This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. The classification process needed to operate with low latency to support Lumis market-leading speed-to-decision commitment. This post is co-written with Paul Pagnan from Lumi.
One of the major focuses over the years of AutoML is the hyperparameter search problem, where the model implements an array of optimization methods to determine the best performing hyperparameters in a large hyperparameter space for a particular machinelearning model. ai, IBM Watson AI, Microsoft AzureML, and a lot more.
Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines. improvement over baseline models.
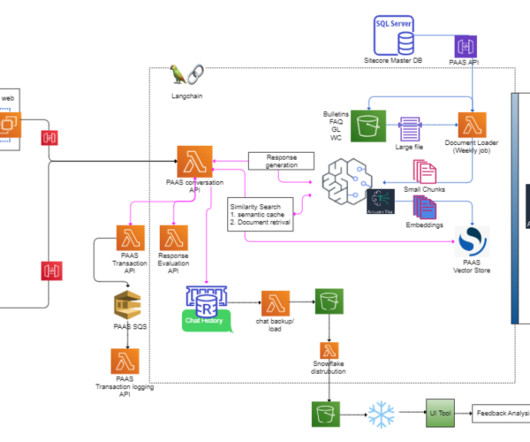
PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation. PAAS offers a wide range of essential services, including more than 40,000 classification guides and more than 500 bulletins. This analysis helps pinpoint specific areas that need improvement.
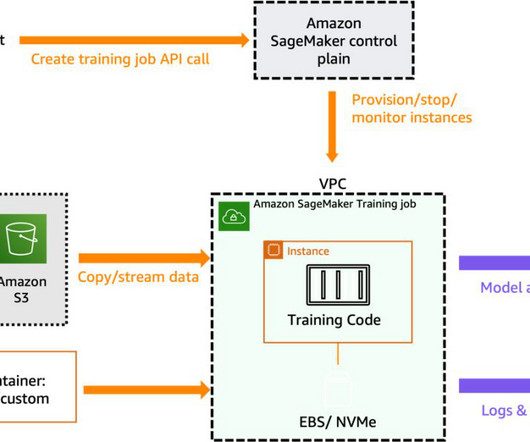
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. Model risk : Risk categorization of the model version.
For Problem type , select Classification. In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. Linear categorical to categorical correlation is not supported. For Analysis name , enter a name. Choose Create.
The custom metadata helps organizations and enterprises categorize information in their preferred way. Amazon Kendra is a highly accurate and easy-to-use enterprise search service powered by MachineLearning (AWS). Custom classification is a two-step process. For example, metadata can be used for filtering and searching.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification.
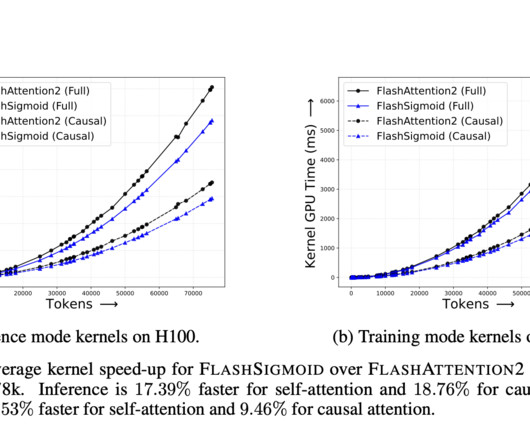
Large Language Models (LLMs) have gained significant prominence in modern machinelearning, largely due to the attention mechanism. Recent research in machinelearning has explored alternatives to the traditional softmax function in various domains.
A typical application of GNN is node classification. The problems that GNNs are used to solve can be divided into the following categories: Node Classification: The goal of this task is to determine the labeling of samples (represented as nodes) by examining the labels of their immediate neighbors (i.e., their neighbors’ labels).
Photo by Ian Taylor on Unsplash This article will comprehensively create, deploy, and execute machinelearning application containers using the Docker tool. It will further explain the various containerization terms and the importance of this technology to the machinelearning workflow. Yes, they do, but partially.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
The Advanced Driver Assistance System (ADAS) is a sis-tiered system that categorizes the different levels of autonomy. A CNN is a neural network with one or more convolutional layers and is used mainly for image processing, classification, segmentation, and other auto-correlated data. Levels of Autonomy. [3] Yann LeCun et al.,
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
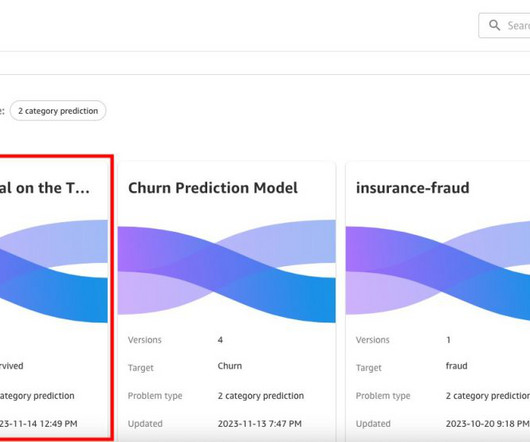
Although machinelearning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machinelearning workflow from data preparation to model deployment. Data preparation The foundation of any machinelearning project is data preparation. The code for this post can be found in the GitHub repo.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. SageMaker provides single model endpoints , which allow you to deploy a single machinelearning (ML) model against a logical endpoint.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos. Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks.
