This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There is a tremendous amount of information embedded within human speech. We founded AssemblyAI with the vision of creating superhuman Speech AI models that would unlock an entirely new class of AI applications to be built leveraging voice data. Think of all the knowledge that exists within a company's virtual meetings, for example.
Verisks Premium Audit Advisory Service (PAAS) is the leading source of technical information and training for premium auditors and underwriters. PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation.
The GelSight sensor and its variants have emerged as influential tactile technologies, providing detailed information about contact surfaces by transforming tactile data into visual images. Auto-encoding representation approaches are also explored, with some researchers utilizing Masked Auto-Encoder (MAE) to learn tactile representations.
As carbon emissions reporting becomes common worldwide, IBM is committed to assisting its clients in making informed decisions that can help address their energy demands and associated carbon impact while reducing costs. This situation triggered an auto-scaling rule set to activate at 80% CPU utilization.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
In an effort to track its advancement towards creating Artificial Intelligence (AI) that can surpass human performance, OpenAI has launched a new classification system. Level 5: Organizations The highest ranking level in OpenAI’s classification is Level 5, or “Organisations.”
Everything is data—digital messages, emails, customer information, contracts, presentations, sensor data—virtually anything humans interact with can be converted into data, analyzed for insights or transformed into a product. They should also have access to relevant information about how data is collected, stored and used.
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? After implementing our changes, the demand classification pipeline reduces the overall error in our forecasting process by approx. 21% compared to the Auto-Forecasting one — quite impressive!
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning. We Made It! What's next?
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
It quickly pulls from disparate data sources with integrated data, enabling faster and more informed decision making. By drawing from various foundation models, generative AI uses powerful transformers to generate content from unstructured information. Security and compliance are broad domains that vary across industries.
Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application. Googles PaLM-E additionally handles information about a robots state and surroundings. The output module generates outputs based on the task and the processed information.
Each node is a structure that contains information such as a person's id, name, gender, location, and other attributes. The information about the connections in a graph is usually represented by adjacency matrices (or sometimes adjacency lists). A typical application of GNN is node classification. their neighbors’ labels).
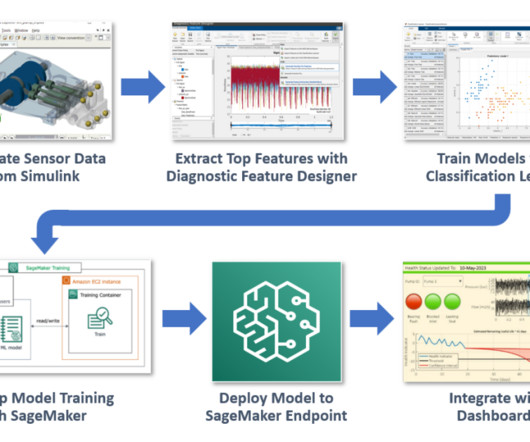
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
However, the sharing of raw, non-sanitized sensitive information across different locations poses significant security and privacy risks, especially in regulated industries such as healthcare. Insecure networks lacking access control and encryption can still expose sensitive information to attackers.
Furthermore, it was observed that when the developers used the interpolation augmentation method, there was a drop in model’s accuracy during quantization, but at the same time, there was also a boost in model’s inference speed, and classification generalization.
Another challenge is the need for an effective mechanism to handle cases where no useful information can be retrieved for a given input. Consequently, you may face difficulties in making informed choices when selecting the most appropriate RAG approach that aligns with your unique use case requirements.
Like humans, AVs rely on various sensor technologies to perceive the environment and make logical decisions based on the gathered information. A CNN is a neural network with one or more convolutional layers and is used mainly for image processing, classification, segmentation, and other auto-correlated data. Yann LeCun et al.,
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. API Gateway calls the Lambda function to obtain the pet attributes.
However, when building generative AI applications, you can use an alternative solution that allows for the dynamic incorporation of external knowledge and allows you to control the information used for generation without the need to fine-tune your existing foundational model. license, for use without restrictions.
