This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Several research environments have been developed to automate the research process partially. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In sentiment classification, DOLPHIN improved accuracy by 1.5%
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. We train an XGBoost model for a classification task on a credit card fraud dataset. We demonstrate how to set up Inference Recommender jobs for a credit card fraud detection use case.
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Automation can significantly improve efficiency and reduce errors. Auto-generated audit logs : Record data interactions to understand how employees use data.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. Along with protecting against toxicity and harmful content, it can also be used for Automated Reasoning checks , which helps you protect against hallucinations.
Businesses are increasingly embracing data-intensive workloads, including high-performance computing, artificial intelligence (AI) and machine learning (ML). This situation triggered an auto-scaling rule set to activate at 80% CPU utilization. Due to the auto-scaling of the new EC2 instances, an additional t2.large
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. This post illustrates how you can automate and simplify metadata generation using custom models by Amazon Comprehend. Custom classification is a two-step process.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. and Pandas or Apache Spark DataFrames.
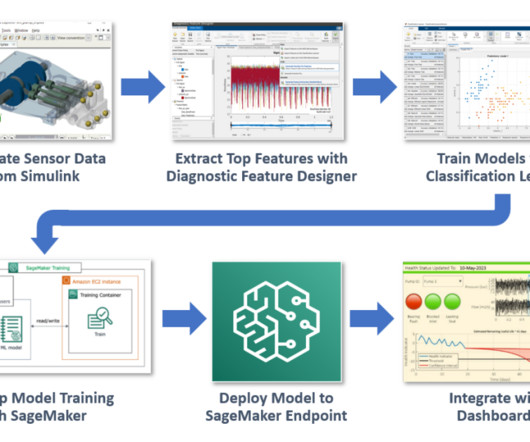
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificial intelligence. Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification.
A guide to performing end-to-end computer vision projects with PyTorch-Lightning, Comet ML and Gradio Image by Freepik Computer vision is the buzzword at the moment. Today, I’ll walk you through how to implement an end-to-end image classification project with Lightning , Comet ML, and Gradio libraries.
For any machine learning (ML) problem, the data scientist begins by working with data. Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. Google Research has been at the forefront of this effort, developing many innovations from privacy-safe recommendation systems to scalable solutions for large-scale ML. Structure of auto-bidding online ads system.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. Automatic node replacement – A monitoring agent performs managed, lightweight, and noninvasive checks, coupled with automated node replacement capability.
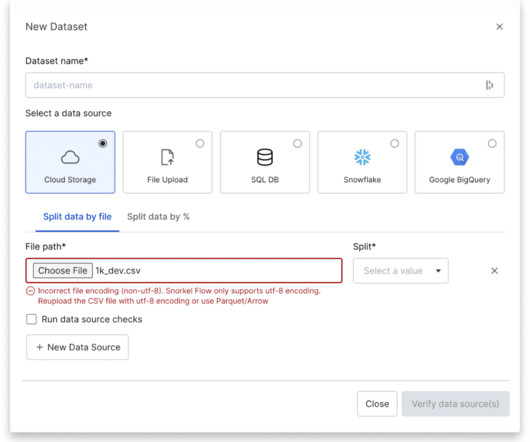
Rapid, model-guided iteration with New Studio for all core ML tasks. Enhanced studio experience for all core ML tasks. Enhanced new studio experience Snorkel Flow now supports all ML tasks through a single interface via our new Snorkel Flow Studio experience. Programmatic labeling with support for complex tasks and data types.
Codify Operations for Efficiency and Reproducibility By performing operations as code and incorporating automated deployment methodologies, organizations can achieve scalable, repeatable, and consistent processes. Build and release optimization – This area emphasizes the implementation of standardized DevSecOps processes.
This framework can perform classification, regression, etc., Most of the organizations make use of Caffe in order to deal with computer vision and classification related problems. Theano Theano is one of the fastest and simplest ML libraries, and it was built on top of NumPy. It is an open source framework.
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. For Problem type , select Classification. Then we train, build, test, and deploy the model using SageMaker Canvas, without writing any code. Choose Create.
H2O AutoML: A powerful tool for automating much of the more tedious and time-consuming aspects of machine learning, H2O AutoML provides the user(s) with a set of algorithms and tools to automate the entirety of the machine learning workflow. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
As a result of these technological advancements, the manufacturing industry has set its sights on artificial intelligence and automation to enhance services through efficiency gains and lowering operational expenses. These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Most cybersecurity tools leverage machine learning (ML) models that present several shortcomings to security teams when it comes to preventing threats. ML solutions also require heavy human intervention and are trained on small data sets, exposing them to human bias and error. Like other AI and ML models, our model trains on data.
These generative AI applications are not only used to automate existing business processes, but also have the ability to transform the experience for customers using these applications. There was no monitoring, load balancing, auto-scaling, or persistent storage at the time.
Evaluating this faithfulness, which also serves to measure the presence of hallucinated content, in an automated manner is non-trivial, especially for open-ended responses. Evaluating RAG systems at scale requires an automated approach to extract metrics that are quantitative indicators of its reliability.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
New algorithms/software can help you systematically curate your data via automation. In this post, I’ll give a high-level overview of how AI/ML can be used to automatically detect various issues common in real-world datasets. Steps to practice data-centric AI Train the initial ML model on the original dataset.
Photo by Scott Webb on Unsplash Determining the value of housing is a classic example of using machine learning (ML). Almost 50 years later, the estimation of housing prices has become an important teaching tool for students and professionals interested in using data and ML in business decision-making.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from data preparation to model deployment. It provides a straightforward way to create high-quality models tailored to your specific problem type, be it classification, regression, or forecasting, among others.
Most, if not all, machine learning (ML) models in production today were born in notebooks before they were put into production. DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. W&B Sweeps will automate this kind of exploration.
For text classification, however, there are many similarities. Snorkel Flow’s data-centric AI development loop Programmatic Labeling Programmatic labeling is a method for generating data labels in an automated or semi-automated manner. This may require extensive customization and fine-tuning of the model.
Likewise, almost 80% of AI/ML projects stall at some stage before deployment. Companies can use high-quality human-powered data annotation services to enhance ML and AI implementations. Also, ML and AI models need voluminous amounts of labeled data to learn from. – It offers documentation and live demos for ease of use.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computer vision projects. Then we are there to help.
This article will walk you through how to process large medical images efficiently using Apache Beam — and we’ll use a specific example to explore the following: How to approach using huge images in ML/AI Different libraries for dealing with said images How to create efficient parallel processing pipelines Ready for some serious knowledge-sharing?
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. And so this leads to this constant iteration of labeling and relabeling and reshaping and redeveloping the data that fuels and determines ML models.
His presentation also highlights the ways that Snorkel’s platform, Snorkel Flow, enables users to rapidly and programmatically label and develop datasets and then use them to train ML models. And so this leads to this constant iteration of labeling and relabeling and reshaping and redeveloping the data that fuels and determines ML models.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
Complete ML model training pipeline workflow | Source But before we delve into the step-by-step model training pipeline, it’s essential to understand the basics, architecture, motivations, challenges associated with ML pipelines, and a few tools that you will need to work with. It makes the training iterations fast and trustable.
You can easily try out these models and use them with SageMaker JumpStart, which is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Solutions Architect in the ML Frameworks Team. The following diagram shows the solution architecture.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content