This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. We train an XGBoost model for a classification task on a credit card fraud dataset. We demonstrate how to set up Inference Recommender jobs for a credit card fraud detection use case.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime.
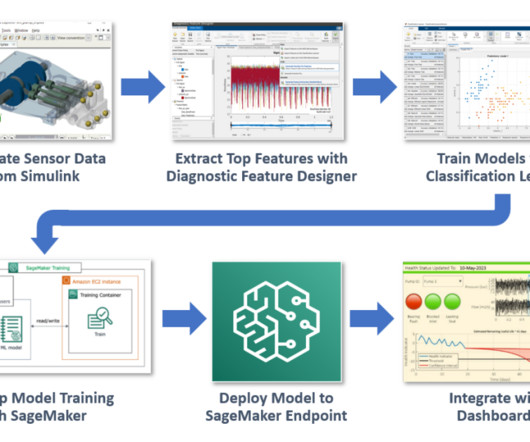
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. Enterprise Solutions Architect at AWS, experienced in SoftwareEngineering, Enterprise Architecture, and AI/ML. Nitin Eusebius is a Sr.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, softwareengineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). Auto Regression is common in more than just Transformers. This is where autoencoding models come into play.
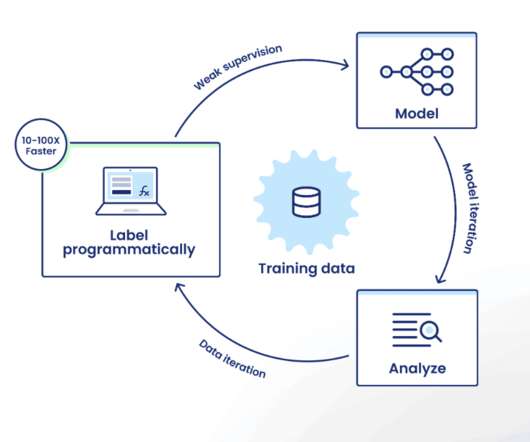
If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this: Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale. Auto-generated tag-based LFs. Streamlined tagging workflows.
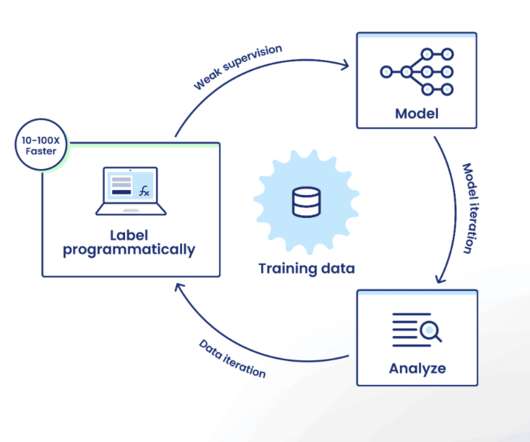
If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this: Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale. Auto-generated tag-based LFs. Streamlined tagging workflows.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computer vision projects. Then we are there to help.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. Nitin Eusebius is a Sr.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content