This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
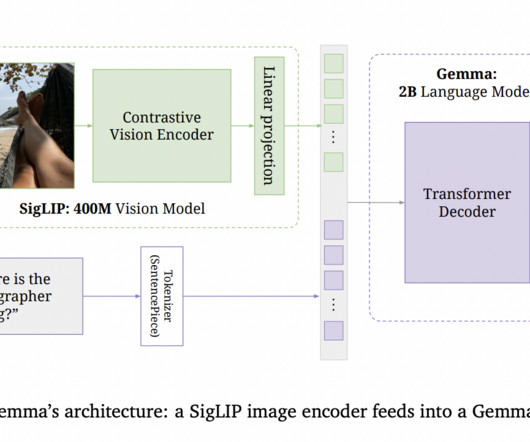
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning. Or requires a degree in computer science?
In this post, we present an approach to develop a deep learning-based computervision model to detect and highlight forged images in mortgage underwriting. In the following sections, we demonstrate the steps for configuring, training, and deploying the computervision model. Set up Amazon SageMaker Studio.
Computervision models have been widely applied to vision-based tactile images due to their inherently visual nature. Researchers have adapted representation learning methods from the vision community, with contrastive learning being popular for developing tactile and visual-tactile representations for specific tasks.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
With over 3 years of experience in designing, building, and deploying computervision (CV) models , I’ve realized people don’t focus enough on crucial aspects of building and deploying such complex systems. Hopefully, at the end of this blog, you will know a bit more about finding your way around computervision projects.
Throughout the course, you’ll progress from basic programming skills to solving complex computervision problems, guided by videos, readings, quizzes, and programming assignments. It covers various aspects, from using larger datasets to preventing overfitting and moving beyond binary classification.
[link] Transfer learning using pre-trained computervision models has become essential in modern computervision applications. In this article, we will explore the process of fine-tuning computervision models using PyTorch and monitoring the results using Comet. Pre-trained models, such as VGG, ResNet.
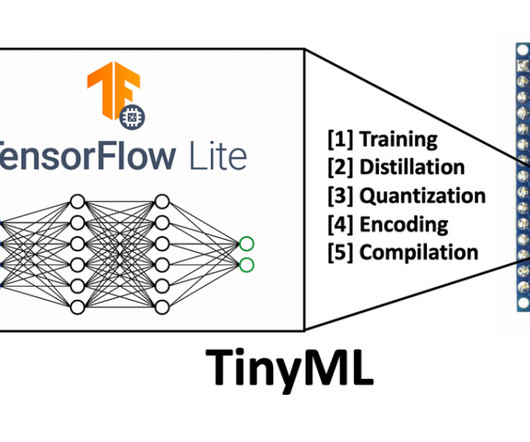
Vision Based Applications TinyML has the potential to play a crucial role in processing computervision based datasets because for faster outputs, these data sets need to be processed on the edge platform itself. The results obtained from the setup were accurate, the design was low-cost, and it delivered satisfactory results.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
These models, known for their success in fields like computervision and NL processing, can revolutionize healthcare by facilitating the translation of vast biomedical data into actionable health outcomes.
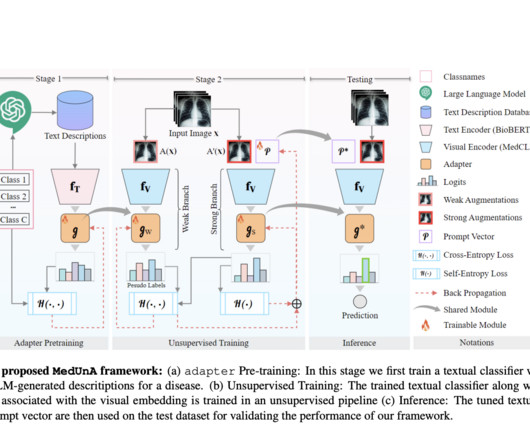
Supervised learning in medical image classification faces challenges due to the scarcity of labeled data, as expert annotations are difficult to obtain. Vision-Language Models (VLMs) address this issue by leveraging visual-text alignment, allowing unsupervised learning, and reducing reliance on labeled data.
