This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In image classification, DOLPHIN improved baseline models like WideResNet by up to 0.8%, achieving a top-1 accuracy of 82.0%.
There also now exist incredibly capable LLMs that can be used to ingest accurately recognized speech and generate summaries, insights, takeaways, and classifications that are enabling entirely new products and workflows to be created with voice data for the first time ever.
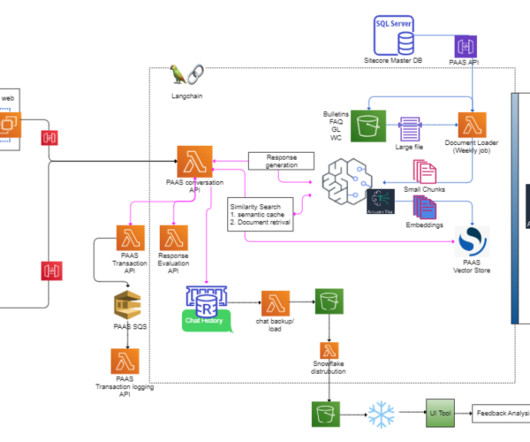
PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation. PAAS offers a wide range of essential services, including more than 40,000 classification guides and more than 500 bulletins. Verisk developed an evaluation tool to enhance response quality.
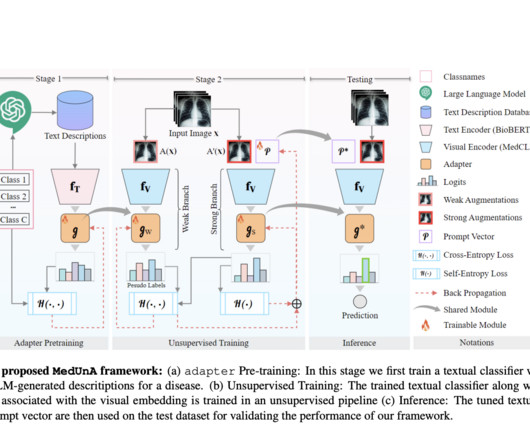
Supervised learning in medical image classification faces challenges due to the scarcity of labeled data, as expert annotations are difficult to obtain. Researchers from Mohamed Bin Zayed University of AI and Inception Institute of AI propose MedUnA, a Medical Unsupervised Adaptation method for image classification.
How do multimodal LLMs work? A typical multimodal LLM has three primary modules: The input module comprises specialized neural networks for each specific data type that output intermediate embeddings. An output could be, e.g., a text, a classification (like “dog” for an image), or an image.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. Custom classification is a two-step process.
Transformers form the backbone of the revolutionary Large Language Models While LLMs like GPT4 , llama2 & Falcon seem to do an excellent jobs across a variety of tasks, the performance of an LLM on a particular task is a direct result of the underlying architecture. These models are best suited for language translation.
LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction. FMs and LLMs, even though they’re pre-trained, can continue to learn from data inputs or prompts during inference. send the LLM generated response to a human reviewer.
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. Create a question embedding.
The model consists of two key components: a location-aware image tokenizer and an LLM-based decoder. An LLM-based decoder is utilized to extract vision and text features for discriminative tasks and auto-regressively generate response tokens in generative tasks. million common and rare concepts in the real world and has 132.2
Hallucinations – LLMs have a remarkable ability to respond to natural language, and clearly encode significant amounts of knowledge. An LLM doesn’t model facts so much as it models language. Scaling language model training with Amazon SageMaker HyperPod Thomson Reuters knew that training LLMs would require significant computing power.
This talk explores how RAG LLMs power specialized AI agents for Auto Bodily Injury, Workers Compensation, and General Liability claims, handling identity verification, intent classification, document processing, fraud detection, and claim negotiation with high accuracy.
It allows LLMs to reference authoritative knowledge bases or internal repositories before generating responses, producing output tailored to specific domains or contexts while providing relevance, accuracy, and efficiency. Generation is the process of generating the final response from the LLM.
These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera. Storage capacity With parameters ranging from millions to billions, LLM can pose storage capacity challenges. For instance, a 1.5B
Context window extension techniques Rotary Positional Embedding (RoPE)-based context scaling is now available on the LMI-Dist, vLLM, and TensorRT-LLM backends. Be mindful that LLM token probabilities are generally overconfident without calibration. TensorRT-LLM requires models to be compiled into efficient engines before deployment.
