This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post explores how Lumi uses Amazon SageMaker AI to meet this goal, enhance their transaction processing and classification capabilities, and ultimately grow their business by providing faster processing of loan applications, more accurate credit decisions, and improved customer experience.
TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs). DataRobot DataRobot, founded in 2012, is an AI-powered datascience platform designed for building and deploying machine learning models.
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? An AutoML tool will usually use all the data you have available, develop several models, and then select the best-performing model as a global ‘champion’ to generate forecasts for all time series.
Finally, H2O AutoML has the ability to support a wide range of machine learning tasks such as regression, time-series forecasting, anomaly detection, and classification. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python. This makes Auto-ViML an ideal tool for beginners and experts alike.
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
In model-centric AI, data scientists or researchers assume the data is static and pour their energy into adjusting model architectures and parameters to achieve better results. When that’s the case, the best way to improve these models is to supply them with more and better data.
Additionally, healthcare datasets often contain complex and heterogeneous data types, making data standardization and interoperability a challenge in FL settings. Because this data is across organizations, we use federated learning to collate the findings. Al Nevarez is Director of Product Management at FedML.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. Outside of work, he loves spending time with his family, hiking, and playing soccer.
But from an ML standpoint, both can be construed as binary classification models, and therefore could share many common steps from an ML workflow perspective, including model tuning and training, evaluation, interpretability, deployment, and inference. The final outcome is an auto scaling, robust, and dynamically monitored solution.
Compute and infrastructure tools offer features such as containerization, orchestration, auto-scaling, and resource management, enabling organizations to efficiently utilize cloud resources, on-premises infrastructure, or hybrid environments for ML workloads. We also save the trained model as an artifact using wandb.save().
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
For more complex issues like label errors, you can again simply filter out all the auto-detected bad data. For instance, when fine-tuning various LLM models on a text classification task (politeness prediction), this auto-filtering improves LLM performance without any change in the modeling code!
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. However, lack of labeled training data bottlenecked their progress.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
ML model builders spend a ton of time running multiple experiments in a datascience notebook environment before moving the well-tested and robust models from those experiments to a secure, production-grade environment for general consumption. 42% of data scientists are solo practitioners or on teams of five or fewer people.
Skip the preamble or explanation, and provide the classification. Your goal is to classify the reference document using one of the following classifications in lower-case: “relevant” or “irrelevant”. Skip any preamble or explanation, and provide the classification. He enjoys contributing to open source and working with data.
trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself.
DataScience is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A Data Scientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
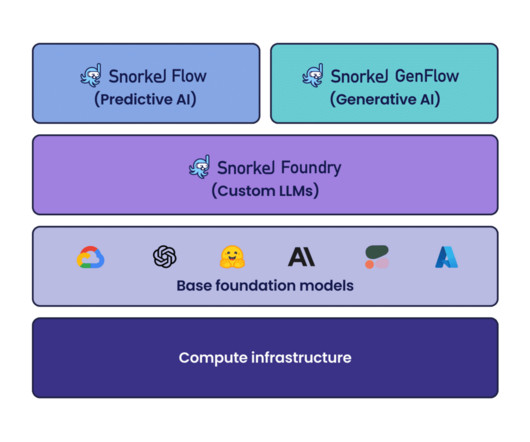
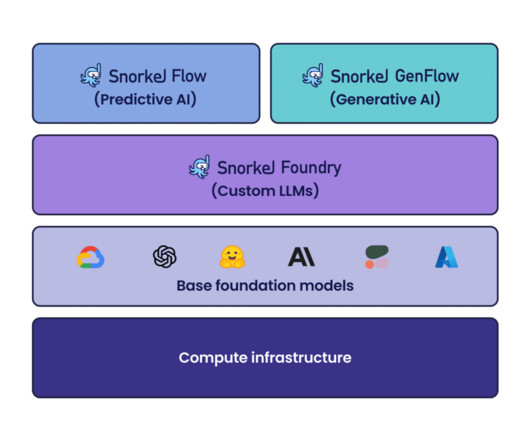
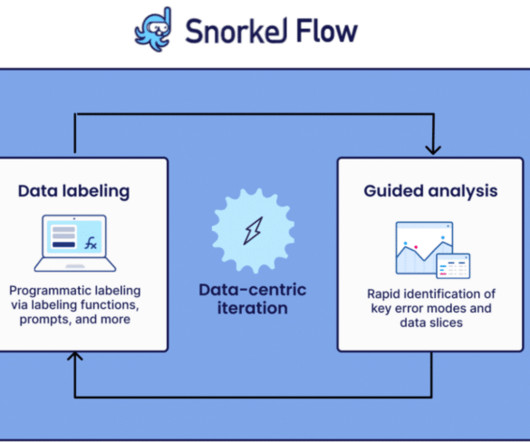
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos.
