picture of the lead journey, from initial contact to final outcomes, across both digital and offline channels.
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. You can monitor the status of the endpoint by calling DescribeEndpoint , which will tell you when everything is complete. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and ComputerVision.
Set up the environment To deploy a complete infrastructure including networking and a Studio domain, complete the following steps: Clone the GitHub repository. Provide a name for the stack (for example, networking-stack ), and complete the remaining steps to create the stack. something: '1.0'
Prerequisites Before getting started, complete the following prerequisites: Create an AWS account or use an existing AWS account. Set up your resources After you complete all the prerequisites, you’re ready to deploy the solution. He is passionate about computervision, NLP, Generative AI and MLOps. medium instance type.
The output is text generated auto-regressively by PaLM-E, which could be an answer to a question, or a sequence of decisions in text form. To successfully complete the task, PaLM-E produces a plan to find the drawer and open it and then responds to changes in the world by updating its plan as it executes the task.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created. It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5
in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. With that, we’ve completed the training of a variational autoencoder on the Fashion-MNIST dataset. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? The torch.nn
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. amazonaws.com/ :latest Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Download the CloudFormation template kendrablog-sam-template.yml.
You can also edit the auto scaling policy on the Auto-scaling tab on this page. You can see the network, security, and compute information for this endpoint on the Settings tab. Deploy a SageMaker JumpStart LLM To deploy a SageMaker JumpStart LLM, complete the following steps: Navigate to the JumpStart page in SageMaker Studio.
When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. Clean up When the Python script is complete, you can save costs by shutting down or stopping the Amazon SageMaker Studio notebook or container that you spun up. We have packaged this solution in a.ipynb script and.py
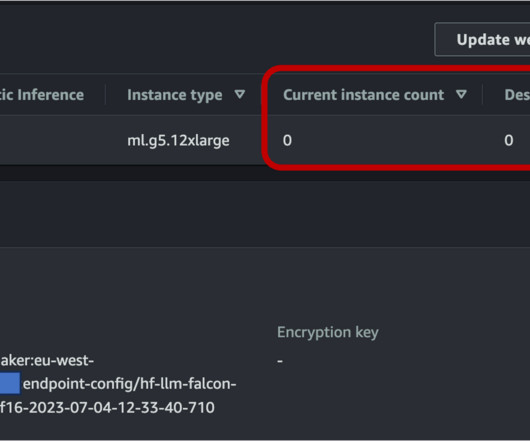
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. Feel free to share your thoughts in the comments.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content