This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learning TensorFlow enables you to create sophisticated neural networks for tasks like image recognition, naturallanguageprocessing, and predictive analytics. It covers various aspects, from using larger datasets to preventing overfitting and moving beyond binary classification.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). Kite Kite is an AI-driven coding assistant specifically designed to accelerate development in Python and JavaScript.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. strip() print(response) The code uses Falcon 2 11B to generate a Python function that writes a JSON file.
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. The pipeline we’re going to talk about now is zero-hit classification.
Deploying Models with AWS SageMaker for HuggingFace Models Harnessing the Power of Pre-trained Models Hugging Face has become a go-to platform for accessing a vast repository of pre-trained machine learning models, covering tasks like naturallanguageprocessing, computer vision, and more. sagemaker: The AWS SageMaker SDK.
With eight Qualcomm AI 100 Standard accelerators and 128 GiB of total accelerator memory, customers can also use DL2q instances to run popular generative AI applications, such as content generation, text summarization, and virtual assistants, as well as classic AI applications for naturallanguageprocessing and computer vision.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and naturallanguageprocessing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. So let’s get the buggy war started!
The DJL is a deep learning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. Our data scientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. For this reason, many DJL users also use it for inference only.
Sentiment analysis, a widely-used naturallanguageprocessing (NLP) technique, helps quickly identify the emotions expressed in text. This compact, instruction-tuned model is optimized to handle tasks like sentiment classification directly within Colab, even under limited computational resources.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
While a majority of NaturalLanguageProcessing (NLP) models focus on English, the real world requires solutions that work with languages across the globe. Labeling data from scratch for every new language would not scale, even if the final architecture remained the same.
The model is trained on the Pile and can perform various tasks in languageprocessing. It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. 24xlarge, or ml.p4de.24xlarge.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh Instead of a data-prep.sh
These developments have allowed researchers to create models that can perform a wide range of naturallanguageprocessing tasks, such as machine translation, summarization, question answering and even dialogue generation. Then you can use the model to perform tasks such as text generation, classification, and translation.
I came up with an idea of a NaturalLanguageProcessing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). This is the link [8] to the article about this Zero-Shot Classification NLP. I tried learning how to code the Gradio interface in Python.
We continued to grow open source datasets in 2022, for example, in naturallanguageprocessing and vision, and expanded our global index of available datasets in Google Dataset Search. Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M
Now you can also fine-tune 7 billion, 13 billion, and 70 billion parameters Llama 2 text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classificationprocess. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. TGI is implemented in Python and uses the PyTorch framework.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
Large language models (LLMs) like GPT-4, LLaMA , and PaLM are pushing the boundaries of what's possible with naturallanguageprocessing. While still computationally intensive, these models could be deployed on modest hardware and followed relatively straightforward inference processes.
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. The second ensemble transforms raw naturallanguage sentences into embeddings and consists of three models.
Most employees don’t master the conventional data science toolkit (SQL, Python, R etc.). To access the desired data, they go via an additional layer where analysts or BI teams “translate” the prose of business questions into the language of data. The manual collection of training data for Text2SQL is particularly tedious. Talk to me!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








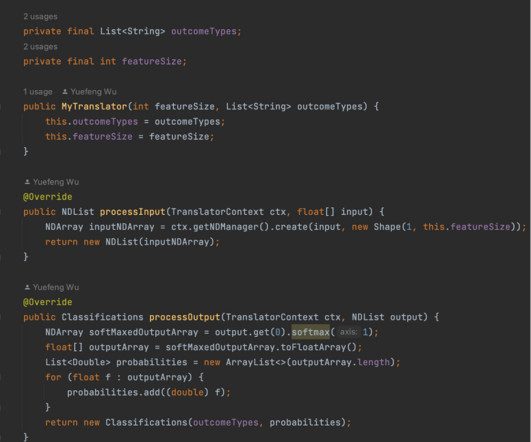












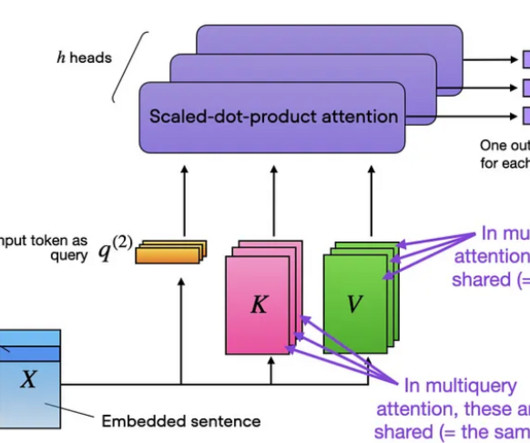








Let's personalize your content