This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
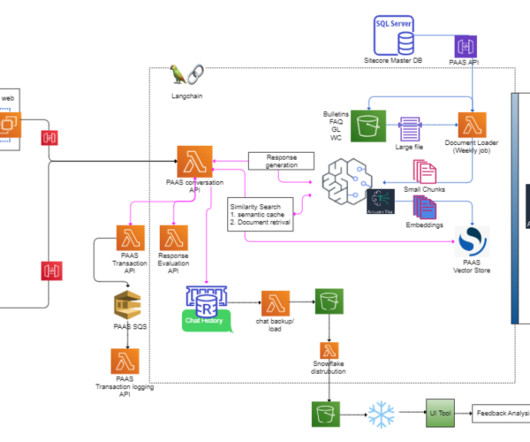
PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation. PAAS offers a wide range of essential services, including more than 40,000 classification guides and more than 500 bulletins.
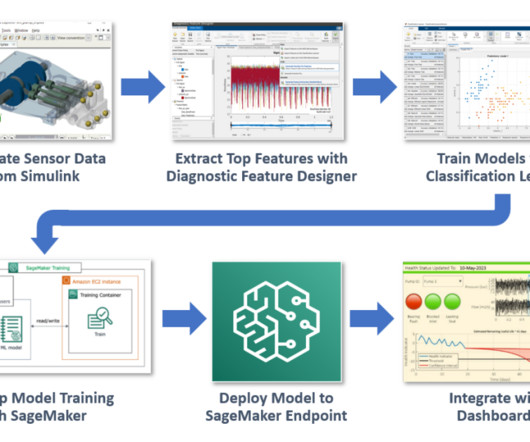
Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example. Here, you use Auto Features , which quickly extracts a broad set of time and frequency domain features from the dataset and ranks the top candidates for model training. classifierModel = fitctree(.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. Let me explain. Our model gets a prompt and auto-completes it.
Researchers still do great work in model-centric AI, but off-the-shelf models and auto ML techniques have improved so much that model choice has become commoditized at production time. This leads to more transparent and explainable AI, equipping enterprises to manage bias and deliver responsible outcomes.
An output could be, e.g., a text, a classification (like “dog” for an image), or an image. It can perform visual dialogue, visual explanation, visual question answering, image captioning, math equations, OCR, and zero-shot image classification with and without descriptions. Basic structure of a multimodal LLM.
Relative performance results of three GNN variants ( GCN , APPNP , FiLM ) across 50,000 distinct node classification datasets in GraphWorld. Structure of auto-bidding online ads system. We find that academic GNN benchmark datasets exist in regions where model rankings do not change.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. We don’t cover auto scaling in this post specifically, but it’s an important consideration in order to provision the correct number of instances based on the workload.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. We explain the metrics and show techniques to deal with data to obtain better model performance.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. Watch this and many other sessions on-demand at future.snorkel.ai.
Modifying Microsoft Phi 2 LLM for Sequence Classification Task. Transformer-Decoder models have shown to be just as good as Transformer-Encoder models for classification tasks (checkout winning solutions in the kaggle competition: predict the LLM where most winning solutions finetuned Llama/Mistral/Zephyr models for classification).
Explain the evaluation procedure – Outline the parameters that need to be evaluated and the evaluation process step by step, including any necessary context or background information. Skip the preamble or explanation, and provide the classification. Skip any preamble or explanation, and provide the classification.
In this article, we’ll focus on this concept: explaining the term and sharing an example of how we’ve used the technology at DLabs.AI. let’s first explain basic Robotic Process Automation. And our innovative tool now auto-classifies over 83% of all invoices , significantly reducing the manual overhead of accounting teams.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
Along with text generation it can also be used to text classification and text summarization. The auto-complete feature on your smartphone is based on this principle. When you type “how”, the auto-complete will suggest words like “to” or “are”. That’s the precise difference between GPT-3 and its predecessors.
For Problem type , select Classification. In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. For Training method , select Auto. Complete the following steps: Choose Run Data quality and insights report.
