This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
sktime — Python Toolbox for Machine Learning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for Machine Learning with Time Series ,” there! Welcome to sktime, the open community and Python framework for all things time series.
Heres a quick recap of what you learned: Introduction to FastAPI: We explored what makes FastAPI a modern and efficient Python web framework, emphasizing its async capabilities, automatic API documentation, and seamless integration with Pydantic for data validation. By the end, youll have a fully functional API ready for real-world use cases.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). Kite Kite is an AI-driven coding assistant specifically designed to accelerate development in Python and JavaScript.
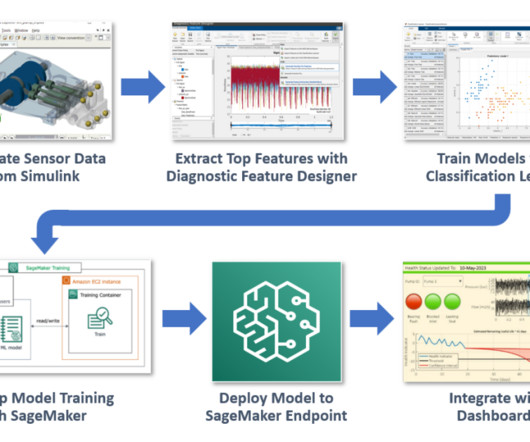
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Verify your python3 installation by running python -V or python --version command on your terminal. Install Python if necessary. We start by training a classifier model on our desktop with MATLAB.
Modules include building neural networks with Keras, computer vision, natural language processing, audio classification, and customizing models with lower-level TensorFlow code. It covers various aspects, from using larger datasets to preventing overfitting and moving beyond binary classification.
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. The pipeline we’re going to talk about now is zero-hit classification.
Auto-Scaling for Dynamic Workloads One of the key benefits of using SageMaker for model deployment is its ability to auto-scale. pip install sagemaker pip install boto3 This Python code snippet demonstrates how to deploy a pre-trained DistilBERT model from Hugging Face onto AWS SageMaker for text classification tasks.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Discover Falcon 2 11B in SageMaker JumpStart You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. We recommend using SageMaker Studio for straightforward deployment and inference.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
Set up the environment and install required packages Install Python 3.8. Set up the Python 3.8 m venv /home/ec2-user/userA/pyenv Activate the Python 3.8 The Qualcomm qaic Python library is a set of APIs that provides support for running inference on the Cloud AI100 accelerator. sudo amazon-linux-extras install python3.8
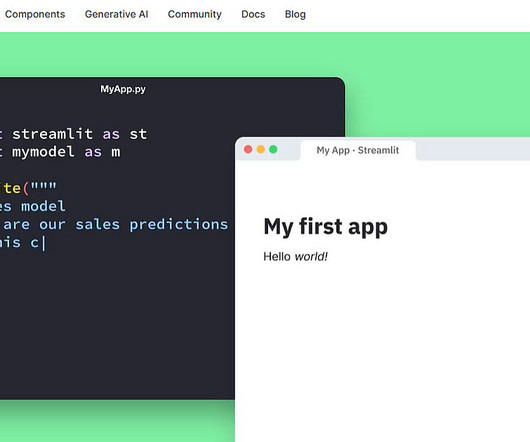
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. So let’s get the buggy war started!
This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. We don’t cover auto scaling in this post specifically, but it’s an important consideration in order to provision the correct number of instances based on the workload.
We train an XGBoost model for a classification task on a credit card fraud dataset. Model Framework XGBoost Model Size 10 MB End-to-End Latency 100 milliseconds Invocations per Second 500 (30,000 per minute) ML Task Binary Classification Input Payload 10 KB We use a synthetically created credit card fraud dataset.
One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. TorchScript is a static subset of Python that captures the structure of a PyTorch model. Triton uses TorchScript for improved performance and flexibility.
Low-Code PyCaret: Let’s start off with a low-code open-source machine learning library in Python. Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. This makes Auto-ViML an ideal tool for beginners and experts alike.
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. For this reason, many DJL users also use it for inference only.
Compute and infrastructure tools offer features such as containerization, orchestration, auto-scaling, and resource management, enabling organizations to efficiently utilize cloud resources, on-premises infrastructure, or hybrid environments for ML workloads. We also save the trained model as an artifact using wandb.save().
If you are prompted to choose a kernel, choose Data Science as the image and Python 3 as the kernel, then choose Select. as the image and Glue Python [PySpark and Ray] as the kernel, then choose Select. For details on model training and inference, refer to the notebook 5-classification-using-feature-groups.ipynb.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on.
Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML. In this case, because we’re training the dataset to predict whether the transaction is fraudulent or valid, we use binary classification. For Training method and algorithms , select Auto.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
It supports languages like Python and R and processes the data with the help of data flow graphs. This framework can perform classification, regression, etc., It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. It is an open source framework. Very difficult to find errors.
Copy Code Copied Use a different Browser import torch from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline import pandas as pd import matplotlib.pyplot as plt Then, we’ll import the required Python libraries. Copy Code Copied Use a different Browser model_id = "ibm-granite/granite-3.0-3b-a800m-instruct"
Comparing Grid Search and Optuna for Hyperparameter Tuning: A Code Analysis As an example, I give python codes to hyper-parameter tuning for the Supper Vector Machine(SVM) model’s parameters. I have the binary classification problem that is why I try to make maximize F1 score. In the dataset, there is a target column which is output.
With one line of Python code, cleanlab allows you to automatically detect common data issues in almost any dataset (image, text, tabular, audio, etc.) Getting Started with Cleanlab Cleanlab is a Python library built specifically for data-centric AI. These techniques help you save limited resources.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. Use the SageMaker model parallel library The SageMaker model parallel library comes with the SageMaker Python SDK.
Streamlit is a Python-based library specifically developed for machine learning engineers. Streamlit is compatible with most Python libraries (e.g., Therefore, you can organize the files and folders as a pure Python project. To learn more about Viso Suite, book a demo. You don’t need front-end (HTML, CSS, JavaScript) experience.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language. Auto-scale compute.
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. Data pipeline for ML feature generation Game logs stored in Athena backed by Amazon S3 go through the ETL pipelines created as Python shell jobs in AWS Glue. Corresponding tables in each phase are created in Athena.
Python is unarguably the most broadly used programming language throughout the data science community. Native Python Support for Snowpark. DataRobot will automatically perform a data quality assessment, determine the problem domain to solve for whether that be binary classification, regression, etc.,
Prerequisites To follow along with this tutorial, make sure you: Use a Google Colab Notebook to follow along Install these Python packages using pip: CometML , PyTorch, TorchVision, Torchmetrics and Numpy, Kaggle %pip install - upgrade comet_ml>=3.10.0 !pip Import the following packages in your notebook.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. Image Classification for Cancer Detection As we all know, cancer is a complex and common disease that affects millions of people worldwide. This architecture is often used for image classification.
The quickstart widget auto-generates a starter config for your specific use case and setup You can use the quickstart widget or the init config command to get started. The config can be loaded as a Python dict. In your custom architectures, you can use Python type hints to tell the config which types of data to expect.
Time series classification : The goal is to predict an action based on past values. Weak stationarity : The mean and the auto-covariance function do not change over time. In Python, we can use the statsmodel library to check for unit roots. 2022) Time Series Analysis with Python Cookbook. References Atwan, T. Auffarth, B.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh This will create one instance of each type.
Simulation of consumption of queue up to drivers estimated position becomes an easy simple algorithm and results in wait time classification. Libraries Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. The Python scientific visualisation landscape is huge.
For text classification, however, there are many similarities. Snorkel Flow’s “Auto-Suggest Key Terms” feature works on any language with “white-space” tokenization. The following image shows an auto-suggestion from a Spanish Sentiment dataset (“ mucha suerte” translates to “good luck”).
This can be performed using an auto-encoder for instance (remember than an auto-encoder is used to learn efficient low dimensional embeddings of some high dimensional space). Safety Checker —classification model that screens outputs for potentially harmful content. Scheduler — essentially ODE integration techniques.
But I have to say that this data is of great quality because we already converted it from messy data into the Python dictionary format that matches our type of work. This is the link [8] to the article about this Zero-Shot Classification NLP. I tried learning how to code the Gradio interface in Python. In the end, it worked.
For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker. For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker.
One way to solve Data Science’s challenges in Data Cleaning and pre-processing is to enable Artificial Intelligence technologies like Augmented Analytics and Auto-feature Engineering. It contains data clustering, classification, anomaly detection and time-series forecasting.
Then you can use the model to perform tasks such as text generation, classification, and translation. If you already run your experiments on the DataRobot GUI, you could even add it as a custom task. Once installed, you can choose a model that suits your needs. writefile $BASE_PATH/custom.py """ Copyright 2021 DataRobot, Inc.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content