This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
It supports languages like Python and R and processes the data with the help of data flow graphs. This framework can perform classification, regression, etc., It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. It is an open source framework. Very difficult to find errors.
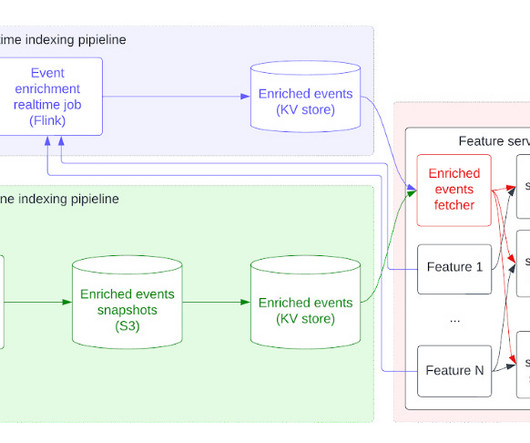
The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. MLengineers no longer need to manage this training metadata separately.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language. Auto-scale compute.
Prerequisites To follow along with this tutorial, make sure you: Use a Google Colab Notebook to follow along Install these Python packages using pip: CometML , PyTorch, TorchVision, Torchmetrics and Numpy, Kaggle %pip install - upgrade comet_ml>=3.10.0 !pip Import the following packages in your notebook.
Simulation of consumption of queue up to drivers estimated position becomes an easy simple algorithm and results in wait time classification. Google built a no-code end to end ML based framework called Visual blocks and published a post on this. The Python scientific visualisation landscape is huge.
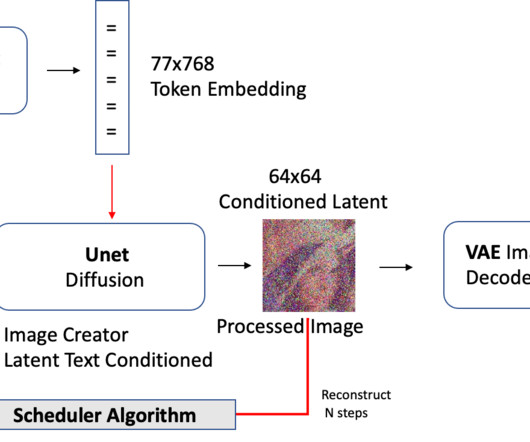
Machine learning (ML) engineers can fine-tune and deploy text-to-semantic-segmentation and in-painting models based on pre-trained CLIPSeq and Stable Diffusion with Amazon SageMaker. For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content