This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Emerging technologies and trends, such as machinelearning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Proactive change management Proactive change management involves the strategies organizations use to manage changes in reference data, master data and metadata.
Machinelearning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. region_name ram_client = boto3.client('ram')
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
MachineLearning Operations (MLOps) is a set of practices and principles that aim to unify the processes of developing, deploying, and maintaining machinelearning models in production environments. Types of MLOps Tools MLOps tools play a pivotal role in every stage of the machinelearning lifecycle.
For any machinelearning (ML) problem, the data scientist begins by working with data. Solution overview Vericast’s MachineLearning Platform aids in the quicker deployment of new business models based on existing workflows or quicker activation of existing models for new clients.
” This generated text is stored as metadata, enabling more efficient video classification and facilitating search engine accessibility. Regarding Flamingo, the YouTube Shorts production team has clarified that the metadata generated by the AI model will not be visible to creators.
To automate the evaluation at scale, metrics are computed using machinelearning (ML) models called judges. Skip the preamble or explanation, and provide the classification. Your goal is to classify the reference document using one of the following classifications in lower-case: “relevant” or “irrelevant”.
Statistical methods and machinelearning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon MachineLearning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machinelearning workflow from data preparation to model deployment. Data preparation The foundation of any machinelearning project is data preparation. The code for this post can be found in the GitHub repo.
This article explores Multimodal Large Language Models, exploring their core functionalities, challenges, and potential for various machine-learning domains. An output could be, e.g., a text, a classification (like “dog” for an image), or an image. However, many tasks span several modalities.
PyTorch is a machinelearning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform.
Defending against adversarial AI requires solutions that are powered by a more sophisticated form of AI, namely, deep learning (DL). Most cybersecurity tools leverage machinelearning (ML) models that present several shortcomings to security teams when it comes to preventing threats. But not all AI is created equal.
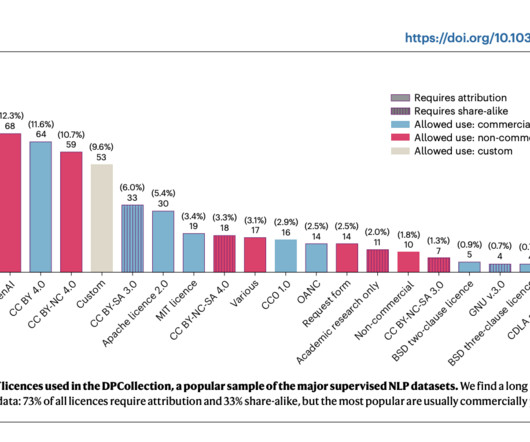
The DPExplorer employs an extensive pipeline to gather and verify metadata from widely used AI datasets. The tool expands on existing metadata repositories like Hugging Face by offering a richer taxonomy of dataset characteristics, including language composition, task type, and text length.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh This will create one instance of each type.
Almost 90% of the machinelearning models encounter delays and never make it into production. Developing a machinelearning model requires a big amount of training data. Text annotation is important as it makes sure that the machinelearning model accurately perceives and draws insights based on the provided information.
MachineLearning Operations (MLOps) vs Large Language Model Operations (LLMOps) LLMOps fall under MLOps (MachineLearning Operations). The following table provides a more detailed comparison: Task MLOps LLMOps Primary focus Developing and deploying machine-learning models. Specifically focused on LLMs.
In general, the first thing is to translate this business problem into technical terms, especially machinelearning terms. What I mean is when discussing how to deal with computer vision projects, in general, machinelearning projects. How many milestones would you typically have in such a process?
The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. Training Convolutional Neural Networks for image classification is time and resource-intensive. Using new_from_file only loads image metadata. Tile embedding Computer vision is a complex problem.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
In cases where the MME receives many invocation requests, and additional instances (or an auto-scaling policy) are in place, SageMaker routes some requests to other instances in the inference cluster to accommodate for the high traffic. These labels include 1,000 class labels from the ImageNet dataset. !
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content