This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? An AutoML tool will usually use all the data you have available, develop several models, and then select the best-performing model as a global ‘champion’ to generate forecasts for all time series.
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
How to use deeplearning (even if you lack the data)? To train a computer algorithm when you don’t have any data. Some would say, it’s impossible – but at a time where data is so sensitive, it’s a common hurdle for a business to face. Read on to learn how to use deeplearning in the absence of real data.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
This is the reason why data scientists need to be actively involved in this stage as they need to try out different algorithms and parameter combinations. It checks data and model quality, data drift, target drift, and regression and classification performance.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. First, we’ll build a deep-learning model with Lightning. PyTorch-Lightning As you know, PyTorch is a popular framework for building deeplearning models.
trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself.
If you are prompted to choose a kernel, choose DataScience as the image and Python 3 as the kernel, then choose Select. Here is one end-to-end data flow in the scenario of PLACE feature engineering. For details on model training and inference, refer to the notebook 5-classification-using-feature-groups.ipynb.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. AutoGluon is a toolkit for automated machine learning (AutoML). It enables easy-to-use and easy-to-extend AutoML with a focus on automated stack ensembling, deeplearning, and real-world applications spanning image, text, and tabular data.
Through exploreCSR , we partner with universities to provide students with introductory experiences in research, such as Rice University’s regional workshop on applications and research in datascience (ReWARDS), which was delivered in rural Peru by faculty from Rice. See some of the datasets and tools we released in 2022 listed below.
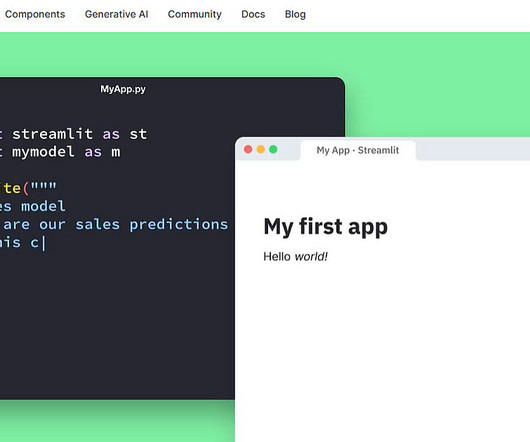
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., So let’s get the buggy war started! After some time, you will have your app baked out of the oven.
Streamlit is a good choice for developers and teams that are well-versed in datascience and want to deploy AI models easily, and quickly, with a few lines of code. About us: At viso.ai, we’ve built the end-to-end machine learning infrastructure for enterprises to scale their computer vision applications easily.
He has two master’s degrees in Complex Systems Science from École Polytechnique and the University of Warwick. He has led several datascience projects spanning multiple industries like manufacturing, retail, healthcare, insurance, safety, et cetera. It was data management. Then we are there to help.
Kaggle is an online community for data scientists that regularly organizes datascience contests. The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. Unfortunately, the competition rules prevent us from publishing competition data publicly.
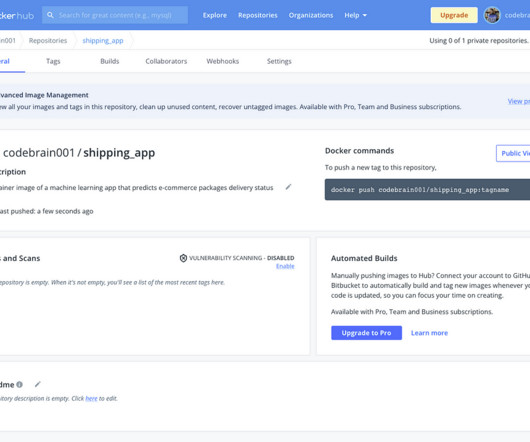
Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learningclassification application. The sample data for this project is E-Commerce Shipping data found on Kaggle to predict whether product shipments were delivered on time.
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. We provide guidance on building, training, and deploying deeplearning networks on Amazon SageMaker.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Utilizing the latest Hugging Face LLM modules on Amazon SageMaker, AWS customers can now tap into the power of SageMaker deeplearning containers (DLCs).
In HPO mode, SageMaker Canvas supports the following types of machine learning algorithms: Linear learner: A supervised learning algorithm that can solve either classification or regression problems. Deeplearning algorithm: A multilayer perceptron (MLP) and feedforward artificial neural network. Select Data Split.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content