This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
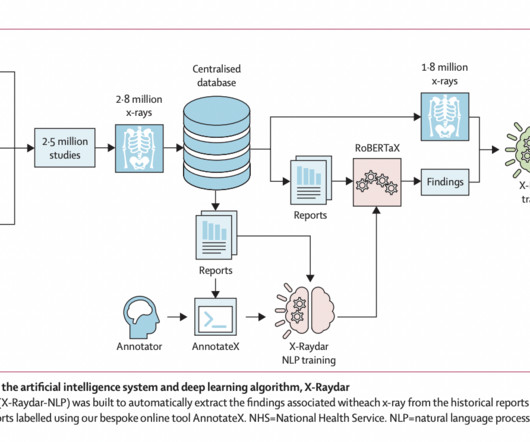
Trained on a dataset from six UK hospitals, the system utilizes neuralnetworks, X-Raydar and X-Raydar-NLP, for classifying common chest X-ray findings from images and their free-text reports. The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test.
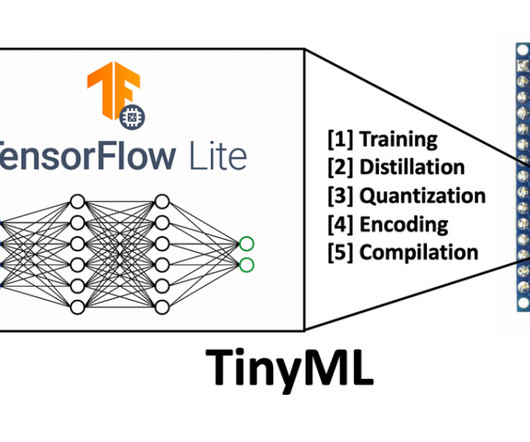
Learning TensorFlow enables you to create sophisticated neuralnetworks for tasks like image recognition, natural language processing, and predictive analytics. It covers various aspects, from using larger datasets to preventing overfitting and moving beyond binary classification.
Photo by Resource Database on Unsplash Introduction Neuralnetworks have been operating on graph data for over a decade now. Neuralnetworks leverage the structure and properties of graph and work in a similar fashion. Graph NeuralNetworks are a class of artificial neuralnetworks that can be represented as graphs.
Table of Contents Training a Custom Image ClassificationNetwork for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Also, in the current scenario, the data generated by different devices is sent to cloud platforms for processing because of the computationally intensive nature of network implementations. To tackle the issue, structured pruning and integer quantization for RNN or Recurrent NeuralNetworks speech enhancement model were deployed.
With over 3 years of experience in designing, building, and deploying computervision (CV) models , I’ve realized people don’t focus enough on crucial aspects of building and deploying such complex systems. Hopefully, at the end of this blog, you will know a bit more about finding your way around computervision projects.
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
We also had a number of interesting results on graph neuralnetworks (GNN) in 2022. Relative performance results of three GNN variants ( GCN , APPNP , FiLM ) across 50,000 distinct node classification datasets in GraphWorld. We provided a model-based taxonomy that unified many graph learning methods.
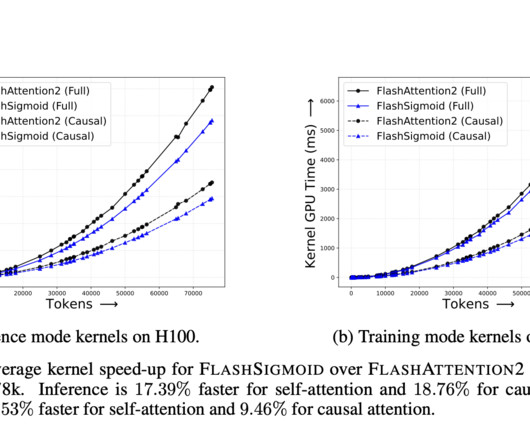
Also, the application of SoftmaxAttn necessitates a row-wise reduction along the input sequence length, which can significantly slow down computations, particularly when using efficient attention kernels. Recent research in machine learning has explored alternatives to the traditional softmax function in various domains.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. Deep learning (DL) models with more layers and parameters perform better in complex tasks like computervision and NLP.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime.
A typical multimodal LLM has three primary modules: The input module comprises specialized neuralnetworks for each specific data type that output intermediate embeddings. An output could be, e.g., a text, a classification (like “dog” for an image), or an image. Examples of different Kosmos-1 tasks.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
This framework can perform classification, regression, etc., but performs very well with neuralnetworks. Keras supports a high-level neuralnetwork API written in Python. Deep Python integration makes it possible to easily create neuralnetwork layers in Python using well-known modules and packages.
For this example, we only use binary classification—does this bag contain a firearm or not? Another obstacle to creating high performing computervision models is that training datasets may not contain sufficient images of the target object with different backgrounds and from different directions. Image Augmentation Examples.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. The platform provides a comprehensive set of annotation tools, including object detection, segmentation, and classification. Robust security functionality.
Classification is very important in machine learning. Hence, we have various classification algorithms in machine learning like logistic regression, support vector machine, decision trees, Naive Bayes classifier, etc. One such classification technique that is near the top of the classification hierarchy is the random forest classifier.
The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. Typical NeuralNetwork architectures take relatively small images (for example, EfficientNetB0 224x224 pixels) as input. Tile embedding Computervision is a complex problem.
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. The literature is most often concerned with this application for classification tasks, rather than natural language generation. to perform well across various datasets for text classification in transformer models.
In this post, we present an approach to develop a deep learning-based computervision model to detect and highlight forged images in mortgage underwriting. We provide guidance on building, training, and deploying deep learning networks on Amazon SageMaker. The model outputs the classification as 1, representing a forged image.
Prime Air (our drones) and the computervision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deep learning. To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters.
These complex models often require hardware acceleration because it enables not only faster training but also faster inference when using deep neuralnetworks in real-time applications. GPUs’ large number of parallel processing cores makes them well-suited for these DL tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content