This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
At the end of the day, why not use an AutoML package (Automated MachineLearning) or an Auto-Forecasting tool and let it do the job for you? However, we already know that: MachineLearning models deliver better results in terms of accuracy when we are dealing with interrelated series and complex patterns in our data.
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Armed with these foundational skills, youre now ready to move to the next level: integrating a real-world machinelearning model into a FastAPI application. Whats Next? Thats not the case.
TensorFlow is a powerful open-source framework for building and deploying machinelearning models. Learning TensorFlow enables you to create sophisticated neural networks for tasks like image recognition, natural language processing, and predictive analytics.
sktime — Python Toolbox for MachineLearning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for MachineLearning with Time Series ,” there! Classification? Annotation? Something else? Forecasting with sktime is simple!
How pose estimation works: Deeplearning methods Use Cases and pose estimation applications How to get started with AI motion analysis Real-time full body pose estimation in construction – built with Viso Suite About us: Viso.ai Definition: What is pose estimation? Variations: Head pose estimation, animal pose estimation, etc.
In the past few years, Artificial Intelligence (AI) and MachineLearning (ML) have witnessed a meteoric rise in popularity and applications, not only in the industry but also in academia. Recent research in the field of IoT edge computing has demonstrated the potential to implement MachineLearning techniques in several IoT use cases.
Introduction to MachineLearning Frameworks In the present world, almost every organization is making use of machinelearning and artificial intelligence in order to stay ahead of the competition. So, let us see the most popular and best machinelearning frameworks and their uses.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
MachineLearning Operations (MLOps) is a set of practices and principles that aim to unify the processes of developing, deploying, and maintaining machinelearning models in production environments. Types of MLOps Tools MLOps tools play a pivotal role in every stage of the machinelearning lifecycle.
How to use deeplearning (even if you lack the data)? You can create synthetic data that acts just like real data – and so allows you to train a deeplearning algorithm to solve your business problem, leaving your sensitive data with its sense of privacy, intact. What is deeplearning?
These techniques utilize various machinelearning (ML) based approaches. Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. The following diagram shows our solution architecture.
About this series In this series , we will learn how to code the must-to-know deeplearning algorithms such as convolutions, backpropagation, activation functions, optimizers, deep neural networks, and so on using only plain and modern C++. A hamster? A Guinea Pig? exp(); Vector sums = expo.colwise().sum();
Photo by NASA on Unsplash Hello and welcome to this post, in which I will study a relatively new field in deeplearning involving graphs — a very important and widely used data structure. This post includes the fundamentals of graphs, combining graphs and deeplearning, and an overview of Graph Neural Networks and their applications.
Background of multimodality models Machinelearning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data. Outside of work, he enjoys reading and traveling.
of Large Model Inference (LMI) DeepLearning Containers (DLCs). We set this value to max (maximum GPU on the current machine). For the TensorRT-LLM container, we use auto. Similarly, you can use log_prob as measure of confidence score for classification use cases.
Low-Code PyCaret: Let’s start off with a low-code open-source machinelearning library in Python. PyCaret allows data professionals to build and deploy machinelearning models easily and efficiently. Well, one of its main advantages is that PyCaret reduces the amount of code required to build a machinelearning model.
The Falcon 2 11B model is available on SageMaker JumpStart, a machinelearning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
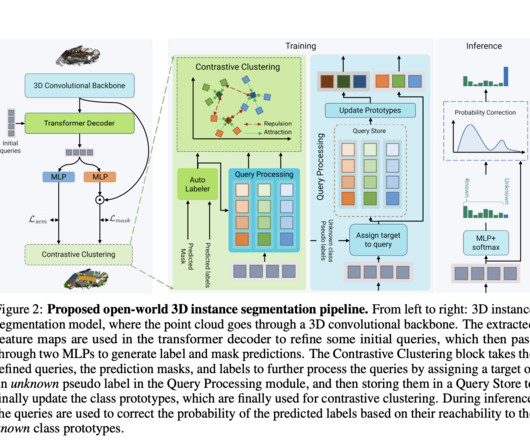
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. They use an auto-labeling approach to distinguish between known and unknowable class labels to produce pseudo-labels during training.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. It uses attention as the learning mechanism to achieve close to human-level performance. 24xlarge, ml.g5.48xlarge, ml.p4d.24xlarge,
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. But not all AI is created equal. This makes it extremely fast and privacy-friendly.
PyTorch is a machinelearning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. For a list of NVIDIA Triton DeepLearning Containers (DLCs) supported by SageMaker inference, refer to Available DeepLearning Containers Images.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. The architecture of DJL is engine agnostic.
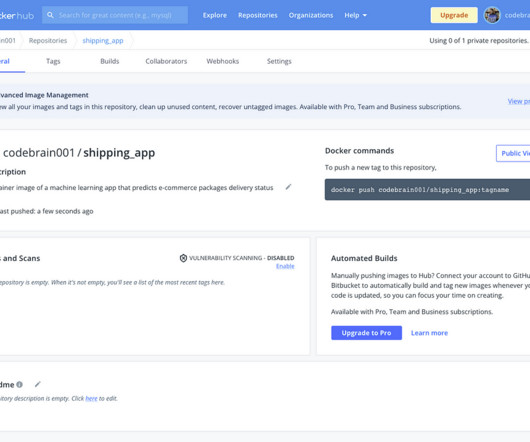
Photo by Ian Taylor on Unsplash This article will comprehensively create, deploy, and execute machinelearning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machinelearning workflow. Yes, they do, but partially.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. In this post, we dive deep to see how Amazon SageMaker can serve these models using NVIDIA Triton Inference Server.
