This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
In the past few years, Artificial Intelligence (AI) and Machine Learning (ML) have witnessed a meteoric rise in popularity and applications, not only in the industry but also in academia. It’s the major reason why its difficult to build a standard ML architecture for IoT networks.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. We train an XGBoost model for a classification task on a credit card fraud dataset. We demonstrate how to set up Inference Recommender jobs for a credit card fraud detection use case.
Businesses are increasingly embracing data-intensive workloads, including high-performance computing, artificial intelligence (AI) and machine learning (ML). The carbon assessment technique that it uses aligns with greenhouse gas (GHG) principles for the information and communication technology sector.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use advanced parsing options supported by Amazon Bedrock Knowledge Bases for parsing non-textual information from documents using FMs.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. SageMaker provides single model endpoints , which allow you to deploy a single machine learning (ML) model against a logical endpoint.
Everything is data—digital messages, emails, customer information, contracts, presentations, sensor data—virtually anything humans interact with can be converted into data, analyzed for insights or transformed into a product. They should also have access to relevant information about how data is collected, stored and used.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
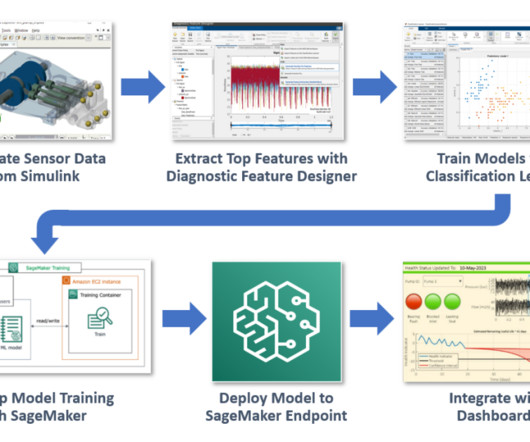
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning. We Made It! What's next?
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
By translating images into text, we unlock and harness the wealth of information contained in visual data. Similarly, it can assist in generating automatic photo descriptions, providing information that might not be included in product titles or descriptions, thereby improving user experience.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. We recently developed four more new models.
For any machine learning (ML) problem, the data scientist begins by working with data. Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
However, when building generative AI applications, you can use an alternative solution that allows for the dynamic incorporation of external knowledge and allows you to control the information used for generation without the need to fine-tune your existing foundational model. license, for use without restrictions.
Another challenge is the need for an effective mechanism to handle cases where no useful information can be retrieved for a given input. Consequently, you may face difficulties in making informed choices when selecting the most appropriate RAG approach that aligns with your unique use case requirements.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. For Problem type , select Classification. Then we train, build, test, and deploy the model using SageMaker Canvas, without writing any code. Choose Create.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. They are professionals with discerning information needs in legal, corporate, tax, risk, fraud, compliance, and news domains. 55 440 0.1
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
One key issue is the tendency of the softmax function to concentrate attention on a limited number of features, potentially overlooking other informative aspects of the input data. However, despite its widespread adoption and effectiveness, SoftmaxAttn faces several challenges. If you like our work, you will love our newsletter.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deep learning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. Like other AI and ML models, our model trains on data.
Complex, information-seeking tasks. Transform modalities, or translate the world’s information into any language. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. All kinds of tasks.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. For more information, refer to How Amazon CloudWatch works. Auto scaling.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Integrate Human Oversight for Process Effectiveness Although automation and ML algorithms significantly advance the efficiency of IDP, there are scenarios where human reviewers can augment and enhance the outcomes, especially in situations with regulatory demands or when encountering low-quality scans.
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python. This makes Auto-ViML an ideal tool for beginners and experts alike.
Photo by Scott Webb on Unsplash Determining the value of housing is a classic example of using machine learning (ML). A significant influence was made by Harrison and Rubinfeld (1978), who published a groundbreaking paper and dataset that became known informally as the Boston housing dataset. b64encode(bytearray(image)).decode()
For more information about all common and backend-specific deployment configuration parameters, see Large Model Inference Configurations. For more information about the related configurations, refer to TensorRT-LLM. For more information on sharding strategies, see Grouped-query attention (GQA) support.
In this post, I’ll give a high-level overview of how AI/ML can be used to automatically detect various issues common in real-world datasets. These techniques are based on years of research from my team, investigating what sorts of data problems can be detected algorithmically using information from a trained model.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. However, lack of labeled training data bottlenecked their progress.
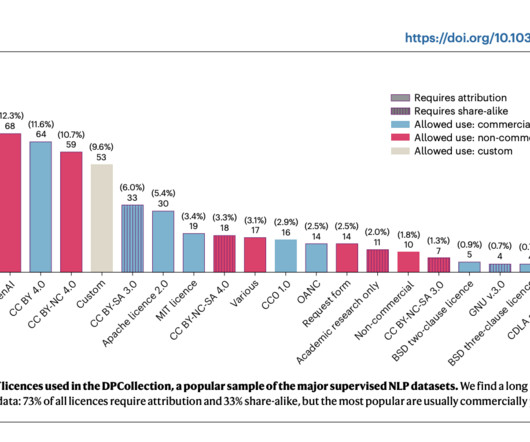
Many datasets, especially those used for fine-tuning AI models, come from sources that do not provide clear licensing information. Moreover, these issues raise ethical concerns regarding the use of data, particularly when it contains personal or sensitive information. Also, don’t forget to follow us on Twitter and LinkedIn.
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). Auto Regression is common in more than just Transformers. This is where autoencoding models come into play.
For more information, see Amazon EC2 pricing. He has over 20 years of experience in product strategy and development, with the current focus of best-in-class performance and performance/$ end-to-end solutions for AI inference in the Cloud, for the broad range of use-cases, including GenAI, LLMs, Auto and Hybrid AI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content