We can categorize human feedback into two types: objective and subjective. Unlike traditional model tasks such as classification, which can be neatly benchmarked on test datasets, assessing the quality of a sprawling conversational agent is highly subjective. Objective vs. subjective human feedback Not all human feedback is the same.
Photo by Scott Webb on Unsplash Determining the value of housing is a classic example of using machinelearning (ML). Machinelearning is capable of incorporating diverse input sources beyond tabular data, such as audio, still images, motion video, and natural language. granite, tile, marble, laminate, etc. 139:5583-5594.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neural network to recognize and classify items in images. A convolutional neural network (CNN) is primarily used for image classification.
These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera. Likewise, according to AWS , inference accounts for 90% of machinelearning demand in the cloud. 2 Calculate the size of the model.
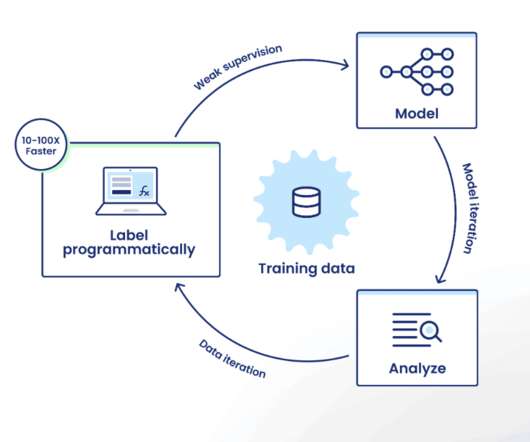
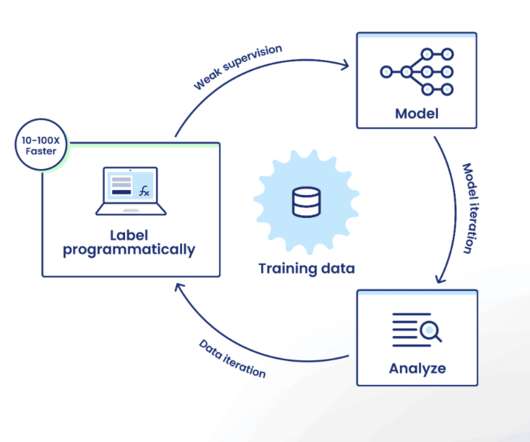
As machinelearning practitioners, few of us would expect the first version of a new model to achieve our objective. In this framework, the machinelearning practitioner experiments with different architectures, engineers features, and tunes hyper-parameters while treating training data as a somewhat static artifact.
As machinelearning practitioners, few of us would expect the first version of a new model to achieve our objective. In this framework, the machinelearning practitioner experiments with different architectures, engineers features, and tunes hyper-parameters while treating training data as a somewhat static artifact.
Almost 90% of the machinelearning models encounter delays and never make it into production. Developing a machinelearning model requires a big amount of training data. Therefore, the data needs to be properly labeled/categorized for a particular use case.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machinelearning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science? Explain it’s working.
The journey began with foundational work in machinelearning, leading to significant contributions that have shaped today’s AI landscape. Today, the computer vision project has gained enormous momentum in mobile applications, automated image annotation tools , and facial recognition and image classification applications.
You can easily try out these models and use them with SageMaker JumpStart, which is a machinelearning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
We’re about to learn how to create a clean, maintainable, and fully reproducible machinelearning model training pipeline. The preprocessing stage involves cleaning, transforming, and encoding the data, making it suitable for machinelearning algorithms. Too good to be true? Not at all.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
Amazon SageMaker Canvas is a no-code workspace that enables analysts and citizen data scientists to generate accurate machinelearning (ML) predictions for their business needs. Optimized for handling categorical variables. Deep learning algorithm: A multilayer perceptron (MLP) and feedforward artificial neural network.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content