This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. Their primary focus is to minimize the need for human intervention in AI task completion.
This method involves hand-keying information directly into the target system. But these solutions cannot guarantee 100% accurate results. Text Pattern Matching Text pattern matching is a method for identifying and extracting specific information from text using predefined rules or patterns.
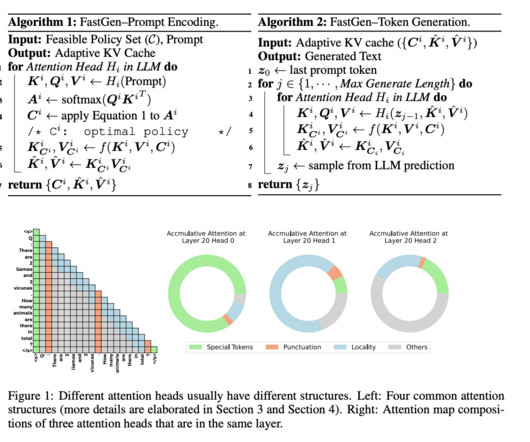
Recently, a technique that adds a token selection task to the original BERT model learns to select performance-crucial tokens and detect unimportant tokens to prune using a designed learnable threshold. It is important to consider pruning tokens’ potential within the KV cache of auto-regressive LLMs to fill this gap.
Engineers train these models on vast amounts of information. It offers a simple API for applying LLMs to up to 100 hours of audio data, even exposing endpoints for common use tasks It's smart enough to auto-generate subtitles, identify speakers, and transcribe audio in real time.
By enhancing their efficiency and safety, we pave the way for innovative applications such as information extraction. In zero-shot learning, no examples of task completion are provided in the model. In this demonstration, we will use the model's ability to understand and summarize complex information from academic texts.
The goodness of such a representation can be evaluated using a principled measure called sparse rate reduction that simultaneously optimizes the intrinsic information gain and extrinsic sparsity of the learned representation. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design.
Their decoder-only model, inspired by NLP giants like BERT, uses a patch-based approach to handle data efficiently. Generating Longer Forecast Output Patches In Large Language Models (LLMs), output is generally produced in an auto-regressive manner, generating one token at a time. However, there is a trade-off.
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources.
An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages. The project was completed in a month and deployed to production after a week of testing. We used GPU jobs that help us run jobs that use an instance’s GPUs.
Deep learning and semantic parsing, do we still care about information extraction? This… github.com Kite AutoComplete For all the Jupyter notebook fans, Kite code autocomplete is now supported! For complete coverage, follow our Twitter: @Quantum_Stat www.quantumstat.com Join thousands of data leaders on the AI newsletter.
In this post, we help you understand the TensorRT backend that is supported by Triton on SageMaker so that you can make an informed decision for your workloads and get great results. With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization.
The Large Language Model (LLM) understands the customer’s intent, extracts key information from their query, and delivers accurate and relevant answers. They can adapt to new industry trends, regulatory changes, and evolving customer needs, providing up-to-date and relevant information.
We can define an AI Agent as a computer program or system that can perceive its environment, process information, and make decisions or take actions to achieve specific goals (such as solving software engineering problems). Simplified Auto-GPT Workflow, Source: own study Extra details For memory, the agent employs a dual approach.
Kernel Auto-tuning : TensorRT automatically selects the best kernel for each operation, optimizing inference for a given GPU. The API constructs a graph representation of the model, making it easier to manage the complex layers involved in LLM architectures like GPT or BERT. build/tensorrt_llm*.whl
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). In such cases, we might not always have a complete sequence we are mapping to/from.
Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and prompt engineering. Self-attention is the mechanism where tokens interact with each other (auto-regressive) and with the knowledge acquired during pre-training. In extreme cases, certain tokens can completely break an LLM.
The best example is OpenAI’s ChatGPT, the well-known chatbot that does everything from content generation and code completion to question answering, just like a human. Even OpenAI’s DALL-E and Google’s BERT have contributed to making significant advances in recent times. What is AutoGPT? per 1,000 tokens for results.
