This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In image classification, DOLPHIN improved baseline models like WideResNet by up to 0.8%, achieving a top-1 accuracy of 82.0%.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
It was in 2014 when ICML organized the first AutoML workshop that AutoML gained the attention of ML developers. A majority of these frameworks implement a general purpose AutoML solution that develops ML-based models automatically across different classes of applications across financial services, healthcare, education, and more.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Auto-encoding representation approaches are also explored, with some researchers utilizing Masked Auto-Encoder (MAE) to learn tactile representations. In object classification tests using the researchers’ real-world dataset, SITR outperforms all baseline models when transferred across different sensors.
In the past few years, Artificial Intelligence (AI) and Machine Learning (ML) have witnessed a meteoric rise in popularity and applications, not only in the industry but also in academia. It’s the major reason why its difficult to build a standard ML architecture for IoT networks.
Leave default settings for VPC , Subnet , and Auto-assign public IP. You can use these services to mount the same models and adapters across multiple instances, facilitating seamless access in environments with auto scaling setups. In Network settings , choose Edit , as shown in the following screenshot.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. We train an XGBoost model for a classification task on a credit card fraud dataset. We demonstrate how to set up Inference Recommender jobs for a credit card fraud detection use case.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. SageMaker provides single model endpoints , which allow you to deploy a single machine learning (ML) model against a logical endpoint.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
Amazon SageMaker is a fully managed machine learning (ML) service providing various tools to build, train, optimize, and deploy ML models. ML insights facilitate decision-making. To assess the risk of credit applications, ML uses various data sources, thereby predicting the risk that a customer will be delinquent.
Based on this classification, it then decides whether to establish boundaries using visual-based shot sequences or audio-based conversation topics. The following example demonstrates a typical chapter-level analysis: [00:00:20;04 00:00:23;01] Automotive, Auto Type The video showcases a vintage urban street scene from the mid-20th century.
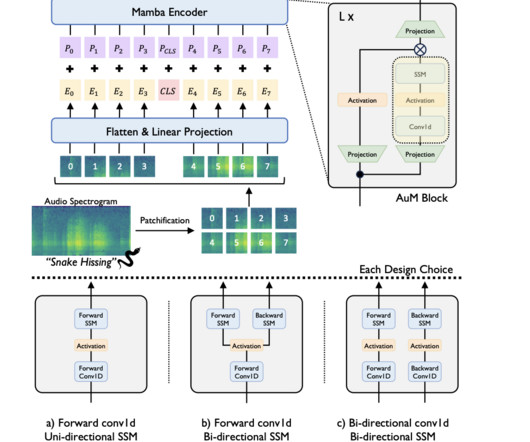
Audio classification has evolved significantly with the adoption of deep learning models. The primary challenge in audio classification is the computational complexity associated with transformers, particularly due to their self-attention mechanism, which scales quadratically with the sequence length.
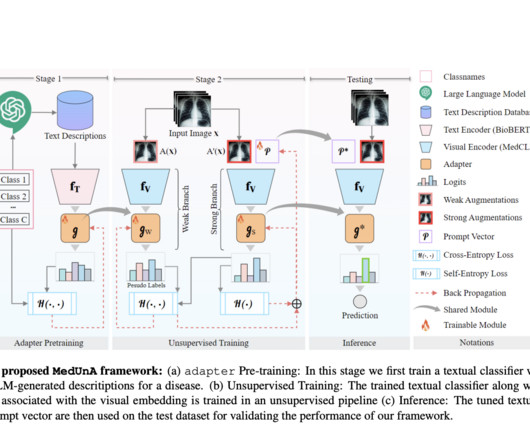
Supervised learning in medical image classification faces challenges due to the scarcity of labeled data, as expert annotations are difficult to obtain. Researchers from Mohamed Bin Zayed University of AI and Inception Institute of AI propose MedUnA, a Medical Unsupervised Adaptation method for image classification.
Businesses are increasingly embracing data-intensive workloads, including high-performance computing, artificial intelligence (AI) and machine learning (ML). This situation triggered an auto-scaling rule set to activate at 80% CPU utilization. Due to the auto-scaling of the new EC2 instances, an additional t2.large
These benefits not only streamline the development process, but also lead to more efficient and effective AI applications, positioning auto-prompting as a promising advancement in the field. He has over 10+ years of academic and industry experience in building and deploying ML and GenAI based solutions for business problems.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. Custom classification is a two-step process.
