This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Several research environments have been developed to automate the research process partially. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process. In sentiment classification, DOLPHIN improved accuracy by 1.5%
According to the recent statistics released by a local auto industry association, the sales of China’s fuel vehicle market have declined for three consecutive years. The auto parts manufacturers caught in it are facing the problem of how to survive and grow against the increasingly fierce competition.
Amazon Bedrock Data Automation (BDA) is a new managed feature powered by FMs in Amazon Bedrock. Based on this classification, it then decides whether to establish boundaries using visual-based shot sequences or audio-based conversation topics. In this post, were introducing an even simpler way to build contextual advertising solutions.
AI-powered tools have become indispensable for automating tasks, boosting productivity, and improving decision-making. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Automation can significantly improve efficiency and reduce errors. Auto-generated audit logs : Record data interactions to understand how employees use data.
However, to achieve this transformation successfully, it is crucial to incorporate a hybrid cloud management platform that prioritizes AI-infused automation. Start with a platform-centric approach Standardization is crucial for organizations looking to automate and modernize.
This situation triggered an auto-scaling rule set to activate at 80% CPU utilization. Due to the auto-scaling of the new EC2 instances, an additional t2.large Implement rules-based automation to take corrective actions, such as deleting idle VMs and associated resources that no longer serve business functions.
In an effort to track its advancement towards creating Artificial Intelligence (AI) that can surpass human performance, OpenAI has launched a new classification system. Level 5: Organizations The highest ranking level in OpenAI’s classification is Level 5, or “Organisations.”
The brand might be willing to absorb the higher costs of using a more powerful and expensive FMs to achieve the highest-quality classifications, because misclassifications could lead to customer dissatisfaction and damage the brands reputation. Consider another use case of generating personalized product descriptions for an ecommerce site.
At the end of the day, why not use an AutoML package (Automated Machine Learning) or an Auto-Forecasting tool and let it do the job for you? After implementing our changes, the demand classification pipeline reduces the overall error in our forecasting process by approx. But what does this look like in practice?
This requires not only well-designed features and ML architecture, but also data preparation and ML pipelines that can automate the retraining process. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. AutoGluon is a toolkit for automated machine learning (AutoML).
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. This post illustrates how you can automate and simplify metadata generation using custom models by Amazon Comprehend. Custom classification is a two-step process.
Automation isn’t here to steal your job. Which begs the question: what tasks could you automate with the right technology? Lead generation and paperwork approval are two areas with proven solutions, while optical character recognition software is transforming how businesses approach document classification. — ‘Optical… what?’
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificial intelligence. Our objective is to demonstrate the combined power of MATLAB and Amazon SageMaker using this fault classification example.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The Petfinder team at Purina wants an automated solution that they can deploy with minimal maintenance. The deployment based on the AWS CDK deploys a Step Functions workflow to automate the training and deployment process.
They’re actively creating the future of automation in what’s known as Robotic Process Automation 2.0. Source: Grand View Research What is Robotic Process Automation (RPA)? let’s first explain basic Robotic Process Automation. used Robotic Process Automation 2.0 But that’s not all they’re doing. Happy reading!
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. After a blueprint is configured, it can be used to create consistent environments across multiple AWS accounts and Regions using continuous deployment automation.
Agentic AI is transforming insurance claims processing, enabling automation, scalability, and cost efficiency. Attendees will gain insights into building and scaling AI-powered claims automation with advanced engineering, responsible AI, and efficient infrastructure.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning. Its a simple endpoint that returns a JSON response.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. It’s a binary classification problem where the goal is to predict whether a customer is a credit risk.
By establishing standardized workflows, automating repetitive tasks, and implementing robust monitoring and governance mechanisms, MLOps enables organizations to accelerate model development, improve deployment reliability, and maximize the value derived from ML initiatives.
As a result of these technological advancements, the manufacturing industry has set its sights on artificial intelligence and automation to enhance services through efficiency gains and lowering operational expenses. These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes.
Relative performance results of three GNN variants ( GCN , APPNP , FiLM ) across 50,000 distinct node classification datasets in GraphWorld. Structure of auto-bidding online ads system. Structure of auto-bidding online ads system. We find that academic GNN benchmark datasets exist in regions where model rankings do not change.
LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction. Figure 1: Customer review and response The example application in this post automates the process of responding to customer reviews.
The introduction of generative AI provides another opportunity for Thomson Reuters to work with customers and advance how they do their work, helping professionals draw insights and automate workflows, enabling them to focus their time where it matters most. The extension makes sure that the job waits and restarts after the node is replaced.
H2O AutoML: A powerful tool for automating much of the more tedious and time-consuming aspects of machine learning, H2O AutoML provides the user(s) with a set of algorithms and tools to automate the entirety of the machine learning workflow. Auto-ViML : Like PyCaret, Auto-ViML is an open-source machine learning library in Python.
For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. CLIP model CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification.
Leveraging foundation models for enterprise AI Despite the break-neck progress on the foundation model front with ChatGPT, BARD, GPT-4, LLaMA, and more, the enterprise adoption for predictive AI use cases, e.g. fraud detection, patient risk assessment, document processing automation, and more, remains slow.
But from an ML standpoint, both can be construed as binary classification models, and therefore could share many common steps from an ML workflow perspective, including model tuning and training, evaluation, interpretability, deployment, and inference. The final outcome is an auto scaling, robust, and dynamically monitored solution.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
SageMaker provides automated model tuning , which manages the undifferentiated heavy lifting of provisioning and managing compute infrastructure to run several iterations and select the optimized model candidate from training. Best Egg trains multiple credit models using classification and regression algorithms.
Evaluating this faithfulness, which also serves to measure the presence of hallucinated content, in an automated manner is non-trivial, especially for open-ended responses. Evaluating RAG systems at scale requires an automated approach to extract metrics that are quantitative indicators of its reliability.
Codify Operations for Efficiency and Reproducibility By performing operations as code and incorporating automated deployment methodologies, organizations can achieve scalable, repeatable, and consistent processes. Build and release optimization – This area emphasizes the implementation of standardized DevSecOps processes.
For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model. These endpoints are fully managed and support auto scaling.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al. Good Data from Bad Models: Foundations of Threshold-based Auto-labeling Vishwakarma et al.
These generative AI applications are not only used to automate existing business processes, but also have the ability to transform the experience for customers using these applications. There was no monitoring, load balancing, auto-scaling, or persistent storage at the time.
For Problem type , select Classification. In the following example, we drop the columns Timestamp, Country, state, and comments, because these features will have least impact for classification of our model. For Training method , select Auto. To learn about automating batch predictions, refer to Automate batch predictions.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification Guha et al. A case for reframing automated medical image classification as segmentation Hooper et al. Good Data from Bad Models: Foundations of Threshold-based Auto-labeling Vishwakarma et al.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code. Enter a name for your endpoint.
Artificial intelligence (AI) can accelerate inspections by automating some reviews and prioritizing others, and unlike humans at the end of a long shift, an AI’s performance does not degrade over time. For this example, we only use binary classification—does this bag contain a firearm or not? Examples of X ray images with firearms.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
New algorithms/software can help you systematically curate your data via automation. For more complex issues like label errors, you can again simply filter out all the auto-detected bad data. Don’t think you have to manually do all of the data curation work yourself!
In the first part of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. The model outputs the classification as 0, representing an untampered image.
Once the repository is ready, we build datasets using all file types with malicious and benign classifications along with other metadata. We utilize all of the benefits that containers offer, including massive auto-scaling on demand, resiliency, low latency, and easy upgrades.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