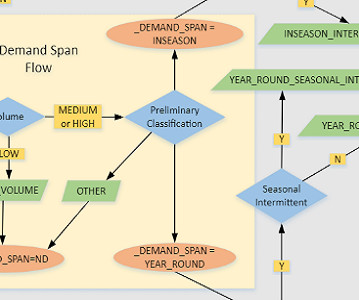
If you are prompted to choose a kernel, choose DataScience as the image and Python 3 as the kernel, then choose Select. Here is one end-to-end data flow in the scenario of PLACE feature engineering. For details on model training and inference, refer to the notebook 5-classification-using-feature-groups.ipynb.
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab.
classification, information extraction) using programmatic labeling, fine-tuning, and distillation. Latest features and platform improvements for Snorkel Flow Snorkel Flow provides an end-to-end machine learning solution designed around a data-centric approach. It allows you to dive deep into each LF and understand it in detail.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
Make sure that you import Comet library before PyTorch to benefit from auto logging features Choosing Models for Classification When it comes to choosing a computer vision model for a classification task, there are several factors to consider, such as accuracy, speed, and model size. Pre-trained models, such as VGG, ResNet.
With Snowflake’s newest feature release, Snowpark , developers can now quickly build and scale data-driven pipelines and applications in their programming language of choice, taking full advantage of Snowflake’s highly performant and scalable processing engine that accelerates the traditional data engineering and machine learning life cycles.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. Image Classification for Cancer Detection As we all know, cancer is a complex and common disease that affects millions of people worldwide. This architecture is often used for image classification.
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. In our case, we used AutoGluon with SageMaker to realize a two-stage prediction, including churn classification and lifetime value regression. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
Common stages include data capture, document classification, document text extraction, content enrichment, document review and validation , and data consumption. Amazon Comprehend Endpoint monitoring and auto scaling – Employ Trusted Advisor for diligent monitoring of Amazon Comprehend endpoints to optimize resource utilization.
In this article, we discuss key Snorkel Flow features and capabilities that help datascience and machine learning teams to adapt NLP models to non-English languages. For text classification, however, there are many similarities. This may require extensive customization and fine-tuning of the model.
With limited input text and supervision, GPT-3 auto-generated a complete essay using conversational language peculiar to humans. Quadrant Solutions SPARK Matrix: DataScience and Machine Learning Platform. Stephen Hawking has warned that AI could ‘spell the end of the human race.’ I am here to convince you not to worry.
The enhanced data contains new data features relative to this example use case. In your application, take time to imagine the diverse set of questions available in your images to help your classification or regression task. In social media platforms, photos could be auto-tagged for subsequent use. in DataScience.
import all required libraries import pandas as pd import lazypredict # For regression problems from lazypredict.Supervised import LazyRegressor # For classification problems from lazypredict.Supervised import LazyClassifier STEP 3: Load the dataset(s) into the notebook. dist-packages/sklearn/neural_network/_multilayer_perceptron.py:686:
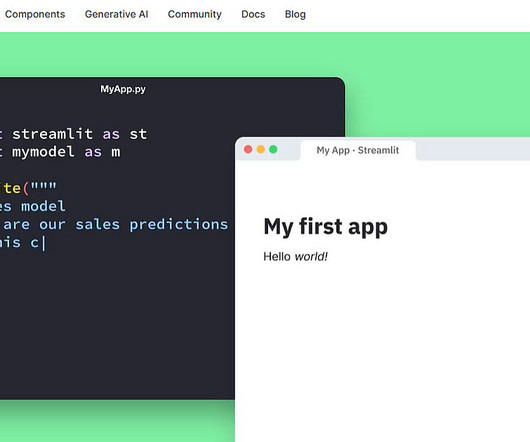
Streamlit is a good choice for developers and teams that are well-versed in datascience and want to deploy AI models easily, and quickly, with a few lines of code. st.video(data, format=”video/mp4″, start_time=0, *, subtitles=None) – function that displays video files.
In deep learning, a computer algorithm uses images, text, or sound to learn to perform a set of classification tasks. However, computer algorithms require a vast set of labeled data to learn any task – which begs the question: What can you do if you cannot use real information to train your algorithm? The answer?
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). Data formats like image, video, text, etc., Finally, for evaluation, we are using accuracy , precision, and recall scores. #
Through exploreCSR , we partner with universities to provide students with introductory experiences in research, such as Rice University’s regional workshop on applications and research in datascience (ReWARDS), which was delivered in rural Peru by faculty from Rice. See some of the datasets and tools we released in 2022 listed below.
This piece of data that my mentor found is called “ SemCor Corpus [5] ” (We access the dataset via NLTK’s SemcorCorpusReader [6] ) The reformatted version of the dataset looks something like this. It might look quite overwhelming but this is what datascience and computer engineering are about.
He has two master’s degrees in Complex Systems Science from École Polytechnique and the University of Warwick. He has led several datascience projects spanning multiple industries like manufacturing, retail, healthcare, insurance, safety, et cetera. ” Michal: To be honest, we don’t use Auto ML too often.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content