Whether you’re working on product review classification, AI-driven recommendation systems, or domain-specific search engines, this method allows you to fine-tune large-scale models on a budget efficiently. Dont Forget to join our 75k+ ML SubReddit. Here is the Colab Notebook for the above project.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
The first generation, exemplified by CLIP and ALIGN, expanded on large-scale classification pretraining by utilizing web-scale data without requiring extensive human labeling. These models used caption embeddings obtained from language encoders to broaden the vocabulary for classification and retrieval tasks.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. This can involve containerization with Docker or choosing serverless options, implementing load balancing, setting up auto scaling, and choosing between on-premises, cloud, or hybrid solutions.
Modules include building neural networks with Keras, computer vision, natural language processing, audio classification, and customizing models with lower-level TensorFlow code. It covers various aspects, from using larger datasets to preventing overfitting and moving beyond binary classification.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. We recently developed four more new models.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
For any machine learning (ML) problem, the data scientist begins by working with data. Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it.
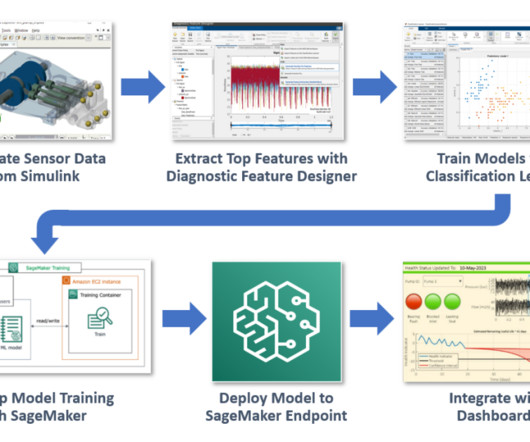
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
A guide to performing end-to-end computer vision projects with PyTorch-Lightning, Comet ML and Gradio Image by Freepik Computer vision is the buzzword at the moment. Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
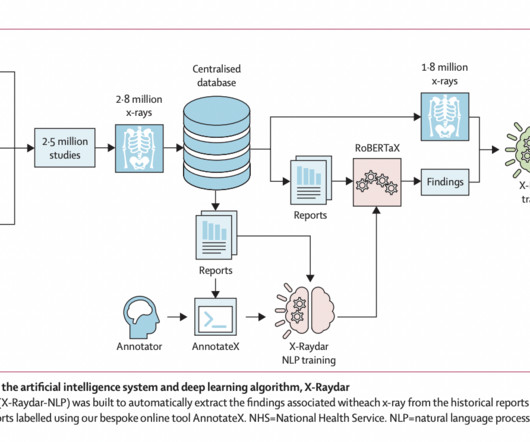
The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test. For testing, a consensus set of 1,427 images annotated by expert radiologists, an auto-labeled set (n=103,328), and an independent dataset, MIMIC-CXR (n=252,374), were employed. Check out the Paper.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of scalable compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are transforming their businesses.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. Legal classification In other legal tasks, such as classification that was measured in accuracy and precision or recall, there’s still room to improve.
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Auto-constructed data lineage : Helps visualize the flow of data through systems without the need for complex hand-coded solutions.
This framework can perform classification, regression, etc., Most of the organizations make use of Caffe in order to deal with computer vision and classification related problems. Theano Theano is one of the fastest and simplest ML libraries, and it was built on top of NumPy. It is an open source framework.
Background of multimodality models Machine learning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data. Outside of work, he enjoys reading and traveling.
” This generated text is stored as metadata, enabling more efficient video classification and facilitating search engine accessibility. Don’t forget to join our 22k+ ML SubReddit , Discord Channel , and Email Newsletter , where we share the latest AI research news, cool AI projects, and more.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Google Research has been at the forefront of this effort, developing many innovations from privacy-safe recommendation systems to scalable solutions for large-scale ML. Structure of auto-bidding online ads system.
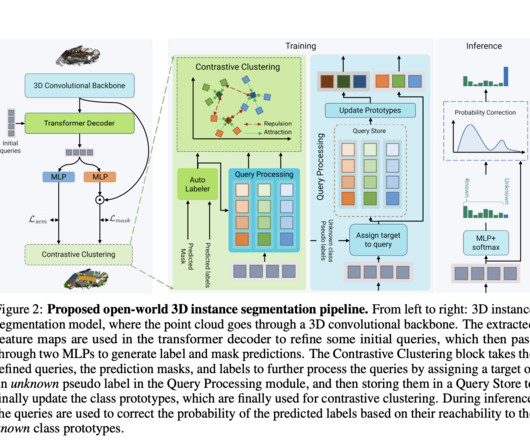
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. They use an auto-labeling approach to distinguish between known and unknowable class labels to produce pseudo-labels during training.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
Rapid, model-guided iteration with New Studio for all core ML tasks. Enhanced studio experience for all core ML tasks. Enhanced new studio experience Snorkel Flow now supports all ML tasks through a single interface via our new Snorkel Flow Studio experience. Programmatic labeling with support for complex tasks and data types.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content