This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI-powered tools have become indispensable for automating tasks, boosting productivity, and improving decision-making. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
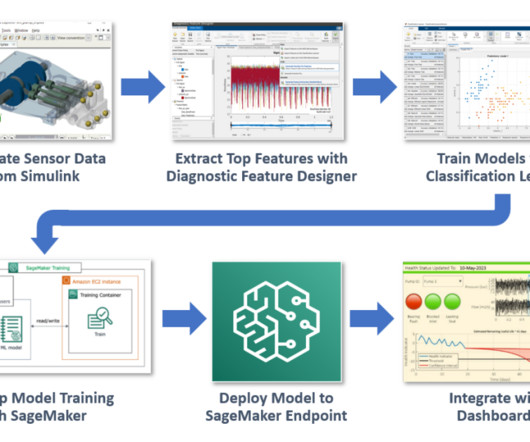
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificial intelligence. Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example.
This requires not only well-designed features and ML architecture, but also data preparation and ML pipelines that can automate the retraining process. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. AutoGluon is a toolkit for automated machine learning (AutoML).
By establishing standardized workflows, automating repetitive tasks, and implementing robust monitoring and governance mechanisms, MLOps enables organizations to accelerate model development, improve deployment reliability, and maximize the value derived from ML initiatives.
As a result of these technological advancements, the manufacturing industry has set its sights on artificial intelligence and automation to enhance services through efficiency gains and lowering operational expenses. These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. and Pandas or Apache Spark DataFrames.
Low-Code PyCaret: Let’s start off with a low-code open-source machine learning library in Python. H2O AutoML: A powerful tool for automating much of the more tedious and time-consuming aspects of machine learning, H2O AutoML provides the user(s) with a set of algorithms and tools to automate the entirety of the machine learning workflow.
Amazon SageMaker Inference Recommender is a capability of Amazon SageMaker that reduces the time required to get ML models in production by automating load testing and model tuning across SageMaker ML instances. We train an XGBoost model for a classification task on a credit card fraud dataset.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code. Enter a name for your endpoint.
These generative AI applications are not only used to automate existing business processes, but also have the ability to transform the experience for customers using these applications. LangChain is an open source Python library designed to build applications with LLMs. license, for use without restrictions.
It supports languages like Python and R and processes the data with the help of data flow graphs. This framework can perform classification, regression, etc., It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. It is an open source framework. Very difficult to find errors.
New algorithms/software can help you systematically curate your data via automation. With one line of Python code, cleanlab allows you to automatically detect common data issues in almost any dataset (image, text, tabular, audio, etc.) Getting Started with Cleanlab Cleanlab is a Python library built specifically for data-centric AI.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language. Auto-scale compute.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. eks-create.sh This will create one instance of each type.
For text classification, however, there are many similarities. Snorkel Flow’s data-centric AI development loop Programmatic Labeling Programmatic labeling is a method for generating data labels in an automated or semi-automated manner. Modeling Snorkel Flow offers two ways to train models: in-app or via the Python SDK.
Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries. Using Lightning, you can automate your training tasks, such as model building, data loading, model checkpointing, and logging. This architecture is often used for image classification.
The quickstart widget auto-generates a starter config for your specific use case and setup You can use the quickstart widget or the init config command to get started. The config can be loaded as a Python dict. Automated checks and validation. The config is grouped into sections, and nested sections are defined using the.
One way to solve Data Science’s challenges in Data Cleaning and pre-processing is to enable Artificial Intelligence technologies like Augmented Analytics and Auto-feature Engineering. Adopting AI-enabled Data Science technologies will help automate manual data cleaning and ensure that Data Scientists become more productive.
The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. That’s why the clinic wants to harness the power of deep learning in a bid to help healthcare professionals in an automated way. The lines are then parsed into pythonic dictionaries.
A day or two after some big research lab announces a state-of-the-art result on classifying images, extracting information from text, or detecting cyber attacks, you can go find that same model and replicate those state-of-the-art results with a couple lines of Python code and an internet connection. This could be something really simple.
A day or two after some big research lab announces a state-of-the-art result on classifying images, extracting information from text, or detecting cyber attacks, you can go find that same model and replicate those state-of-the-art results with a couple lines of Python code and an internet connection. This could be something really simple.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The Petfinder team at Purina wants an automated solution that they can deploy with minimal maintenance. The deployment based on the AWS CDK deploys a Step Functions workflow to automate the training and deployment process.
Now you can also fine-tune 7 billion, 13 billion, and 70 billion parameters Llama 2 text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
Efficiency: Pipelines automate repetitive tasks, reducing manual intervention and saving time. Metrics such as accuracy, precision, recall, or F1-score can be employed to assess how well the model generalizes to new (unseen data) in classification problems. We will use Python and the popular Scikit-learn.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. The model outputs the classification as 0, representing an untampered image.
For instance, a financial firm that needs to auto-generate a daily activity report for internal circulation using all the relevant transactions can customize the model with proprietary data, which will include past reports, so that the FM learns how these reports should read and what data was used to generate them.
Most employees don’t master the conventional data science toolkit (SQL, Python, R etc.). It not only requires SQL mastery on the part of the annotator, but also more time per example than more general linguistic tasks such as sentiment analysis and text classification.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content