This post showcases a reward modeling technique to efficiently customize LLMs for an organization by programmatically defining rewards functions that capture preferences for model behavior. We demonstrate an approach to deliver LLM results tailored to an organization without intensive, continual human judgement.
Modifying Microsoft Phi 2 LLM for Sequence Classification Task. Training using LoRA and QLoRA approaches using Huggingface trainer Microsoft’s Phi-2 LLM is a 2.7 Phi-2, currently doesn’t have sequence classification support on HuggingFace AutoModel APIs.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Similarly, you can deploy the Falcon 2 11B LLM using its own model ID.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al. The authors in this study develop a task-agnostic approach for improving LLM reasoning abilities without task-specific training (e.g. fine-tuning).
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al. The authors in this study develop a task-agnostic approach for improving LLM reasoning abilities without task-specific training (e.g. fine-tuning).
You can surely train a simple classifier on a system with 8 GB RAM and no GPU device, but it would not be prudent to train an LLM model on the same infrastructure. It checks data and model quality, data drift, target drift, and regression and classification performance. We also save the trained model as an artifact using wandb.save().
For more complex issues like label errors, you can again simply filter out all the auto-detected bad data. For instance, when fine-tuning various LLM models on a text classification task (politeness prediction), this auto-filtering improves LLM performance without any change in the modeling code!
Along with text generation it can also be used to text classification and text summarization. The auto-complete feature on your smartphone is based on this principle. When you type “how”, the auto-complete will suggest words like “to” or “are”.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. This is especially helpful for classification across many classes, where users tend to write more LFs. Intelligent Auto-Suggest Strategies for Labeling Functions You can now target specific error hotspots using slice-based suggestions.
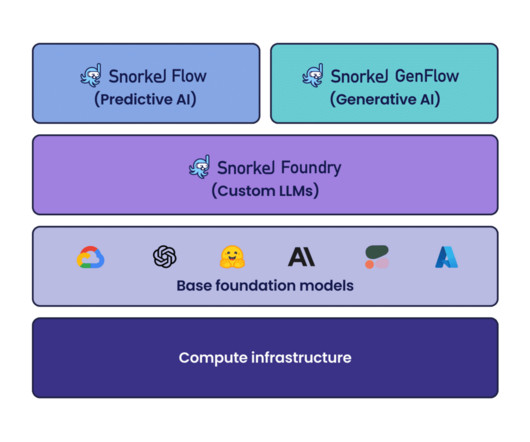
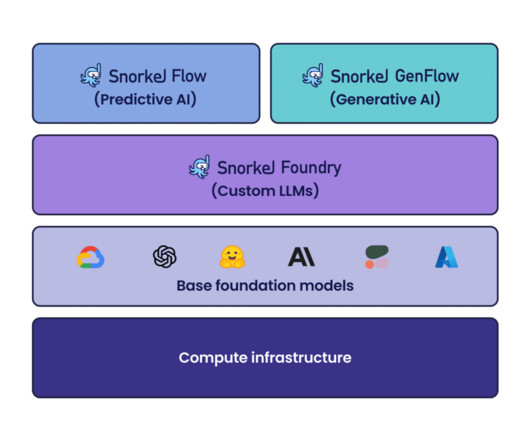
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Alongside Snorkel GenFlow, we also announced Snorkel Foundry for programmatically sampling, filtering, cleaning, and augmenting proprietary data for domain-specific pre-training of Large Language Models (LLM).
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Alongside Snorkel GenFlow, we also announced Snorkel Foundry for programmatically sampling, filtering, cleaning, and augmenting proprietary data for domain-specific pre-training of Large Language Models (LLM).
Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. The platform provides a comprehensive set of annotation tools, including object detection, segmentation, and classification.
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. They can operate in various modes that employ combinations of LLMs, human inputs, and tools. It simplifies the orchestration, automation, and optimization of a complex LLM workflow.
Simulation of consumption of queue up to drivers estimated position becomes an easy simple algorithm and results in wait time classification. Libraries Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. They refer to this as our “demand” model.
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. Prompt-response management: Refining LLM-backed applications through continuous prompt-response optimization and quality control.
In your application, take time to imagine the diverse set of questions available in your images to help your classification or regression task. In social media platforms, photos could be auto-tagged for subsequent use. The enhanced data contains new data features relative to this example use case.
Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time. Pythia: Pythia is a vision and language LLM developed by EleutherAI.
