This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
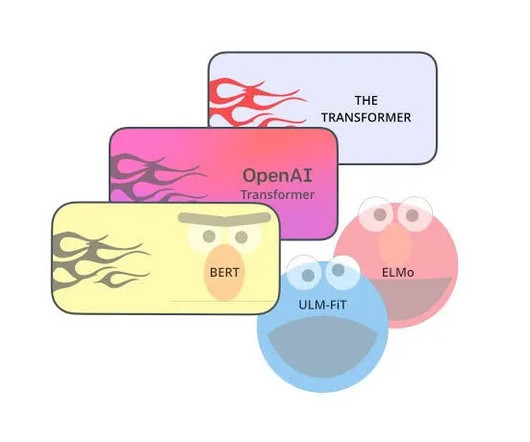
In this article, we aim to focus on the development of one of the most powerful generative NLP tools, OpenAI’s GPT. Evolution of NLP domain after Transformers Before we start, let's take a look at the timeline of the works which brought great advancement in the NLP domain. Let’s see it step by step. In 2015, Andrew M.
Throughout the course, you’ll progress from basic programming skills to solving complex computervision problems, guided by videos, readings, quizzes, and programming assignments. It also delves into NLP with tokenization, embeddings, and RNNs and concludes with deploying models using TensorFlow Lite.
These models, known for their success in fields like computervision and NL processing, can revolutionize healthcare by facilitating the translation of vast biomedical data into actionable health outcomes. In healthcare, NLP is instrumental in managing EHRs, which compile extensive medical data across patient histories.
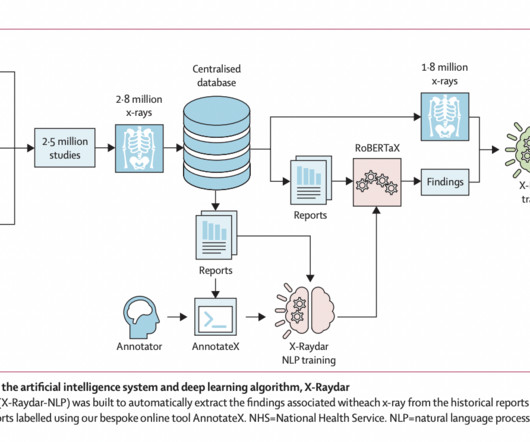
Trained on a dataset from six UK hospitals, the system utilizes neural networks, X-Raydar and X-Raydar-NLP, for classifying common chest X-ray findings from images and their free-text reports. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deep learning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
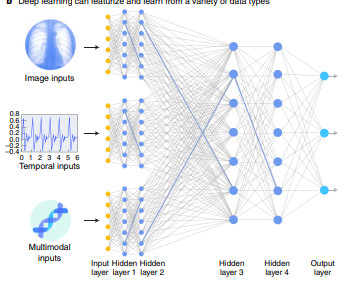
Background of multimodality models Machine learning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computervision, where models can exhibit human-like performance in analyzing and generating content from a single source of data.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. Deep learning (DL) models with more layers and parameters perform better in complex tasks like computervision and NLP.
With eight Qualcomm AI 100 Standard accelerators and 128 GiB of total accelerator memory, customers can also use DL2q instances to run popular generative AI applications, such as content generation, text summarization, and virtual assistants, as well as classic AI applications for natural language processing and computervision.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The output shows the expected JSON file content, illustrating the model’s natural language processing (NLP) and code generation capabilities. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs.
An IDP pipeline usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. Common stages include data capture, document classification, document text extraction, content enrichment, document review and validation , and data consumption.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
For the TensorRT-LLM container, we use auto. option.tensor_parallel_degree=max option.max_rolling_batch_size=32 option.rolling_batch=auto option.model_loading_timeout = 7200 We package the serving.properties configuration file in the tar.gz Similarly, you can use log_prob as measure of confidence score for classification use cases.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M We also continued to release sustainability data via Data Commons and invite others to use it for their research. See some of the datasets and tools we released in 2022 listed below. Pfam-NUniProt2 A set of 6.8
Classification is very important in machine learning. Hence, we have various classification algorithms in machine learning like logistic regression, support vector machine, decision trees, Naive Bayes classifier, etc. One such classification technique that is near the top of the classification hierarchy is the random forest classifier.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. After it’s fine-tuned on the domain-specific dataset, the model is expected to generate domain-specific text and solve various NLP tasks in that specific domain with few-shot prompting.
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. Multiple methods exist for assigning importance scores to the inputs of an NLP model. The literature is most often concerned with this application for classification tasks, rather than natural language generation.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
For example, input images for an object detection use case might need to be resized or cropped before being served to a computervision model, or tokenization of text inputs before being used in an LLM. However, in addition to model invocation, those DL application often entail preprocessing or postprocessing in an inference pipeline.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content