This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). DataRobot DataRobot, founded in 2012, is an AI-powered data science platform designed for building and deploying machinelearning models.
TensorFlow is a powerful open-source framework for building and deploying machinelearning models. Learning TensorFlow enables you to create sophisticated neural networks for tasks like image recognition, natural language processing, and predictive analytics.
NLP models in commercial applications such as text generation systems have experienced great interest among the user. These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera.
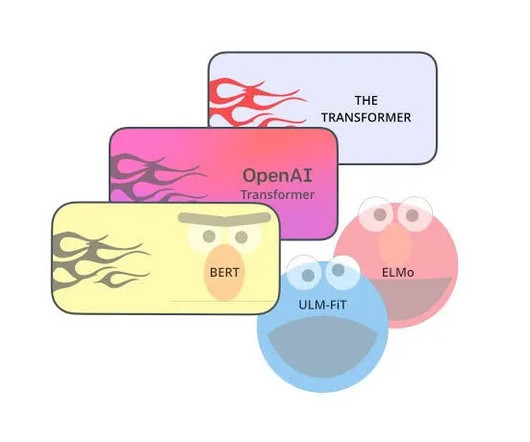
In this article, we aim to focus on the development of one of the most powerful generative NLP tools, OpenAI’s GPT. Evolution of NLP domain after Transformers Before we start, let's take a look at the timeline of the works which brought great advancement in the NLP domain. Let’s see it step by step. In 2015, Andrew M.
MACHINELEARNING | ARTIFICIAL INTELLIGENCE | PROGRAMMING T2E (stands for text to exam) is a vocabulary exam generator based on the context of where that word is being used in the sentence. Data Collection and Cleaning This step is about preparing the dataset to train, test, and validate our machinelearning on.
Customers can create the custom metadata using Amazon Comprehend , a natural-language processing (NLP) service managed by AWS to extract insights about the content of documents, and ingest it into Amazon Kendra along with their data into the index. Custom classification is a two-step process.
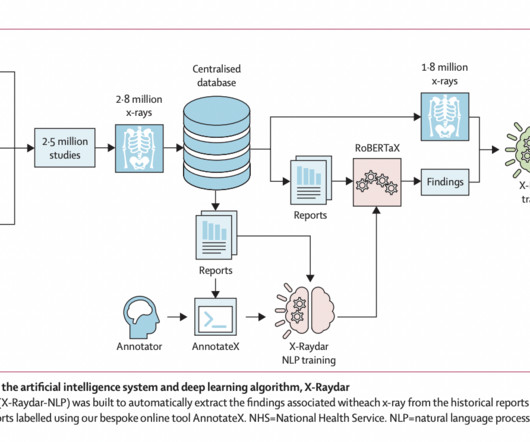
Trained on a dataset from six UK hospitals, the system utilizes neural networks, X-Raydar and X-Raydar-NLP, for classifying common chest X-ray findings from images and their free-text reports. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
Background of multimodality models Machinelearning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data.
In my previous articles about transformers and GPTs, we have done a systematic analysis of the timeline and development of NLP. We have seen how the domain moved from sequence-to-sequence modeling to transformers and soon toward a generalized learning approach.
Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos.
This is what led me back down the rabbit hole, and eventually back to grad school at Stanford, focusing on NLP, which is the area of using ML/AI on natural language. all the “fancy” machinelearning stuff that people in the community did research and published papers on.
A typical application of GNN is node classification. The problems that GNNs are used to solve can be divided into the following categories: Node Classification: The goal of this task is to determine the labeling of samples (represented as nodes) by examining the labels of their immediate neighbors (i.e., their neighbors’ labels).
The Falcon 2 11B model is available on SageMaker JumpStart, a machinelearning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. It uses attention as the learning mechanism to achieve close to human-level performance. 24xlarge, ml.g5.48xlarge, ml.p4d.24xlarge,
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. SageMaker provides single model endpoints , which allow you to deploy a single machinelearning (ML) model against a logical endpoint.
We set this value to max (maximum GPU on the current machine). For the TensorRT-LLM container, we use auto. option.tensor_parallel_degree=max option.max_rolling_batch_size=32 option.rolling_batch=auto option.model_loading_timeout = 7200 We package the serving.properties configuration file in the tar.gz
By using the Framework, you will learn operational and architectural best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud. Adjust throughput configurations or use AWS Application Auto Scaling to align resources with demand, enhancing efficiency and cost-effectiveness.
