This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataquality control: Robust dataset labeling and annotation tools incorporate quality control mechanisms such as inter-annotator agreement analysis, review workflows, and data validation checks to ensure the accuracy and reliability of annotations. It is part of the Encord suite of products alongside Encord Active.
A typical multimodal LLM has three primary modules: The input module comprises specialized neuralnetworks for each specific data type that output intermediate embeddings. An output could be, e.g., a text, a classification (like “dog” for an image), or an image. Examples of different Kosmos-1 tasks.
Regularization techniques: experiment with weight decay, dropout, and data augmentation to improve model generalization. Managing dataquality and quantity : managing dataquality and quantity is crucial for training reliable CV models. Libraries like imgaug , albumentations , and torchvision.
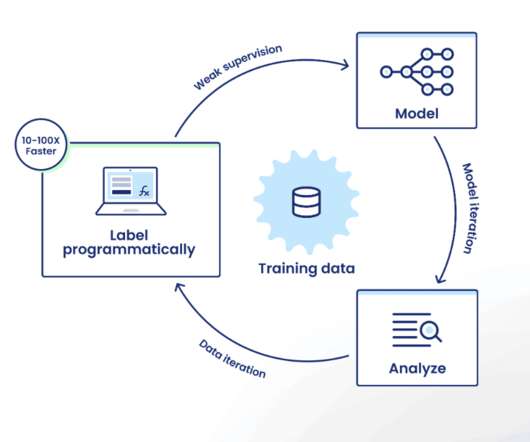
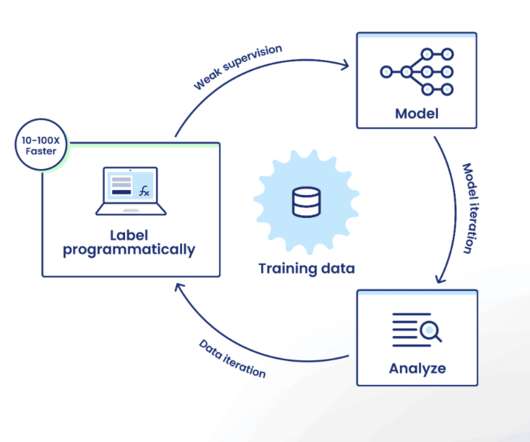
If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this: Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale. Auto-generated tag-based LFs.
If you’re not familiar with the Snorkel Flow platform, the iteration loop looks like this: Label programmatically: Encode labeling rationale as labeling functions (LFs) that the platform uses as sources of weak supervision to intelligently auto-label training data at scale. Auto-generated tag-based LFs.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content