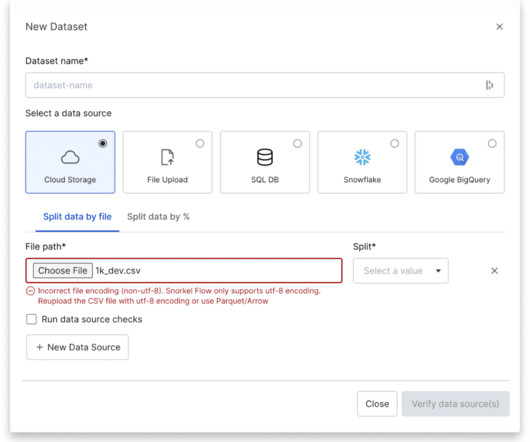


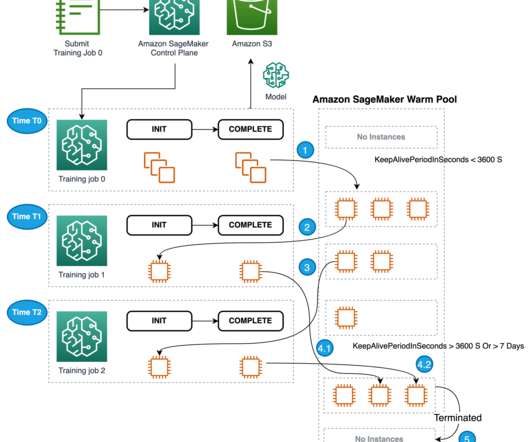



















Let's personalize your content