This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The LightAutoML framework is deployed across various applications, and the results demonstrated superior performance, comparable to the level of datascientists, even while building high-quality machine learning models. The LightAutoML framework attempts to make the following contributions.
Data Science is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A DataScientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? An AutoML tool will usually use all the data you have available, develop several models, and then select the best-performing model as a global ‘champion’ to generate forecasts for all time series.
In model-centric AI, datascientists or researchers assume the data is static and pour their energy into adjusting model architectures and parameters to achieve better results. Our primary source of signal comes from subject matter experts who collaborate with datascientists to build labeling functions.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. Custom classification is a two-step process.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
There are different levels of automation an enterprise can apply at various points in the data lifecycle to enforce good governance, including: Column-level access control : Enforces access via users, groups and teams with high levels of granularity. Auto-generated audit logs : Record data interactions to understand how employees use data.
AWS SageMaker is designed to simplify the machine learning process, whether you’re a datascientist, developer, or starting out. It gives you everything you need—from data preparation to model training and deployment—all in one place. That’s where AWS SageMaker comes in. Here’s a breakdown of the key steps: 1.
Although MLOps is an abbreviation for ML and operations, don’t let it confuse you as it can allow collaborations among datascientists, DevOps engineers, and IT teams. Model Training Frameworks This stage involves the process of creating and optimizing predictive models with labeled and unlabeled data.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
With all the talk about new AI-powered tools and programs feeding the imagination of the internet, we often forget that datascientists don’t always have to do everything 100% themselves. This frees up the datascientists to work on other aspects of their projects that might require a bit more attention.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
For any machine learning (ML) problem, the datascientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
It also enables you to evaluate the models using advanced metrics as if you were a datascientist. In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab.
Then, datascientists use these probabilistic labels to train discriminative end models. Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al. The following papers explore topics in WS.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. Our labelers are physicians and researchers, their time is very expensive.”
Use SageMaker Feature Store for model training and prediction To use SageMaker Feature store for model training and prediction, open the notebook 5-classification-using-feature-groups.ipynb. Batch transform allows you to get model inferene on a bulk of data in Amazon S3, and its inference result is stored in Amazon S3 as well.
Modifying Microsoft Phi 2 LLM for Sequence Classification Task. Transformer-Decoder models have shown to be just as good as Transformer-Encoder models for classification tasks (checkout winning solutions in the kaggle competition: predict the LLM where most winning solutions finetuned Llama/Mistral/Zephyr models for classification).
ML model builders spend a ton of time running multiple experiments in a data science notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. 42% of datascientists are solo practitioners or on teams of five or fewer people.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
With SageMaker, datascientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers.
Optionally, if you’re using Snowflake OAuth access in SageMaker Data Wrangler, refer to Import data from Snowflake to set up an OAuth identity provider. Datascientists should have the following prerequisites Access to Amazon SageMaker , an instance of Amazon SageMaker Studio , and a user for SageMaker Studio.
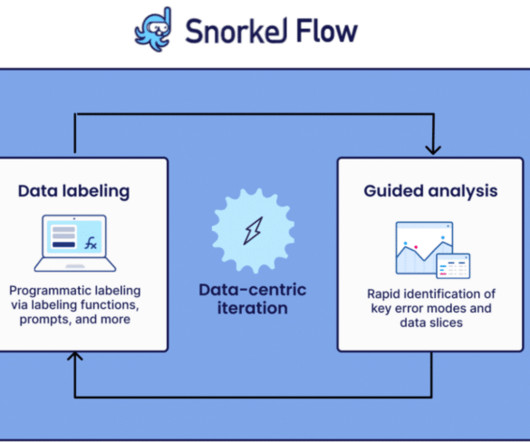
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
Photo by Agence Olloweb on Unsplash It is an important decision point to tune model parameters in a daily task of a datascientist. I have the binary classification problem that is why I try to make maximize F1 score. F1 score and parameters: {‘C’: 4, ‘kernel’: ‘poly’, ‘degree’: 1, ‘gamma’: ‘auto’}. We have 0.84
Then, datascientists use these probabilistic labels to train discriminative end models. Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al. The following papers explore topics in WS.
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. In our case, we used AutoGluon with SageMaker to realize a two-stage prediction, including churn classification and lifetime value regression. Muhyun Kim is a datascientist at Amazon Machine Learning Solutions Lab.
Utilize this model to diagnose data issues (via techniques covered here) and improve the dataset. For more complex issues like label errors, you can again simply filter out all the auto-detected bad data. Train the same model on the improved dataset. Try various modeling techniques to further improve performance.
Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos.
By enabling datascientists to rapidly iterate through model development, validation, and deployment, DataRobot provides the tools to blitz through steps four and five of the machine learning lifecycle with AutoML and Auto Time-Series capabilities. High-level example of a common machine learning lifecycle.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. Wioletta Stobieniecka is a DataScientist at AWS Professional Services. 24xlarge, ml.g5.48xlarge, ml.p4d.24xlarge,
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. Image Classification for Cancer Detection As we all know, cancer is a complex and common disease that affects millions of people worldwide. This architecture is often used for image classification.
DataScientists may think the future of AI is GPT-3, and it has created new possibilities in the AI landscape. With limited input text and supervision, GPT-3 auto-generated a complete essay using conversational language peculiar to humans. Stephen Hawking has warned that AI could ‘spell the end of the human race.’ Believe me.”.
The enhanced data contains new data features relative to this example use case. In your application, take time to imagine the diverse set of questions available in your images to help your classification or regression task. In social media platforms, photos could be auto-tagged for subsequent use.
In the end, the model is obviously like this major part the datascientists are busy with or the key part, but there are a lot of other things that have to be secured first. This is something that you have time for thought process necessary for the datascientist to understand the problem better and also build some stable solution.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., Finally, for evaluation, we are using accuracy , precision, and recall scores. #
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Data science has become an integral part of many industries, and as a result, the demand for skilled datascientists is soaring. Classification is very important in machine learning.
This is the link [8] to the article about this Zero-Shot Classification NLP. BART stands for Bidirectional and Auto-Regression, and is used in processing human languages that is related to sentences and text. I also got a lot more comfortable with working with huge data and therefore master the skills of a datascientist along the way.
The creation of foundation models is one of the key developments in the field of large language models that is creating a lot of excitement and interest amongst datascientists and machine learning engineers. These models are trained on massive amounts of text data using deep learning algorithms. What Are Large Language Models?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























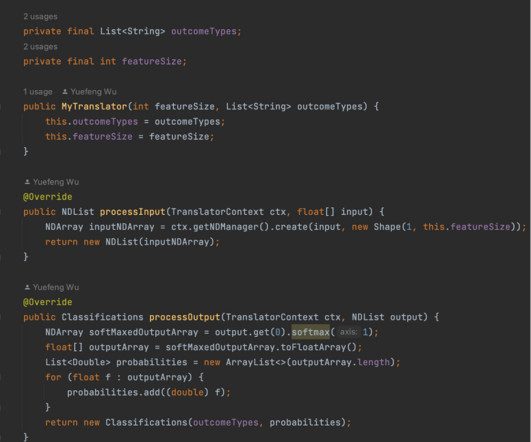















Let's personalize your content