Auto-Scaling for Dynamic Workloads One of the key benefits of using SageMaker for model deployment is its ability to auto-scale. pip install sagemaker pip install boto3 This Python code snippet demonstrates how to deploy a pre-trained DistilBERT model from Hugging Face onto AWS SageMaker for text classification tasks.
By translating images into text, we unlock and harness the wealth of information contained in visual data. Similarly, it can assist in generating automatic photo descriptions, providing information that might not be included in product titles or descriptions, thereby improving user experience.
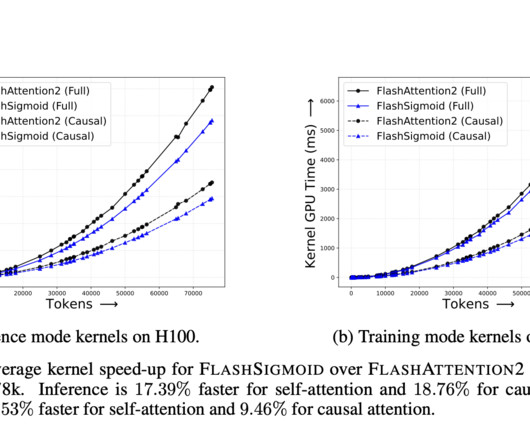
One key issue is the tendency of the softmax function to concentrate attention on a limited number of features, potentially overlooking other informative aspects of the input data. However, despite its widespread adoption and effectiveness, SoftmaxAttn faces several challenges.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
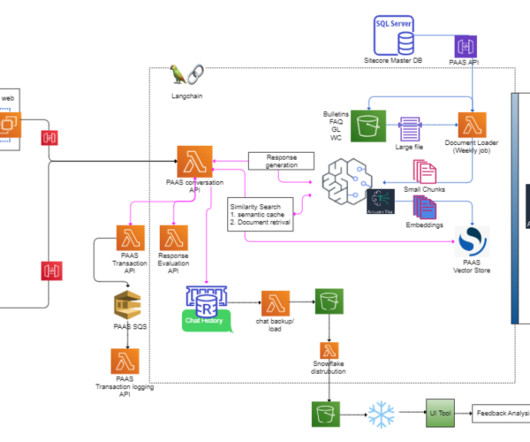
Figure 1: Representation of the Text2SQL flow As our world is getting more global and dynamic, businesses are more and more dependent on data for making informed, objective and timely decisions. Information might get lost along the way when the requirements are not accurately translated into analytical queries.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. They are professionals with discerning information needs in legal, corporate, tax, risk, fraud, compliance, and news domains. 55 440 0.1
But from an ML standpoint, both can be construed as binary classification models, and therefore could share many common steps from an ML workflow perspective, including model tuning and training, evaluation, interpretability, deployment, and inference. The final outcome is an auto scaling, robust, and dynamically monitored solution.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. One of the most popular models available today is XGBoost.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction. A prompt is the information you pass into an LLM to elicit a response. For most reviews, the system auto-generates a reply using an LLM.
For Problem type , select Classification. For more information, see AWS managed policy: AmazonSageMakerCanvasAIServicesAccess. For more information, see Model access. For more information about ready-to-use models provided by SageMaker Canvas, see Use Ready-to-use models. For Training method , select Auto.
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. Note that although the MMS configurations don’t apply in this case, the policy considerations still do.)
Complex, information-seeking tasks. Transform modalities, or translate the world’s information into any language. Additionally, language models of sufficient scale have the ability to learn and adapt to new information and tasks, which makes them even more versatile and powerful. All kinds of tasks.
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python. This makes Auto-ViML an ideal tool for beginners and experts alike.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling. Inference latency.
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. Step 1: We highlight the points from different articles to make a set of useful information.
The Snorkel AI team will present 18 research papers and talks at the 2023 Neural Information Processing Systems (NeurIPS) conference from December 10-16. Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. For more information, refer to How Amazon CloudWatch works. Auto scaling. Depending on your traffic patterns, you can attach an auto scaling policy to your SageMaker endpoint.
Even though OpenAssistant is still in the developmental stage, it has already acquired several skills, such as interacting with external systems like Google Search to gather information. Based on the transformer architecture, Vicuna is an auto-regressive language model and offers natural and engaging conversation capabilities.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content