For this example, we only use binary classification—does this bag contain a firearm or not? Auto-generated activation maps improve explainability by illustrating which areas of an image are most important for a model’s predictions (similar to feature impact on other models). identifying multiple objects in an X-ray) predictions.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
We’ll walk through the data preparation process, explain the configuration of the time series forecasting model, detail the inference process, and highlight key aspects of the project. Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. Image Classification for Cancer Detection As we all know, cancer is a complex and common disease that affects millions of people worldwide. This architecture is often used for image classification.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. Auto-scale compute. In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells.
import all required libraries import pandas as pd import lazypredict # For regression problems from lazypredict.Supervised import LazyRegressor # For classification problems from lazypredict.Supervised import LazyClassifier STEP 3: Load the dataset(s) into the notebook. dist-packages/sklearn/neural_network/_multilayer_perceptron.py:686:
One way to solve Data Science’s challenges in Data Cleaning and pre-processing is to enable Artificial Intelligence technologies like Augmented Analytics and Auto-feature Engineering. Data Scientists must endure efforts through visualisation and evaluating the data in simple terms to explain complex business problems.
Learn more → Best MLOps Tools For Your Computer Vision Project Pipeline → Building MLOps Pipeline for Computer Vision: Image Classification Task [Tutorial] Fine-tuning Model fine-tuning and Transfer Learning have become essential techniques in my workflow when working with CV models. Libraries like imgaug , albumentations , and torchvision.
XLNet integrates the novelties from Transformer-XL like recurrence mechanism and relative encoding scheme (explained later as well). Performance on text classification task. XLNet does not rely on data corruption as in BERT and hence does not suffer from the pretrain-finetune discrepancy. and SQuADv2.0
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. Data formats like image, video, text, etc.,
This is the link [8] to the article about this Zero-Shot Classification NLP. BART stands for Bidirectional and Auto-Regression, and is used in processing human languages that is related to sentences and text. The approach was proposed by Yin et al. The technology that is used in this program is called BART.
Then you can use the model to perform tasks such as text generation, classification, and translation. If you already run your experiments on the DataRobot GUI, you could even add it as a custom task. Once installed, you can choose a model that suits your needs. writefile $BASE_PATH/custom.py """ Copyright 2021 DataRobot, Inc.
Michal, to warm you up for all this question-answering, how would you explain to us managing computer vision projects in one minute? Michal: As I explained at some point to me, I wouldn’t say it’s much more complex. What’s your approach to different modalities of classification detection and segmentation?
DOE: stands for the design of experiments, which represents the task design aiming to describe and explain information variation under hypothesized conditions to reflect variables. Define and explain selection bias? Explain it’s working. Classification is very important in machine learning. Define confounding variables.
His presentation explained data-centric AI’s promise for overcoming what is increasingly the biggest bottleneck to AI and machine learning: the lack of sufficiently large, labeled datasets. Take that canonical spam classification example: if you see the phrase wire transfer , maybe it’s more likely to be spam.
His presentation explained data-centric AI’s promise for overcoming what is increasingly the biggest bottleneck to AI and machine learning: the lack of sufficiently large, labeled datasets. Take that canonical spam classification example: if you see the phrase wire transfer , maybe it’s more likely to be spam.
The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. We can well explain this in a cancer detection example. Training Convolutional Neural Networks for image classification is time and resource-intensive. The model is trained on bags of observations.
Embeddings are essential for LLMs to understand natural language, enabling them to perform tasks like text classification, question answering, and more. Combine this with the serverless BentoCloud or an auto-scaling group on a cloud platform like AWS to ensure your resources match the demand.
It will further explain the various containerization terms and the importance of this technology to the machine learning workflow. Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application.
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. However, explaining why that decision was made requires next-level detailed reports from each affected model component of that AI system. Mitigation strategies : Implementing measures to minimize or eliminate risks.
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. input saliency is a method that explains individual predictions. The literature is most often concerned with this application for classification tasks, rather than natural language generation.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. This results in a need for further fine-tuning of these generative AI models over the use case-specific and domain-specific data. Llama 2 is intended for commercial and research use in English.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content