This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Verisks Premium Audit Advisory Service (PAAS) is the leading source of technical information and training for premium auditors and underwriters. PAAS helps users classify exposure for commercial casualty insurance, including general liability, commercial auto, and workers compensation.
In an effort to track its advancement towards creating Artificial Intelligence (AI) that can surpass human performance, OpenAI has launched a new classification system. Level 5: Organizations The highest ranking level in OpenAI’s classification is Level 5, or “Organisations.”
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
For Problem type , select Classification. For more information, see AWS managed policy: AmazonSageMakerCanvasAIServicesAccess. For more information, see Model access. Linear categorical to categorical correlation is not supported. Features that are not either numeric or categorical are ignored.
Each node is a structure that contains information such as a person's id, name, gender, location, and other attributes. The information about the connections in a graph is usually represented by adjacency matrices (or sometimes adjacency lists). A typical application of GNN is node classification. their neighbors’ labels).
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Like humans, AVs rely on various sensor technologies to perceive the environment and make logical decisions based on the gathered information. The Advanced Driver Assistance System (ADAS) is a sis-tiered system that categorizes the different levels of autonomy. Yann LeCun et al., Left, Center, and Right Camera Images Example.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
By translating images into text, we unlock and harness the wealth of information contained in visual data. For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. This is where the power of auto-tagging and attribute generation comes into its own.
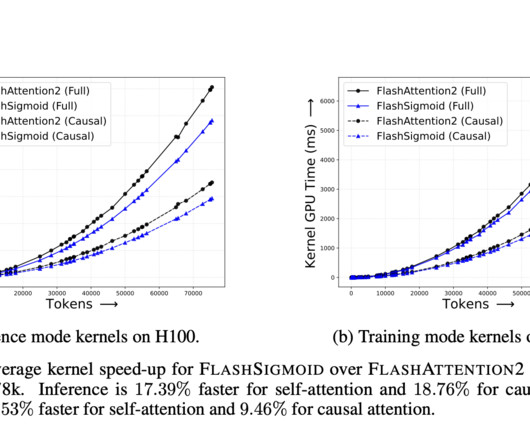
One key issue is the tendency of the softmax function to concentrate attention on a limited number of features, potentially overlooking other informative aspects of the input data. However, despite its widespread adoption and effectiveness, SoftmaxAttn faces several challenges.
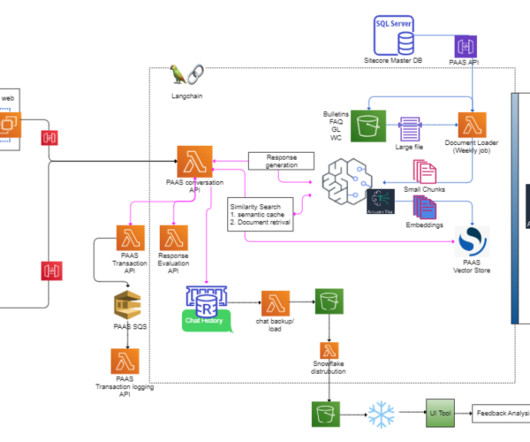
However, when building generative AI applications, you can use an alternative solution that allows for the dynamic incorporation of external knowledge and allows you to control the information used for generation without the need to fine-tune your existing foundational model. license, for use without restrictions.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
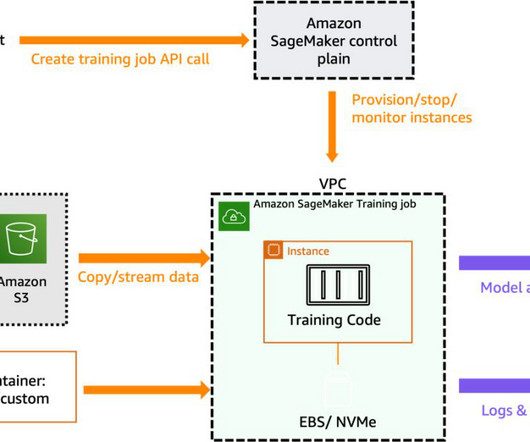
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos. Using Snorkel Flow, Pixability leveraged foundation models to build small, deployable classification models capable of categorizing videos across more than 600 different classes with 90% accuracy in just a few weeks.
With the ability to solve various problems such as classification and regression, XGBoost has become a popular option that also falls into the category of tree-based models. These models have long been used for solving problems such as classification or regression. One of the most popular models available today is XGBoost.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
A significant influence was made by Harrison and Rubinfeld (1978), who published a groundbreaking paper and dataset that became known informally as the Boston housing dataset. A modern approach to a classic use case Home price estimation has traditionally occurred through tabular data where features of the property are used to inform price.
We can categorize human feedback into two types: objective and subjective. Unlike traditional model tasks such as classification, which can be neatly benchmarked on test datasets, assessing the quality of a sprawling conversational agent is highly subjective. Objective vs. subjective human feedback Not all human feedback is the same.
Time series forecasting is a critical component in various industries for making informed decisions by predicting future values of time-dependent data. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
These models have achieved various groundbreaking results in many NLP tasks like question-answering, summarization, language translation, classification, paraphrasing, et cetera. There are other factors that can delay the inference, such as the complexity of the question, the amount of information required to generate a response, et cetera.
Today, the computer vision project has gained enormous momentum in mobile applications, automated image annotation tools , and facial recognition and image classification applications. It synthesizes the information from both the image and prompt encoders to produce accurate segmentation masks.
Therefore, the data needs to be properly labeled/categorized for a particular use case. Text annotation is important as it makes sure that the machine learning model accurately perceives and draws insights based on the provided information. Developing a machine learning model requires a big amount of training data.
Data analytics deals with checking the existing hypothesis and information and answering questions for a better and more effective business-related decision-making process. Long format DataWide-Format DataHere, each row of the data represents the one-time information of a subject. Classification is very important in machine learning.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. For more information about version updates, refer to Shut down and Update Studio Apps. Although this decreases the memory required to store model weights, it degrades the performance due to loss of information.
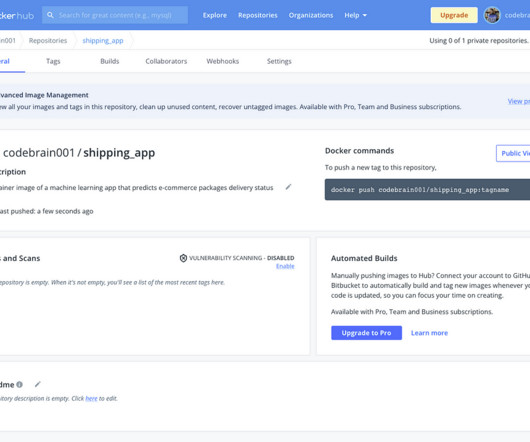
Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application. The data includes the following information: ID: Customer ID number. The dataset has four categorical features, classified into nominal and ordinal.
This step is crucial to ensure that the pipeline has access to relevant and up-to-date information. Common preprocessing tasks include handling missing data, normalization, and categorical encoding. This dataset contains information about passengers on the Titanic, including their survival status. Load the dataset.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues.
A leaderboard allows you to compare key performance metrics (for example, accuracy, precision, recall, and F1 score) for different models’ configurations to identify the best model for your data, thereby improving transparency into model building and helping you make informed decisions on model choices. Otherwise, it chooses ensemble mode.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content