Statistical methods and machinelearning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon MachineLearning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
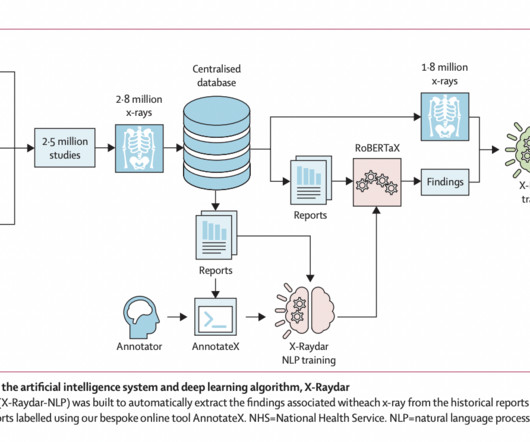
The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test. For testing, a consensus set of 1,427 images annotated by expert radiologists, an auto-labeled set (n=103,328), and an independent dataset, MIMIC-CXR (n=252,374), were employed.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machinelearning (AI/ML) in its professional information products for decades. It provides resilient and persistent clusters for large-scale deeplearning training of FMs on long-running compute clusters.
Amazon Elastic Compute Cloud (Amazon EC2) DL2q instances, powered by Qualcomm AI 100 Standard accelerators, can be used to cost-efficiently deploy deeplearning (DL) workloads in the cloud. This is a guest post by A.K Roy from Qualcomm AI. The cores are interconnected with a high-bandwidth low-latency network-on-chip (NoC) mesh.
Understanding the biggest neural network in DeepLearning Join 34K+ People and get the most important ideas in AI and MachineLearning delivered to your inbox for free here Deeplearning with transformers has revolutionized the field of machinelearning, offering various models with distinct features and capabilities.
Many practitioners are extending these Redshift datasets at scale for machinelearning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. First, we’ll build a deep-learning model with Lightning. PyTorch-Lightning As you know, PyTorch is a popular framework for building deeplearning models.
Amazon SageMaker is a fully managed machinelearning (ML) service. This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. Auto scaling. Depending on your traffic patterns, you can attach an auto scaling policy to your SageMaker endpoint.
Machinelearning has increased considerably in several areas due to its performance in recent years. Thanks to modern computers’ computing capacity and graphics cards, deeplearning has made it possible to achieve results that sometimes exceed those experts give.
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. Basically, it predicts a word with the context of the previous word.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh This will create one instance of each type.
Comet, a cloud-based machinelearning platform, offers a powerful solution for tracking, comparing, and benchmarking fine-tuned models, allowing users to easily analyze and visualize their performance. However, the lessons you’ll learn from this tutorial will help you benchmark more computer vision models.
These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera. Likewise, according to AWS , inference accounts for 90% of machinelearning demand in the cloud. 2020 or Hoffman et al.,
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
Transformers provides pre-built NLP models, torch serves as the backend for deeplearning tasks, and accelerate ensures efficient resource utilization on GPUs. This compact, instruction-tuned model is optimized to handle tasks like sentiment classification directly within Colab, even under limited computational resources.
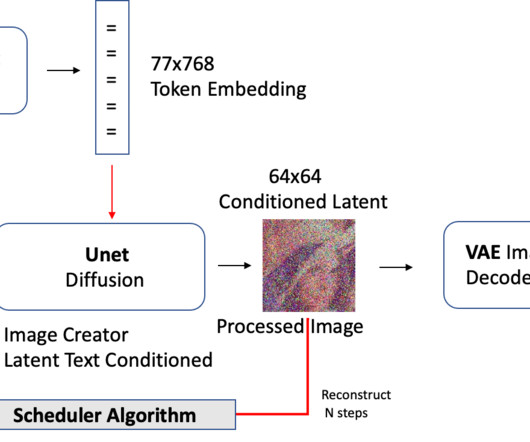
Machinelearning (ML) engineers can fine-tune and deploy text-to-semantic-segmentation and in-painting models based on pre-trained CLIPSeq and Stable Diffusion with Amazon SageMaker. Hugging Face and Amazon introduced Hugging Face DeepLearning Containers (DLCs) to scale fine tuning tasks across multiple GPUs and nodes.
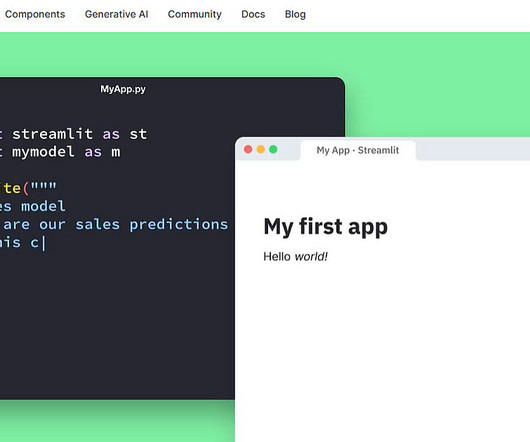
About us: At viso.ai, we’ve built the end-to-end machinelearning infrastructure for enterprises to scale their computer vision applications easily. Streamlit is a Python-based library specifically developed for machinelearning engineers. Computer vision and machinelearning specialists are not web developers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content