This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. However, explaining why that decision was made requires next-level detailed reports from each affected model component of that AI system. Mitigation strategies : Implementing measures to minimize or eliminate risks.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
In model-centric AI, data scientists or researchers assume the data is static and pour their energy into adjusting model architectures and parameters to achieve better results. When that’s the case, the best way to improve these models is to supply them with more and better data.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself.
DataScience is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A Data Scientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. However, lack of labeled training data bottlenecked their progress.
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
ML model builders spend a ton of time running multiple experiments in a datascience notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. 42% of data scientists are solo practitioners or on teams of five or fewer people.
Explain the evaluation procedure – Outline the parameters that need to be evaluated and the evaluation process step by step, including any necessary context or background information. Skip the preamble or explanation, and provide the classification. Skip any preamble or explanation, and provide the classification.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. Image Classification for Cancer Detection As we all know, cancer is a complex and common disease that affects millions of people worldwide. This architecture is often used for image classification.
import all required libraries import pandas as pd import lazypredict # For regression problems from lazypredict.Supervised import LazyRegressor # For classification problems from lazypredict.Supervised import LazyClassifier STEP 3: Load the dataset(s) into the notebook. dist-packages/sklearn/neural_network/_multilayer_perceptron.py:686:
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., Finally, for evaluation, we are using accuracy , precision, and recall scores. #
This piece of data that my mentor found is called “ SemCor Corpus [5] ” (We access the dataset via NLTK’s SemcorCorpusReader [6] ) The reformatted version of the dataset looks something like this. It might look quite overwhelming but this is what datascience and computer engineering are about.
He has two master’s degrees in Complex Systems Science from École Polytechnique and the University of Warwick. He has led several datascience projects spanning multiple industries like manufacturing, retail, healthcare, insurance, safety, et cetera. It seems more complex than regular tabular data.
Kaggle is an online community for data scientists that regularly organizes datascience contests. The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. We can well explain this in a cancer detection example.
It will further explain the various containerization terms and the importance of this technology to the machine learning workflow. Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application. Prerequisite Python 3.8
This results in a need for further fine-tuning of these generative AI models over the use case-specific and domain-specific data. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Llama 2 is intended for commercial and research use in English.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. Please explain the main clinical purpose of such image?Can
The Best Egg datascience team uses Amazon SageMaker Studio for building and running Jupyter notebooks. Best Egg trains multiple credit models using classification and regression algorithms. The trained model artifact is hosted on a SageMaker real-time endpoint using the built-in auto scaling and load balancing features.
However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional datascience toolkit (SQL, Python, R etc.). The manual collection of training data for Text2SQL is particularly tedious.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















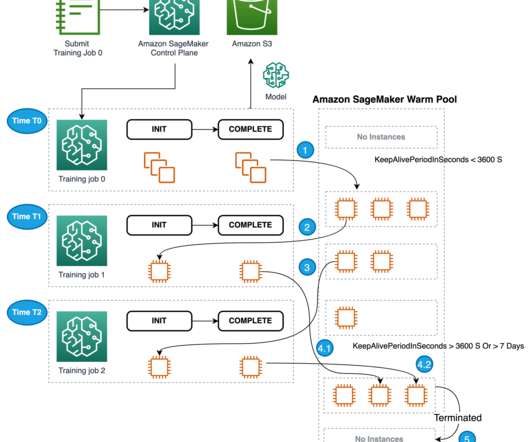







Let's personalize your content