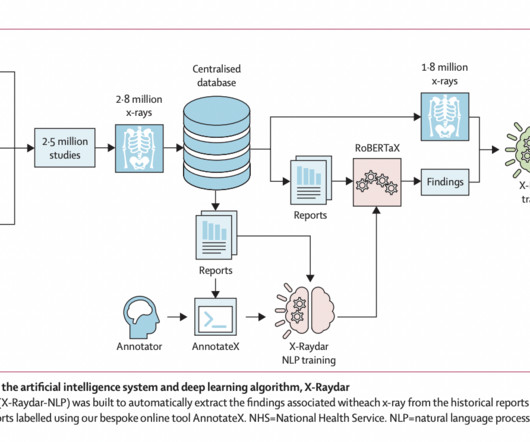
The X-Raydar achieved a mean AUC of 0.919 on the auto-labeled set, 0.864 on the consensus set, and 0.842 on the MIMIC-CXR test. X-Raydar, the computervision algorithm, used InceptionV3 for feature extraction and achieved optimal results using a custom loss function and class weighting factors.
The first generation, exemplified by CLIP and ALIGN, expanded on large-scale classification pretraining by utilizing web-scale data without requiring extensive human labeling. These models used caption embeddings obtained from language encoders to broaden the vocabulary for classification and retrieval tasks.
Based on this classification, it then decides whether to establish boundaries using visual-based shot sequences or audio-based conversation topics. The following example demonstrates a typical chapter-level analysis: [00:00:20;04 00:00:23;01] Automotive, Auto Type The video showcases a vintage urban street scene from the mid-20th century.
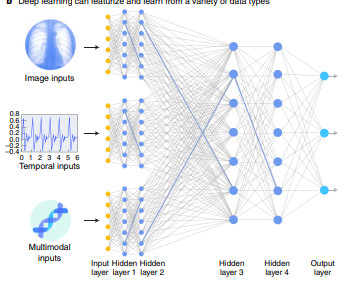
Background of multimodality models Machine learning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computervision, where models can exhibit human-like performance in analyzing and generating content from a single source of data.
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. The pipeline we’re going to talk about now is zero-hit classification.
Leave default settings for VPC , Subnet , and Auto-assign public IP. You can use these services to mount the same models and adapters across multiple instances, facilitating seamless access in environments with auto scaling setups. In Network settings , choose Edit , as shown in the following screenshot.
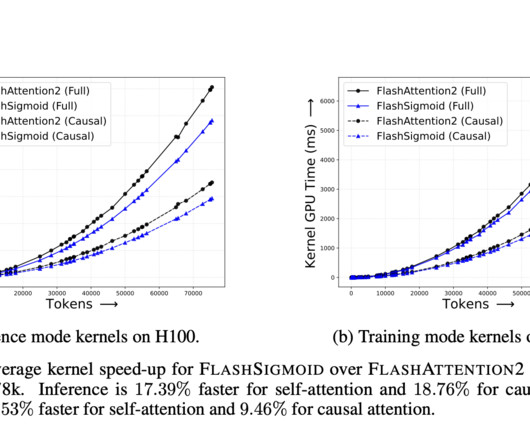
Also, the application of SoftmaxAttn necessitates a row-wise reduction along the input sequence length, which can significantly slow down computations, particularly when using efficient attention kernels. Recent research in machine learning has explored alternatives to the traditional softmax function in various domains.
Use case overview The use case outlined in this post is of heart disease data in different organizations, on which an ML model will run classification algorithms to predict heart disease in the patient. module.eks_blueprints_kubernetes_addons -auto-approve terraform destroy -target=module.m_fedml_edge_client_2.module.eks_blueprints_kubernetes_addons
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes.
The architecture is an auto-regressive architecture, i.e., the model produces one word at a time and then takes in the sequence attached with the predicted word, to predict the next word. Basically, it predicts a word with the context of the previous word.
Deploying Models with AWS SageMaker for HuggingFace Models Harnessing the Power of Pre-trained Models Hugging Face has become a go-to platform for accessing a vast repository of pre-trained machine learning models, covering tasks like natural language processing, computervision, and more. Here’s a breakdown of the key steps: 1.
