This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). Kite Kite is an AI-driven coding assistant specifically designed to accelerate development in Python and JavaScript.
It also delves into NLP with tokenization, embeddings, and RNNs and concludes with deploying models using TensorFlow Lite. Modules include building neural networks with Keras, computer vision, natural language processing, audio classification, and customizing models with lower-level TensorFlow code.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deep learning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Discover Falcon 2 11B in SageMaker JumpStart You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. We recommend using SageMaker Studio for straightforward deployment and inference.
Model category Number of models Examples NLP 157 BERT, BART, FasterTransformer, T5, Z-code MOE Generative AI – NLP 40 LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen Generative AI – Image 3 Stable diffusion v1.5 Set up the environment and install required packages Install Python 3.8. Set up the Python 3.8
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
I came up with an idea of a Natural Language Processing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). This is the link [8] to the article about this Zero-Shot ClassificationNLP. See the attachment below. The approach was proposed by Yin et al.
Sentiment analysis, a widely-used natural language processing (NLP) technique, helps quickly identify the emotions expressed in text. pip install transformers torch accelerate First, we’ll install the essential librariestransformers, torch, and acceleraterequired for loading and running powerful NLP models seamlessly.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. Deep learning (DL) models with more layers and parameters perform better in complex tasks like computer vision and NLP.
While a majority of Natural Language Processing (NLP) models focus on English, the real world requires solutions that work with languages across the globe. In this article, we discuss key Snorkel Flow features and capabilities that help data science and machine learning teams to adapt NLP models to non-English languages.
It’s much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem. And since modern NLP workflows often consist of multiple steps, there’s a new workflow system to help you keep your work organized. See NLP-progress for more results. Flair 2 89.7
Sentiment analysis and other natural language programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources.
For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker. For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M We also continued to release sustainability data via Data Commons and invite others to use it for their research. See some of the datasets and tools we released in 2022 listed below. Pfam-NUniProt2 A set of 6.8
Now you can also fine-tune 7 billion, 13 billion, and 70 billion parameters Llama 2 text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
Classification is very important in machine learning. Hence, we have various classification algorithms in machine learning like logistic regression, support vector machine, decision trees, Naive Bayes classifier, etc. One such classification technique that is near the top of the classification hierarchy is the random forest classifier.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Amazon EKS is a managed Kubernetes service that makes it straightforward to run Kubernetes clusters on AWS.
Bookmark for later Building MLOps Pipeline for NLP: Machine Translation Task [Tutorial] Building MLOps Pipeline for Time Series Prediction [Tutorial] Why do we need a model training pipeline? For example, Scikit-learn, a popular Python library, offers the Pipeline class to streamline preprocessing and model training.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. TGI is implemented in Python and uses the PyTorch framework.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. First, a preprocessing model is applied to the input text tokenization (implemented in Python).
Let's start by understanding why LLM inference is so challenging compared to traditional NLP models. The Inference Challenge with Large Language Models Before the advent of LLMs, natural language processing relied on smaller models focused on specific tasks like text classification, named entity recognition, and sentiment analysis.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













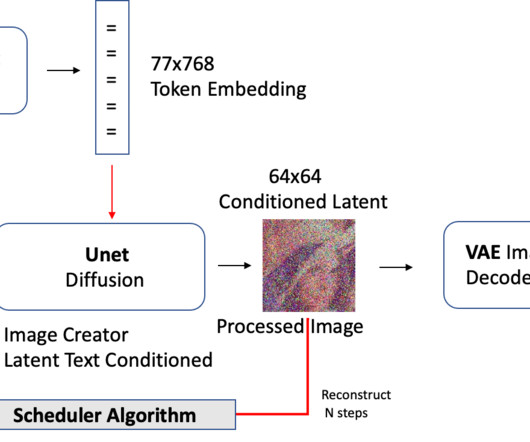









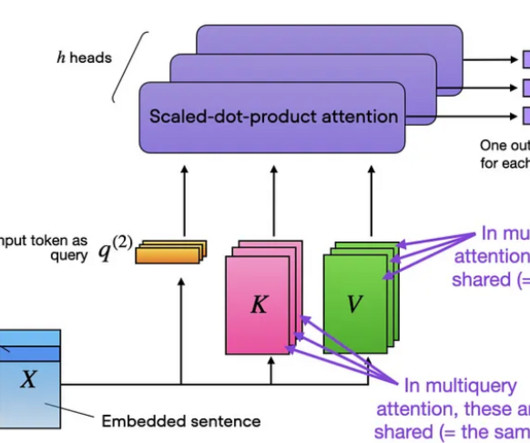






Let's personalize your content