This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python. This makes Auto-ViML an ideal tool for beginners and experts alike.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
A guide to performing end-to-end computer vision projects with PyTorch-Lightning, Comet ML and Gradio Image by Freepik Computer vision is the buzzword at the moment. Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
I was fascinated by how much human knowledge—anything anyone had ever deemed patentable—was readily available, yet so inaccessible because it was so hard to do even the simplest analysis over complex technical text and multi-modal data. When that’s the case, the best way to improve these models is to supply them with more and better data.
For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Don’t think you have to manually do all of the data curation work yourself! New algorithms/software can help you systematically curate your data via automation. In this post, I’ll give a high-level overview of how AI/ML can be used to automatically detect various issues common in real-world datasets.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. It also enables you to evaluate the models using advanced metrics as if you were a data scientist.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. However, lack of labeled training data bottlenecked their progress.
Most, if not all, machine learning (ML) models in production today were born in notebooks before they were put into production. 42% of data scientists are solo practitioners or on teams of five or fewer people. 42% of data scientists are solo practitioners or on teams of five or fewer people. Auto-scale compute.
Harness a flywheel approach, wherein continuous data feedback is utilized to routinely orchestrate and evaluate enhancements to your models and processes. Common stages include data capture, document classification, document text extraction, content enrichment, document review and validation , and data consumption.
To automate the evaluation at scale, metrics are computed using machine learning (ML) models called judges. Skip the preamble or explanation, and provide the classification. Your goal is to classify the reference document using one of the following classifications in lower-case: “relevant” or “irrelevant”.
Photo by Scott Webb on Unsplash Determining the value of housing is a classic example of using machine learning (ML). Almost 50 years later, the estimation of housing prices has become an important teaching tool for students and professionals interested in using data and ML in business decision-making.
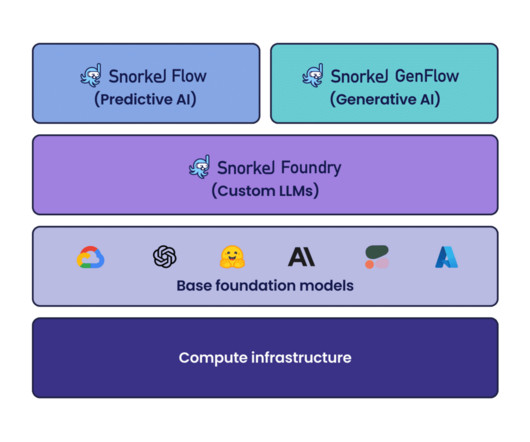
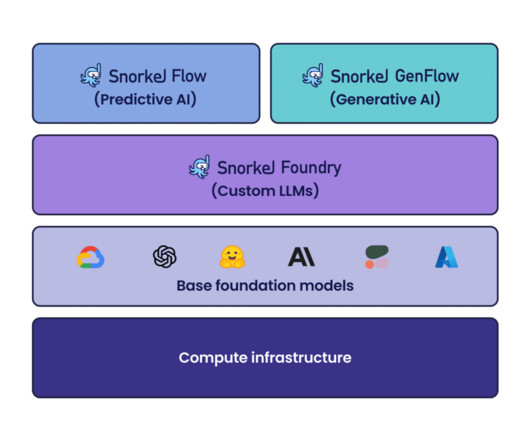
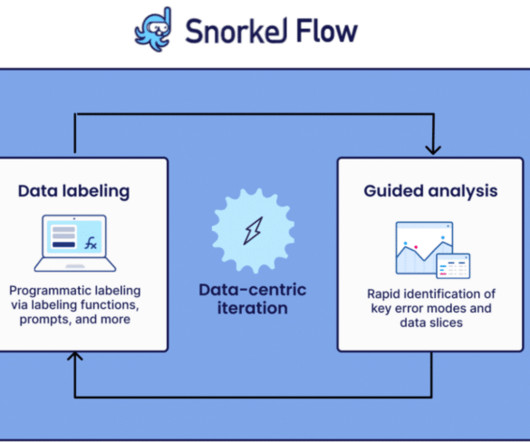
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
Python is unarguably the most broadly used programming language throughout the datascience community. DataRobot will automatically perform a data quality assessment, determine the problem domain to solve for whether that be binary classification, regression, etc., Consuming AI/ML Insights for Faster Decision Making.
In this article, we discuss key Snorkel Flow features and capabilities that help datascience and machine learning teams to adapt NLP models to non-English languages. For text classification, however, there are many similarities. This may require extensive customization and fine-tuning of the model.
But deep down, we know we could achieve better results with a different approach, after all in ML, there’s no one-size-fits-all solution. For this post, we’ll be using LazyRegressor() because we’re working on a regression task but it’s the same step for classification problems (we’d just use LazyClassifier() instead). #
Adherence to such public health programs is a prevalent challenge, so researchers from Google Research and the Indian Institute of Technology, Madras worked with ARMMAN to design an ML system that alerts healthcare providers about participants at risk of dropping out of the health information program. certainty when used correctly.
Streamlit is a good choice for developers and teams that are well-versed in datascience and want to deploy AI models easily, and quickly, with a few lines of code. Viso Suite doesn’t just cover model training but extends to the entire ML pipeline from sourcing data to security.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., This approach is mostly referred to for small datasets where ML models can not be effective.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computer vision projects. Then we are there to help.
This piece of data that my mentor found is called “ SemCor Corpus [5] ” (We access the dataset via NLTK’s SemcorCorpusReader [6] ) The reformatted version of the dataset looks something like this. It might look quite overwhelming but this is what datascience and computer engineering are about.
You can easily try out these models and use them with SageMaker JumpStart, which is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
This article will walk you through how to process large medical images efficiently using Apache Beam — and we’ll use a specific example to explore the following: How to approach using huge images in ML/AI Different libraries for dealing with said images How to create efficient parallel processing pipelines Ready for some serious knowledge-sharing?
The machine learning (ML) lifecycle defines steps to derive values to meet business objectives using ML and artificial intelligence (AI). Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application. Prerequisite Python 3.8
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Set up the notebook environment with the image DataScience 3.0. With an ml.t3.medium
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content