Recently, I discovered a Python package called Outlines, which provides a versatile way to leverage Large Language Models (LLMs) for tasks like: Classification Named Entity Extraction Generate synthetic data Summarize a document … And… Play Chess (there are also 5 other uses). First, what is sampling in an LLM?
The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from data preparation to training and deployment. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
Combined with large language models (LLM) and Contrastive Language-Image Pre-Training (CLIP) trained with a large quantity of multimodality data, visual language models (VLMs) are particularly adept at tasks like image captioning, object detection and segmentation, and visual question answering.
In this technical deep dive, we'll explore cutting-edge techniques for accelerating LLM inference, enabling faster response times, higher throughput, and more efficient utilization of hardware resources. Let's start by understanding why LLM inference is so challenging compared to traditional NLP models.
For example, input images for an object detection use case might need to be resized or cropped before being served to a computer vision model, or tokenization of text inputs before being used in an LLM. However, If the instance’s storage volume reaches its capacity, SageMaker will delete the unused models from the storage volume.
Here are some other open-source large language models (LLMs) that are revolutionizing conversational AI. LLaMA Release date : February 24, 2023 LLaMa is a foundational LLM developed by Meta AI. Dolly Release date: March 8, 2023 Dolly is an instruction-following LLM developed by Databricks.
For instance, a financial firm that needs to auto-generate a daily activity report for internal circulation using all the relevant transactions can customize the model with proprietary data, which will include past reports, so that the FM learns how these reports should read and what data was used to generate them.
It not only requires SQL mastery on the part of the annotator, but also more time per example than more general linguistic tasks such as sentiment analysis and text classification. 4] In the open-source camp, initial attempts at solving the Text2SQL puzzle were focussed on auto-encoding models such as BERT, which excel at NLU tasks.[5,
Set up the large language model (LLM) Meta Llama3-70B-Instruct and define a prompt template for generating questions based on the context provided by the document chunks. Use the LLM to generate synthetic question answer pairs for each document chunk. Auto scaling helps make sure the endpoint can handle varying workloads efficiently.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















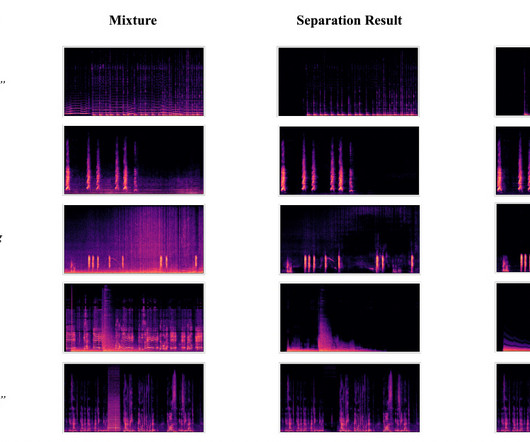
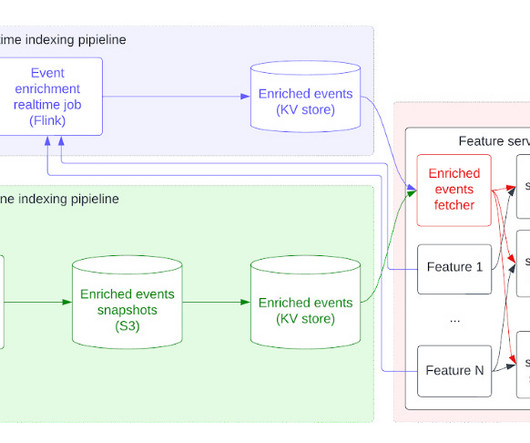






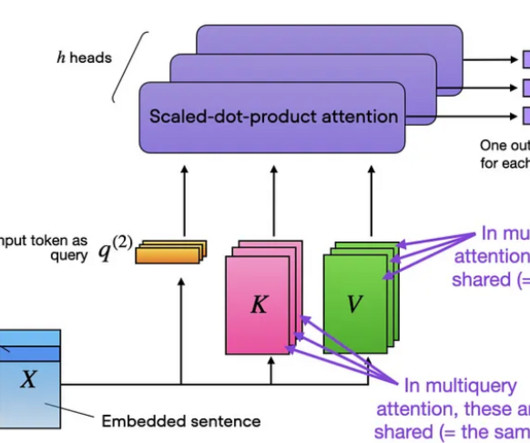











Let's personalize your content