This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Armed with these foundational skills, youre now ready to move to the next level: integrating a real-world machine learning model into a FastAPI application. We Made It! We recommend PyImageSearch University.
How pose estimation works: Deeplearning methods Use Cases and pose estimation applications How to get started with AI motion analysis Real-time full body pose estimation in construction – built with Viso Suite About us: Viso.ai Definition: What is pose estimation? Variations: Head pose estimation, animal pose estimation, etc.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? However, we already know that: Machine Learning models deliver better results in terms of accuracy when we are dealing with interrelated series and complex patterns in our data.
Furthermore, ML models are often dependent on DeepLearning, Deep Neural Networks, Application Specific Integrated Circuits (ASICs) and Graphic Processing Units (GPUs) for processing the data, and they often have a higher power & memory requirement.
Photo by NASA on Unsplash Hello and welcome to this post, in which I will study a relatively new field in deeplearning involving graphs — a very important and widely used data structure. This post includes the fundamentals of graphs, combining graphs and deeplearning, and an overview of Graph Neural Networks and their applications.
How to use deeplearning (even if you lack the data)? Say, by using personal information that, for legal reasons, you cannot share. Read on to learn how to use deeplearning in the absence of real data. What is deeplearning? Deeplearning is a form of machine learning.
Overview of solution In this post, we go through the various steps to apply ML-based fuzzy matching to harmonize customer data across two different datasets for auto and property insurance. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. We’ve entered a pivotal time, one that requires organizations to fight AI with AI.
By translating images into text, we unlock and harness the wealth of information contained in visual data. Similarly, it can assist in generating automatic photo descriptions, providing information that might not be included in product titles or descriptions, thereby improving user experience.
Amazon Elastic Compute Cloud (Amazon EC2) DL2q instances, powered by Qualcomm AI 100 Standard accelerators, can be used to cost-efficiently deploy deeplearning (DL) workloads in the cloud. For more information, see Amazon EC2 pricing. This is a guest post by A.K Roy from Qualcomm AI.
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. To learn more about the config settings, refer to Model Configuration. nvidia/pytorch:23.02-py3
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (Machine Learning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Can you debug system information? Can you compare images? Can you customize the UI to your needs?
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. Step 1: We highlight the points from different articles to make a set of useful information.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. In this post, we dive deep to see how Amazon SageMaker can serve these models using NVIDIA Triton Inference Server.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. They are professionals with discerning information needs in legal, corporate, tax, risk, fraud, compliance, and news domains. 55 440 0.1
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. It uses attention as the learning mechanism to achieve close to human-level performance.
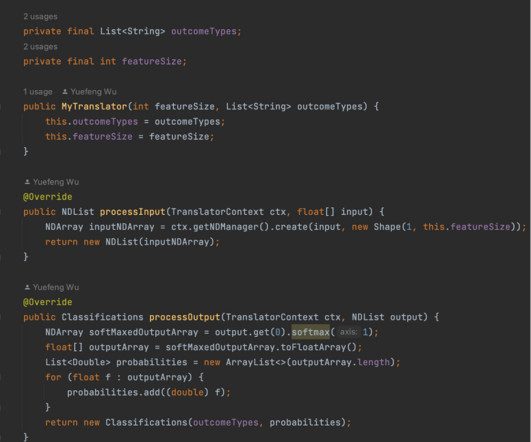
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. In our case, we chose to use a float[] as the input type and the built-in DJL classifications as the output type.
of Large Model Inference (LMI) DeepLearning Containers (DLCs). For more information about all common and backend-specific deployment configuration parameters, see Large Model Inference Configurations. For more information about the related configurations, refer to TensorRT-LLM.
Understanding the biggest neural network in DeepLearning Join 34K+ People and get the most important ideas in AI and Machine Learning delivered to your inbox for free here Deeplearning with transformers has revolutionized the field of machine learning, offering various models with distinct features and capabilities.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. For more information, refer to Requesting a quota increase. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself.
Machine learning frameworks like scikit-learn are quite popular for training machine learning models while TensorFlow and PyTorch are popular for training deeplearning models that comprise different neural networks. We also save the trained model as an artifact using wandb.save().
This model can perform a number of tasks, but we send a payload specifically for sentiment analysis and text classification. For more information, refer to How Amazon CloudWatch works. Auto scaling. Depending on your traffic patterns, you can attach an auto scaling policy to your SageMaker endpoint.
These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera. There are other factors that can delay the inference, such as the complexity of the question, the amount of information required to generate a response, et cetera.
Use SageMaker Feature Store for model training and prediction To use SageMaker Feature store for model training and prediction, open the notebook 5-classification-using-feature-groups.ipynb. This option allows you to specify more complicated SQL queries to extract information from a feature group.