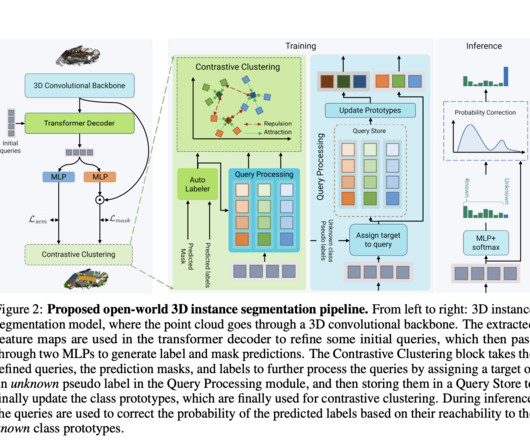
By providing object instance-level classification and semantic labeling, 3D semantic instance segmentation tries to identify items in a given 3D scene represented by a point cloud or mesh. Numerous vision applications, including robots, augmented reality, and autonomous driving, depend on the capacity to segment objects in the 3D space.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computervision and natural language processing. PyTorch supports dynamic computational graphs, enabling network behavior to be changed at runtime.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. threshold – This is a score threshold for determining classification.
Relative performance results of three GNN variants ( GCN , APPNP , FiLM ) across 50,000 distinct node classification datasets in GraphWorld. Structure of auto-bidding online ads system. We find that academic GNN benchmark datasets exist in regions where model rankings do not change.
An output could be, e.g., a text, a classification (like “dog” for an image), or an image. It can perform visual dialogue, visual explanation, visual question answering, image captioning, math equations, OCR, and zero-shot image classification with and without descriptions. Basic structure of a multimodal LLM.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. Deep learning (DL) models with more layers and parameters perform better in complex tasks like computervision and NLP.
By leveraging pre-trained LLMs and powerful vision foundation models (VFMs), the model demonstrates promising performance in discriminative tasks like image-text retrieval and zero classification, as well as generative tasks such as visual question answering (VQA), visual reasoning, image captioning, region captioning/VQA, etc.
Different Graph neural networks tasks [ Source ] Convolution Neural Networks in the context of computervision can be seen as GNNs that are applied to a grid (or graph) of pixels. They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
A guide to performing end-to-end computervision projects with PyTorch-Lightning, Comet ML and Gradio Image by Freepik Computervision is the buzzword at the moment. This is because these projects require a lot of knowledge of math, computer power, and time. This architecture is often used for image classification.
Use SageMaker Feature Store for model training and prediction To use SageMaker Feature store for model training and prediction, open the notebook 5-classification-using-feature-groups.ipynb. For details on model training and inference, refer to the notebook 5-classification-using-feature-groups.ipynb.
For this example, we only use binary classification—does this bag contain a firearm or not? Another obstacle to creating high performing computervision models is that training datasets may not contain sufficient images of the target object with different backgrounds and from different directions. Image Augmentation Examples.
Prime Air (our drones) and the computervision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deep learning. We’ll initially have two Titan models.
In your application, take time to imagine the diverse set of questions available in your images to help your classification or regression task. In social media platforms, photos could be auto-tagged for subsequent use. The enhanced data contains new data features relative to this example use case.
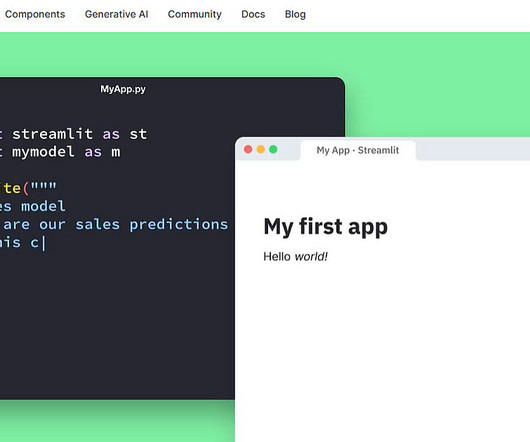
About us: At viso.ai, we’ve built the end-to-end machine learning infrastructure for enterprises to scale their computervision applications easily. Viso Suite, the end-to-end computervision solution What is Streamlit? Computervision and machine learning specialists are not web developers.
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content