This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Researchers want to create a system that eventually learns to bypass humans completely by completing the research cycle without human involvement. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
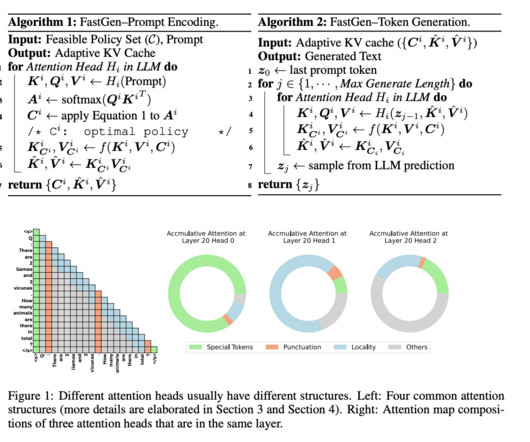
Recently, a technique that adds a token selection task to the original BERT model learns to select performance-crucial tokens and detect unimportant tokens to prune using a designed learnable threshold. It is important to consider pruning tokens’ potential within the KV cache of auto-regressive LLMs to fill this gap.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. Their primary focus is to minimize the need for human intervention in AI task completion.
Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction. These LLMs can perform various NLP operations, including data extraction. LLMs like GPT, BERT, and OPT have harnessed transformers technology.
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
Below, we'll give you the basic know-how you need to understand LLMs, how they work, and the best models in 2023. A large language model (often abbreviated as LLM) is a machine-learning model designed to understand, generate, and interact with human language. What Is a Large Language Model?
Generating configuration management inputs (for CMDB)and changing management inputs based on release notes generated from Agility tool work items completed per release are key Generative AI leverage areas. The ability to generate insights for security validation (from application and platform logs, design points, IAC, etc.)
LangChain is an open-source framework that allows developers to build LLM-based applications easily. It provides for easily connecting LLMs with external data sources to augment the capabilities of these models and achieve better results. It teaches how to build LLM-powered applications using LangChain using hands-on exercises.
In zero-shot learning, no examples of task completion are provided in the model. Chain-of-thought Prompting Chain-of-thought prompting leverages the inherent auto-regressive properties of large language models (LLMs), which excel at predicting the next word in a given sequence.
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. This “making up” event is what we call a hallucination, a term popularized by Andrej Karpathy in 2015 in the context of RNNs and extensively used nowadays for large language models (LLMs). What are LLM hallucinations?
Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time. Pythia: Pythia is a vision and language LLM developed by EleutherAI.
Combined with large language models (LLM) and Contrastive Language-Image Pre-Training (CLIP) trained with a large quantity of multimodality data, visual language models (VLMs) are particularly adept at tasks like image captioning, object detection and segmentation, and visual question answering.
Usually agents will have: Some kind of memory (state) Multiple specialized roles: Planner – to “think” and generate a plan (if steps are not predefined) Executor – to “act” by executing the plan using specific tools Feedback provider – to assess the quality of the execution by means of auto-reflection.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and more.
On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax. 3] provides a more complete survey of Text2SQL data augmentation techniques. different variants of semantic parsing.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Really quickly, LLMs can do many things. Hope you can all hear me well.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Really quickly, LLMs can do many things. Hope you can all hear me well.
Two open-source libraries, Ragas (a library for RAG evaluation) and Auto-Instruct, used Amazon Bedrock to power a framework that evaluates and improves upon RAG. Generating improved instructions for each question-and-answer pair using an automatic prompt engineering technique based on the Auto-Instruct Repository.
It is a family of embedding models with a BERT-like architecture, designed to produce high-quality embeddings from text data. Set up the large language model (LLM) Meta Llama3-70B-Instruct and define a prompt template for generating questions based on the context provided by the document chunks. Choose Create domain.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content