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. Hyperparameter optimization is highly computationally demanding for deeplearning models. eks-create.sh
For example, access to timely, accurate health information is a significant challenge among women in rural and densely populated urban areas across India. To solve this challenge, ARMMAN developed mMitra , a free mobile service that sends preventive care information to expectant and new mothers.
For example, each log is written in the format of timestamp, user ID, and event information. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. AutoGluon is a toolkit for automated machine learning (AutoML). These types of data are historical raw data from an ML perspective.
It utilizes a text prompt or an image encoder to encode textual and visual information into a multimodal embedding space, enabling highly accurate segmentation of target objects based on the prompt. Hugging Face and Amazon introduced Hugging Face DeepLearning Containers (DLCs) to scale fine tuning tasks across multiple GPUs and nodes.
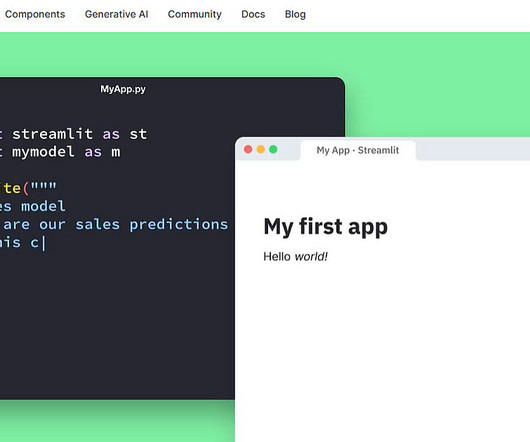
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. So let’s get the buggy war started!
For example, in medical imaging, techniques like skull stripping and intensity normalization are often used to remove irrelevant background information and normalize tissue intensities across different scans, respectively. Monitor your application and use auto-scaling features provided by cloud platforms to adjust resources as needed.
The choice of how to encode positional information for transformers has been one of the key components of LLM architectures. LLMs are powerful but expensive to run, and generating responses or code auto-completion can quickly accumulate costs, especially when serving many users.
Why is Streamlit useful in Machine Learning? Machine learning extracts hidden information and insights from big data using statistical methods and techniques. It will assist the users and executives in identifying important information that is extracted from data. The.gif files should be stored in file and file_.
Data analytics deals with checking the existing hypothesis and information and answering questions for a better and more effective business-related decision-making process. Long format DataWide-Format DataHere, each row of the data represents the one-time information of a subject. Classification is very important in machine learning.
Today, the computer vision project has gained enormous momentum in mobile applications, automated image annotation tools , and facial recognition and image classification applications. It synthesizes the information from both the image and prompt encoders to produce accurate segmentation masks.
The Large Language Model (LLM) understands the customer’s intent, extracts key information from their query, and delivers accurate and relevant answers. Moreover, LLMs continuously learn from customer interactions, allowing them to improve their responses and accuracy over time.
Text annotation is important as it makes sure that the machine learning model accurately perceives and draws insights based on the provided information. It allows text classification with multiple categories and offers text annotation for any script or language. – It offers documentation and live demos for ease of use.
The creation of foundation models is one of the key developments in the field of large language models that is creating a lot of excitement and interest amongst data scientists and machine learning engineers. These models are trained on massive amounts of text data using deeplearning algorithms. and its affiliates.
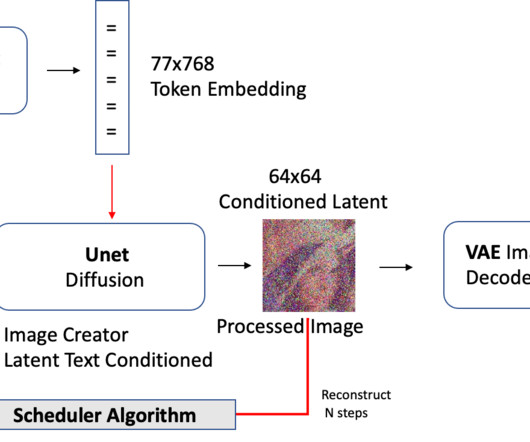
I was extremely surprised and pleased by the capabilities of these image generative AI models, and also very thankful that life decided to turn me to deeplearning instead! Safety Checker —classification model that screens outputs for potentially harmful content. Scheduler — essentially ODE integration techniques.
Retrieval Augmented Generation (RAG) enables LLMs to extract and synthesize information like an advanced search engine. RAG enables LLMs to pull relevant information from vast databases to answer questions or provide context, acting as a supercharged search engine that finds, understands, and integrates information.
The entire solution was to combine the information from 2D and 3D altogether. The difficulty is to be able to get access to multiple sources of data, combine them together, learn where all this data that might be useful is, and how to combine it. You can’t also assess how much information there is in the data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content