For example, you’ll be able to use the information that certain spans of text are definitely not PERSON entities, without having to provide the complete gold-standard annotations for the given example. spacy-dbpedia-spotlight Use DBpedia Spotlight to link entities ✍️ contextualSpellCheck Contextual spell correction using BERT ?
As an example, getting started with a BERT model for question answering (bert-large-uncased-whole-word-masking-finetuned-squad) is as easy as executing these lines: !pip pip install transformers==4.25.1 pip install transformers==4.25.1 datarobot==3.0.2 the custom.py print("Creating model deployment.") print("Creating model deployment.")
For more information, refer to Knowledge distillation in deep learning and its applications. LLMs are trained on large-scale bodies of text, so they encode a great deal of factual information about the world. For more information, refer to EMNLP: Prompt engineering is the new feature engineering.
For example, access to timely, accurate health information is a significant challenge among women in rural and densely populated urban areas across India. To solve this challenge, ARMMAN developed mMitra , a free mobile service that sends preventive care information to expectant and new mothers.
de_dep_news_trf German bert-base-german-cased 99.0 95.8 - es_dep_news_trf Spanish bert-base-spanish-wwm-cased 98.2 94.4 - zh_core_web_trf Chinese bert-base-chinese 92.5 When you load a config, spaCy checks if the settings are complete and if all values have the correct types. Reproducibility with no hidden defaults.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. For more information about those options and how to choose them, refer to Choose the best data source for your Amazon SageMaker training job.
This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. It synthesizes the information from both the image and prompt encoders to produce accurate segmentation masks. The post Segment Anything Model (SAM) Deep Dive – Complete 2024 Guide appeared first on viso.ai.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. Others, toward language completion and further downstream tasks. So there’s obviously an evolution. Really quickly, LLMs can do many things.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. Others, toward language completion and further downstream tasks. So there’s obviously an evolution. Really quickly, LLMs can do many things.
Patel’s secret: Auto-GPT, a tool that can auto-generate its own prompts that ChatGPT can use to complete a task — without human supervision. Observes Patel: “Instead of spending hours fine-tuning models for different tasks, Auto-GPT uses smart, automated techniques.
The models can be completely heterogenous, with their own independent serving stack. After these business logic steps are complete, the inputs are passed through to ML models. And during idle time, it should be able to turn off compute capacity completely so that you’re not charged. ML inference options. Inference latency.
Figure 1: Representation of the Text2SQL flow As our world is getting more global and dynamic, businesses are more and more dependent on data for making informed, objective and timely decisions. Information might get lost along the way when the requirements are not accurately translated into analytical queries.
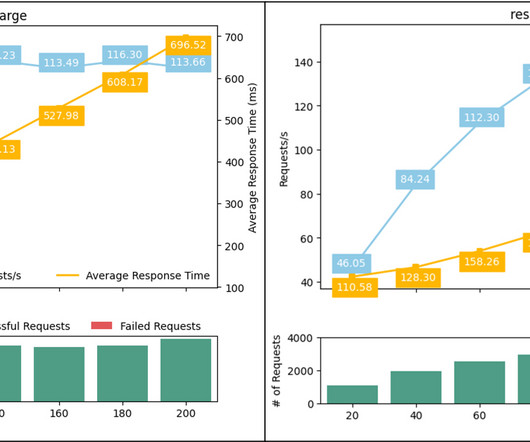
In addition, load testing can help guide the auto scaling strategies using the right metrics rather than iterative trial and error methods. We summarize the insights and conclusion from our test results to help you make an informed decision on configuring your own deployments. The setup of the notebook should look very similar.
Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. A VLM typically consists of three key elements: an image encoder, a text encoder, and a strategy to fuse information from the two encoders. This model achieves a 91.3%
For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information. It is a family of embedding models with a BERT-like architecture, designed to produce high-quality embeddings from text data.
Two open-source libraries, Ragas (a library for RAG evaluation) and Auto-Instruct, used Amazon Bedrock to power a framework that evaluates and improves upon RAG. Generating improved instructions for each question-and-answer pair using an automatic prompt engineering technique based on the Auto-Instruct Repository.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content