Lead generation and paperwork approval are two areas with proven solutions, while optical character recognition software is transforming how businesses approach document classification. — ‘Optical… what?’ Optical Character Recognition (OCR, for short) is software that converts images of written or printed text into machine-encoded files.
Model category Number of models Examples NLP 157 BERT, BART, FasterTransformer, T5, Z-code MOE Generative AI – NLP 40 LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen Generative AI – Image 3 Stable diffusion v1.5 The table below highlights the range of the model support.
Almost 90% of the machinelearning models encounter delays and never make it into production. Developing a machinelearning model requires a big amount of training data. Text annotation is important as it makes sure that the machinelearning model accurately perceives and draws insights based on the provided information.
That’s the power of Natural Language Processing (NLP) at work. In this exploration, we’ll journey deep into some Natural Language Processing examples , as well as uncover the mechanics of how machines interpret and generate human language. That’s precisely the challenge NLP tackles.
While a majority of Natural Language Processing (NLP) models focus on English, the real world requires solutions that work with languages across the globe. Performant machinelearning systems need to support this demand. For text classification, however, there are many similarities.
Sentiment analysis, a widely-used natural language processing (NLP) technique, helps quickly identify the emotions expressed in text. pip install transformers torch accelerate First, we’ll install the essential librariestransformers, torch, and acceleraterequired for loading and running powerful NLP models seamlessly.
Typically, benchmarks work by standardizing datasets, specific machine-learning tasks, or certain parts of the machinelearning pipeline for the primary purpose of evaluating the best approach to solve specific problems. Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al.
It’s much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem. And since modern NLP workflows often consist of multiple steps, there’s a new workflow system to help you keep your work organized. See NLP-progress for more results. Flair 2 89.7
Modifying Microsoft Phi 2 LLM for Sequence Classification Task. Transformer-Decoder models have shown to be just as good as Transformer-Encoder models for classification tasks (checkout winning solutions in the kaggle competition: predict the LLM where most winning solutions finetuned Llama/Mistral/Zephyr models for classification).
Sentiment analysis and other natural language programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources.
Machinelearning (ML) engineers can fine-tune and deploy text-to-semantic-segmentation and in-painting models based on pre-trained CLIPSeq and Stable Diffusion with Amazon SageMaker. For information on incorporating autoscaling in your endpoint, see Going Production: Auto-scaling Hugging Face Transformers with Amazon SageMaker.
Smart assistants such as Siri and Alexa, YouTube video recommendations, conversational bots, among others all use some form of NLP similar to GPT-3. With limited input text and supervision, GPT-3 auto-generated a complete essay using conversational language peculiar to humans. I am here to convince you not to worry. Believe me.”.
Its creators took inspiration from recent developments in natural language processing (NLP) with foundation models. This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. SAM’s game-changing impact lies in its zero-shot inference capabilities.
You can easily try out these models and use them with SageMaker JumpStart, which is a machinelearning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M VideoCC A dataset containing (video-URL, caption) pairs for training video-text machinelearning models. We also continued to release sustainability data via Data Commons and invite others to use it for their research.
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. Attention , a central concept in transformers, and how recent work leads to visualizations that are more faithful to its role. --> In the language of Interpretable MachineLearning (IML) literature like Molnar et al.
Also, science projects around technologies like predictive modeling, computer vision, NLP, and several profiles like commercial proof of concepts and competitions workshops. In general, the first thing is to translate this business problem into technical terms, especially machinelearning terms. This is a much harder thing.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machinelearning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science? Explain it’s working.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Amazon EKS is a managed Kubernetes service that makes it straightforward to run Kubernetes clusters on AWS.
We’re about to learn how to create a clean, maintainable, and fully reproducible machinelearning model training pipeline. Bookmark for later Building MLOps Pipeline for NLP: Machine Translation Task [Tutorial] Building MLOps Pipeline for Time Series Prediction [Tutorial] Why do we need a model training pipeline?
Machinelearning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. For example, an image classification use case may use three different models to perform the task. These endpoints are fully managed and support auto scaling.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. These labels include 1,000 class labels from the ImageNet dataset. !
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content