This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
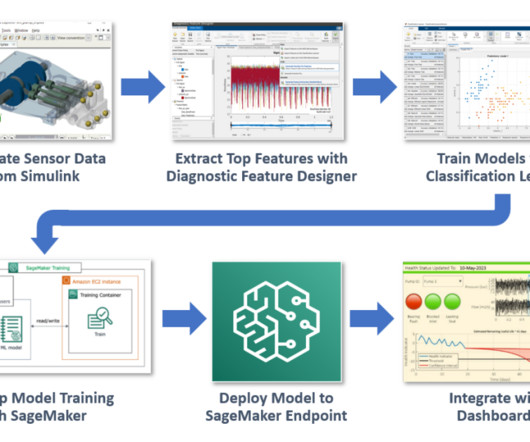
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machinelearning, and artificial intelligence. Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example.
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
At the end of the day, why not use an AutoML package (Automated MachineLearning) or an Auto-Forecasting tool and let it do the job for you? However, we already know that: MachineLearning models deliver better results in terms of accuracy when we are dealing with interrelated series and complex patterns in our data.
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In image classification, DOLPHIN improved baseline models like WideResNet by up to 0.8%, achieving a top-1 accuracy of 82.0%.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). DataRobot DataRobot, founded in 2012, is an AI-powered data science platform designed for building and deploying machinelearning models.
sktime — Python Toolbox for MachineLearning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for MachineLearning with Time Series ,” there! Classification? Annotation? Something else? Forecasting with sktime is simple!
Minor differences in optical design or manufacturing processes can create substantial discrepancies in sensor output, causing machinelearning models trained on one sensor to perform poorly when applied to others. Computer vision models have been widely applied to vision-based tactile images due to their inherently visual nature.
PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation. PAAS offers a wide range of essential services, including more than 40,000 classification guides and more than 500 bulletins. Connect with him on LinkedIn.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. region_name ram_client = boto3.client('ram') Madhubalasri B.
TensorFlow is a powerful open-source framework for building and deploying machinelearning models. Learning TensorFlow enables you to create sophisticated neural networks for tasks like image recognition, natural language processing, and predictive analytics.
Machinelearning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. With a deep passion for Generative AI, MachineLearning, and Serverless technologies, he specializes in helping customers harness these innovations to drive business transformation.
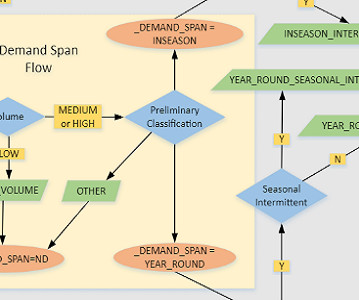
Amazon Kendra is a highly accurate and easy-to-use enterprise search service powered by MachineLearning (AWS). The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Custom classification is a two-step process.
Businesses are increasingly embracing data-intensive workloads, including high-performance computing, artificial intelligence (AI) and machinelearning (ML). This situation triggered an auto-scaling rule set to activate at 80% CPU utilization. Due to the auto-scaling of the new EC2 instances, an additional t2.large
In the past few years, Artificial Intelligence (AI) and MachineLearning (ML) have witnessed a meteoric rise in popularity and applications, not only in the industry but also in academia. Recent research in the field of IoT edge computing has demonstrated the potential to implement MachineLearning techniques in several IoT use cases.
Many organizations are implementing machinelearning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. Because this data is across organizations, we use federated learning to collate the findings. Prachi Kulkarni is a Senior Solutions Architect at AWS.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Armed with these foundational skills, youre now ready to move to the next level: integrating a real-world machinelearning model into a FastAPI application. Whats Next?
MachineLearning Operations (MLOps) is a set of practices and principles that aim to unify the processes of developing, deploying, and maintaining machinelearning models in production environments. Types of MLOps Tools MLOps tools play a pivotal role in every stage of the machinelearning lifecycle.
Introduction Machinelearning is no longer just a buzzword—it’s becoming a key part of how businesses solve problems and make smarter decisions. However, building, training, and deploying machinelearning models can still be daunting, especially when trying to balance performance with cost and scalability.
Emerging technologies and trends, such as machinelearning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Auto-constructed data lineage : Helps visualize the flow of data through systems without the need for complex hand-coded solutions.
Introduction to MachineLearning Frameworks In the present world, almost every organization is making use of machinelearning and artificial intelligence in order to stay ahead of the competition. So, let us see the most popular and best machinelearning frameworks and their uses.
For any machinelearning (ML) problem, the data scientist begins by working with data. Solution overview Vericast’s MachineLearning Platform aids in the quicker deployment of new business models based on existing workflows or quicker activation of existing models for new clients.
Purina used artificial intelligence (AI) and machinelearning (ML) to automate animal breed detection at scale. Generating this data can take months to gather and requires a large effort to label it for use in machinelearning. Outside of work, he loves spending time with his family, hiking, and playing soccer.
Background of multimodality models Machinelearning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data. Outside of work, he enjoys reading and traveling.
