This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Second, the White-Box Preset implements simple interpretable algorithms such as Logistic Regression instead of WoE or Weight of Evidence encoding and discretized features to solve binary classification tasks on tabular data. In the situation where there is a single task with a small dataset, the user can manually specify each feature type.
In the first part of the series, we talked about how Transformer ended the sequence-to-sequence modeling era of NaturalLanguageProcessing and understanding. In this article, we aim to focus on the development of one of the most powerful generative NLP tools, OpenAI’s GPT. Let’s see it step by step. In 2015, Andrew M.
That’s the power of NaturalLanguageProcessing (NLP) at work. In this exploration, we’ll journey deep into some NaturalLanguageProcessing examples , as well as uncover the mechanics of how machines interpret and generate human language. What is NaturalLanguageProcessing?
Learning TensorFlow enables you to create sophisticated neural networks for tasks like image recognition, naturallanguageprocessing, and predictive analytics. It also delves into NLP with tokenization, embeddings, and RNNs and concludes with deploying models using TensorFlow Lite.
NLP models in commercial applications such as text generation systems have experienced great interest among the user. These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera.
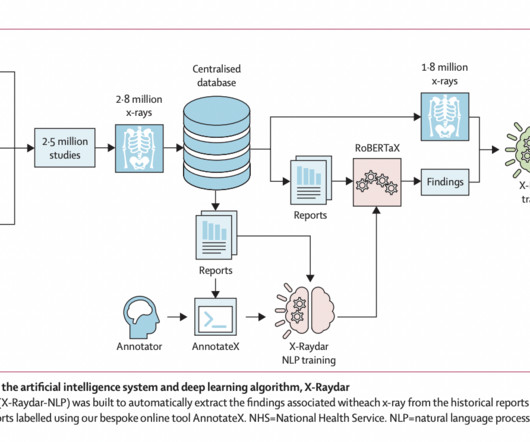
Trained on a dataset from six UK hospitals, the system utilizes neural networks, X-Raydar and X-Raydar-NLP, for classifying common chest X-ray findings from images and their free-text reports. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. Overview of Text Annotation Human language is highly diverse and is sometimes hard to decode for machines. Below are some features of Prodigy: – It is suitable for novice users.
CNNs excel in tasks like object classification, detection, and segmentation, achieving human-level accuracy in diagnosing conditions from radiographs, dermatology images, retinal scans, and more. RNNs are pivotal in this domain because they can process sequential data effectively.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deep learning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
Customers can create the custom metadata using Amazon Comprehend , a natural-languageprocessing (NLP) service managed by AWS to extract insights about the content of documents, and ingest it into Amazon Kendra along with their data into the index. Custom classification is a two-step process.
Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos.
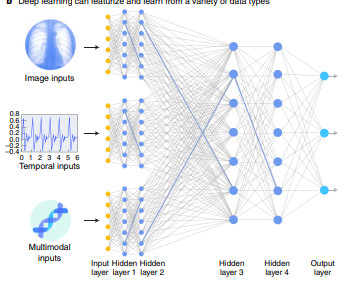
Background of multimodality models Machine learning (ML) models have achieved significant advancements in fields like naturallanguageprocessing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data.
A typical application of GNN is node classification. GNNs are a hybrid of an information diffusion mechanism and neural networks that are used to process data, representing a set of transition functions and a set of output functions. Graph Classification: The goal here is to categorize the entire graph into various categories.
You don’t need to have a PhD to understand the billion parameter language model GPT is a general-purpose naturallanguageprocessing model that revolutionized the landscape of AI. GPT-3 is a autoregressive language model created by OpenAI, released in 2020 . What is GPT-3?
Sentiment analysis, a widely-used naturallanguageprocessing (NLP) technique, helps quickly identify the emotions expressed in text. Transformers provides pre-built NLP models, torch serves as the backend for deep learning tasks, and accelerate ensures efficient resource utilization on GPUs.
I came up with an idea of a NaturalLanguageProcessing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). This is the link [8] to the article about this Zero-Shot ClassificationNLP. See the attachment below.
With eight Qualcomm AI 100 Standard accelerators and 128 GiB of total accelerator memory, customers can also use DL2q instances to run popular generative AI applications, such as content generation, text summarization, and virtual assistants, as well as classic AI applications for naturallanguageprocessing and computer vision.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
The model is trained on the Pile and can perform various tasks in languageprocessing. It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. 24xlarge, or ml.p4de.24xlarge.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). It offers powerful capabilities in naturallanguageprocessing (NLP), machine learning, data analysis, and decision optimization.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. This can be achieved by updating the endpoint’s inference units (IUs).
Lead generation and paperwork approval are two areas with proven solutions, while optical character recognition software is transforming how businesses approach document classification. — ‘Optical… what?’ But ‘What is document classification?’ What Is Document Classification? we hear you ask. And ‘How does it work?’
An IDP pipeline usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. Adjust throughput configurations or use AWS Application Auto Scaling to align resources with demand, enhancing efficiency and cost-effectiveness.
While a majority of NaturalLanguageProcessing (NLP) models focus on English, the real world requires solutions that work with languages across the globe. Labeling data from scratch for every new language would not scale, even if the final architecture remained the same.
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
Sentiment analysis and other naturallanguage programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. She has a technical background in AI and NaturalLanguageProcessing. eks-create.sh
Its creators took inspiration from recent developments in naturallanguageprocessing (NLP) with foundation models. This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. SAM’s game-changing impact lies in its zero-shot inference capabilities.
We continued to grow open source datasets in 2022, for example, in naturallanguageprocessing and vision, and expanded our global index of available datasets in Google Dataset Search. Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M Pfam-NUniProt2 A set of 6.8
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. After it’s fine-tuned on the domain-specific dataset, the model is expected to generate domain-specific text and solve various NLP tasks in that specific domain with few-shot prompting.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classificationprocess. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring.
Large language models (LLMs) like GPT-4, LLaMA , and PaLM are pushing the boundaries of what's possible with naturallanguageprocessing. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. These labels include 1,000 class labels from the ImageNet dataset. !
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content