This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe.
This advancement has spurred the commercial use of generativeAI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Source: A pipeline on GenerativeAI This figure of a generativeAI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
While attempting to drive acceleration and optimize cost of modernization, GenerativeAI is becoming a critical enabler to drive change in how we accelerate modernization programs. Let us explore the GenerativeAI possibilities across these lifecycle areas. Subsequent phases are build and test and deploy to production.
Also note the completion metrics on the left pane, displaying latency, input/output tokens, and quality scores. When the indexing is complete, select the created index from the index dropdown. The numbers are color-coded to represent two flows: the translation memory ingestion flow (orange) and the text translation flow (gray).
The book covers the inner workings of LLMs and provides sample codes for working with models like GPT-4, BERT, T5, LLaMA, etc. Introduction to GenerativeAI “Introduction to GenerativeAI” covers the fundamentals of generativeAI and how to use it safely and effectively.
It offers a simple API for applying LLMs to up to 100 hours of audio data, even exposing endpoints for common use tasks It's smart enough to auto-generate subtitles, identify speakers, and transcribe audio in real time. Read Introduction to Large Language Models for GenerativeAI. Want to dive deeper?
Zero and Few-Shot Learning: Optimizing with Examples Generative Pretrained Transformers (GPT-3) marked an important turning point in the development of GenerativeAI models, as it introduced the concept of ‘ few-shot learning.' In zero-shot learning, no examples of task completion are provided in the model.
Introduction GenerativeAI is evolving and getting popular. LLMs, the Artificial Intelligence models that are designed to process natural language and generate human-like responses, are trending. Even OpenAI’s DALL-E and Google’s BERT have contributed to making significant advances in recent times.
Usually agents will have: Some kind of memory (state) Multiple specialized roles: Planner – to “think” and generate a plan (if steps are not predefined) Executor – to “act” by executing the plan using specific tools Feedback provider – to assess the quality of the execution by means of auto-reflection.
Sparked by the release of large AI models like AlexaTM , GPT , OpenChatKit , BLOOM , GPT-J , GPT-NeoX , FLAN-T5 , OPT , Stable Diffusion , and ControlNet , the popularity of generativeAI has seen a recent boom. A complete example that illustrates the no-code option can be found in the following notebook.
This is also where I met Lewis Tunstall and as language models with BERT and GPT-2 started taking off we decided to start working on a textbook about transformer models and the Hugging Face ecosystem. data or auto-generated files). cell outputs) for code completion in Jupyter notebooks (see this Jupyter plugin ).
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind.
I am Ali Arsanjani, and I lead partner engineering for Google Cloud, specializing in the area of AI-ML, and I’m very happy to be here today with everyone. It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind.
Patel’s secret: Auto-GPT, a tool that can auto-generate its own prompts that ChatGPT can use to complete a task — without human supervision. Observes Patel: “Instead of spending hours fine-tuning models for different tasks, Auto-GPT uses smart, automated techniques. is a generation older.
Visual language processing (VLP) is at the forefront of generativeAI, driving advancements in multimodal learning that encompasses language intelligence, vision understanding, and processing. Solution overview The proposed VLP solution integrates a suite of state-of-the-art generativeAI modules to yield accurate multimodal outputs.
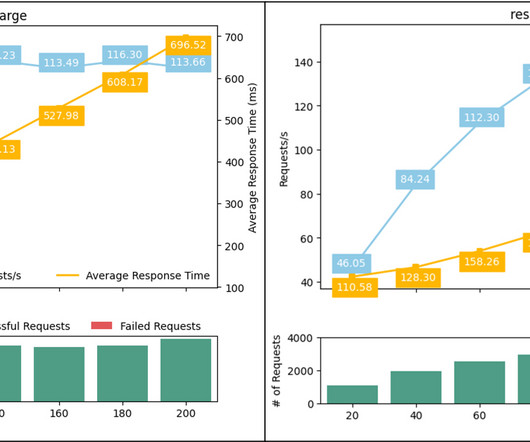
These include computer vision (CV), natural language processing (NLP), and generativeAI models. In addition, load testing can help guide the auto scaling strategies using the right metrics rather than iterative trial and error methods. We tested two NLP models: bert-base-uncased (109M) and roberta-large (335M).
On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax. 3] provides a more complete survey of Text2SQL data augmentation techniques. different variants of semantic parsing.
Two open-source libraries, Ragas (a library for RAG evaluation) and Auto-Instruct, used Amazon Bedrock to power a framework that evaluates and improves upon RAG. Generating improved instructions for each question-and-answer pair using an automatic prompt engineering technique based on the Auto-Instruct Repository.
Solution overview BGE stands for Beijing Academy of Artificial Intelligence (BAAI) General Embeddings. It is a family of embedding models with a BERT-like architecture, designed to produce high-quality embeddings from text data. Auto scaling helps make sure the endpoint can handle varying workloads efficiently.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content