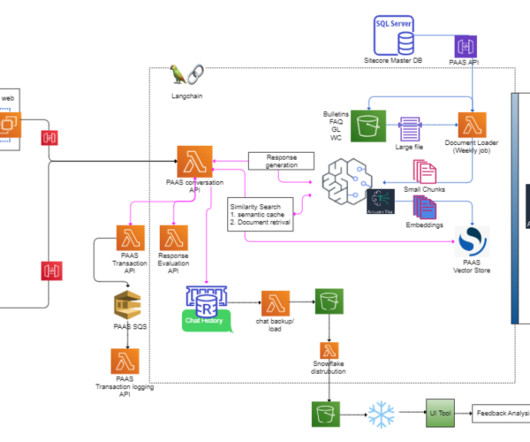
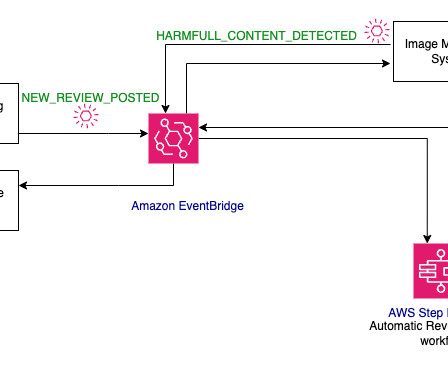
These techniques utilize various machinelearning (ML) based approaches. Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. The following diagram shows our solution architecture.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
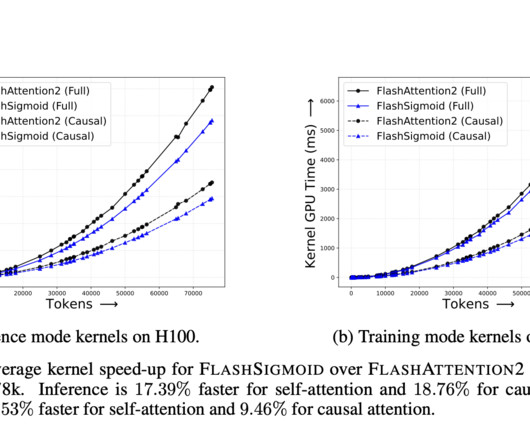
Large Language Models (LLMs) have gained significant prominence in modern machinelearning, largely due to the attention mechanism. Recent research in machinelearning has explored alternatives to the traditional softmax function in various domains.
Like all AI, generative AI works by using machinelearning models—very large models that are pretrained on vast amounts of data called foundation models (FMs). LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction.
The Falcon 2 11B model is available on SageMaker JumpStart, a machinelearning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
MACHINELEARNING | ARTIFICIAL INTELLIGENCE | PROGRAMMING T2E (stands for text to exam) is a vocabulary exam generator based on the context of where that word is being used in the sentence. Data Collection and Cleaning This step is about preparing the dataset to train, test, and validate our machinelearning on.
A typical application of GNN is node classification. The problems that GNNs are used to solve can be divided into the following categories: Node Classification: The goal of this task is to determine the labeling of samples (represented as nodes) by examining the labels of their immediate neighbors (i.e., their neighbors’ labels).
Photo by Ian Taylor on Unsplash This article will comprehensively create, deploy, and execute machinelearning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machinelearning workflow. Yes, they do, but partially.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
For Problem type , select Classification. In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. For Training method , select Auto. Complete the following steps: Choose Run Data quality and insights report.
Low-Code PyCaret: Let’s start off with a low-code open-source machinelearning library in Python. PyCaret allows data professionals to build and deploy machinelearning models easily and efficiently. Well, one of its main advantages is that PyCaret reduces the amount of code required to build a machinelearning model.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. SageMaker provides single model endpoints , which allow you to deploy a single machinelearning (ML) model against a logical endpoint.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machinelearning (AI/ML) in its professional information products for decades. He helps support large enterprise customers at AWS and is part of the MachineLearning TFC.
Although machinelearning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
PyTorch is a machinelearning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS.
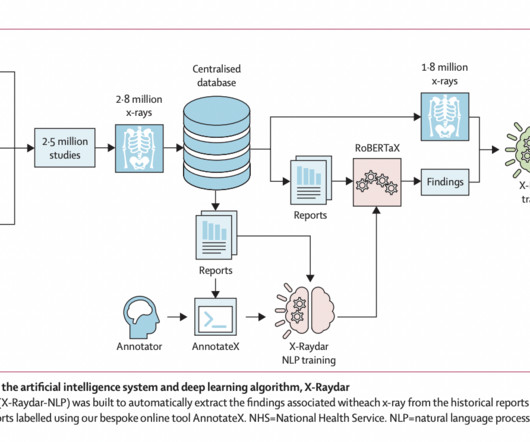
The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test. For testing, a consensus set of 1,427 images annotated by expert radiologists, an auto-labeled set (n=103,328), and an independent dataset, MIMIC-CXR (n=252,374), were employed.
One reason for rephrasing a regression problem into a classification problem could be that the user wants to focus on a specific price range and requires a model that can predict this range with high accuracy. Labeling The dataset contains continuous prices that are converted into categories with respect to the provided thresholds.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content