This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
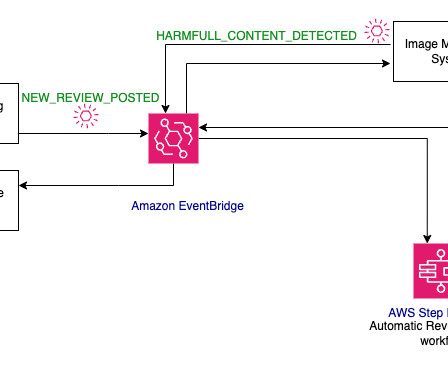
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
However, the sharing of raw, non-sanitized sensitive information across different locations poses significant security and privacy risks, especially in regulated industries such as healthcare. Insecure networks lacking access control and encryption can still expose sensitive information to attackers.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning. We Made It!
Each node is a structure that contains information such as a person's id, name, gender, location, and other attributes. The information about the connections in a graph is usually represented by adjacency matrices (or sometimes adjacency lists). A typical application of GNN is node classification. their neighbors’ labels).
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. Start the model version when training is complete.
However, when building generative AI applications, you can use an alternative solution that allows for the dynamic incorporation of external knowledge and allows you to control the information used for generation without the need to fine-tune your existing foundational model. license, for use without restrictions.
Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application. Googles PaLM-E additionally handles information about a robots state and surroundings. The output module generates outputs based on the task and the processed information.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. Following are the steps completed by using APIs to create and share a model package group across accounts.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering. Most of this process is the same for any binary classification except for the feature engineering step.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Complete the following steps: Choose Prepare and analyze data. Complete the following steps: Choose Run Data quality and insights report. Choose Create. Choose Create.
Another challenge is the need for an effective mechanism to handle cases where no useful information can be retrieved for a given input. Consequently, you may face difficulties in making informed choices when selecting the most appropriate RAG approach that aligns with your unique use case requirements.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. They are professionals with discerning information needs in legal, corporate, tax, risk, fraud, compliance, and news domains. 55 440 0.1
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction. A prompt is the information you pass into an LLM to elicit a response. For most reviews, the system auto-generates a reply using an LLM.
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. Note that although the MMS configurations don’t apply in this case, the policy considerations still do.)
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
For more information about prerequisites, see Get Started with Data Wrangler. Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs. It gives you information such as the number of missing values and the number of outliers. This is a one-time setup.
These techniques are based on years of research from my team, investigating what sorts of data problems can be detected algorithmically using information from a trained model. If you properly utilize the information it has captured about your data, your ML model can help decide which data/annotations would be most informative to collect.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). In such cases, we might not always have a complete sequence we are mapping to/from.
Complex, information-seeking tasks. Transform modalities, or translate the world’s information into any language. Using a variety of code completion suggestions from a 500 million parameter language model for a cohort of 10,000 Google software developers using this model in their IDE, we’ve seen that 2.6% All kinds of tasks.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created. For more information, refer to Requesting a quota increase. trillion token dataset primarily consisting of web data from RefinedWeb with 11 billion parameters.
We train an XGBoost model for a classification task on a credit card fraud dataset. Model Framework XGBoost Model Size 10 MB End-to-End Latency 100 milliseconds Invocations per Second 500 (30,000 per minute) ML Task Binary Classification Input Payload 10 KB We use a synthetically created credit card fraud dataset.
In this release, we’ve focused on simplifying model sharing, making advanced features more accessible with FREE access to Zero-shot NER prompting, streamlining the annotation process with completions and predictions merging, and introducing Azure Blob backup integration. Click “Submit” to finalize.
Unlike traditional model tasks such as classification, which can be neatly benchmarked on test datasets, assessing the quality of a sprawling conversational agent is highly subjective. Launch SageMaker Studio Complete the following steps to launch SageMaker Studio: On the SageMaker console, choose Studio in the navigation pane.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
Time series forecasting is a critical component in various industries for making informed decisions by predicting future values of time-dependent data. In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion.
Can you see the complete model lineage with data/models/experiments used downstream? Can you debug system information? Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. Is it fast and reliable enough for your workflow?
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. Auto-scale compute. In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells.
A significant influence was made by Harrison and Rubinfeld (1978), who published a groundbreaking paper and dataset that became known informally as the Boston housing dataset. A modern approach to a classic use case Home price estimation has traditionally occurred through tabular data where features of the property are used to inform price.
Artificial intelligence (AI) has introduced new dynamics in the information and communication technology space. According to OpenAI , “Over 300 applications are delivering GPT-3–powered search, conversation, text completion, and other advanced AI features through our API.” I am here to convince you not to worry. Believe me.”.
For example, each log is written in the format of timestamp, user ID, and event information. To solve this problem, we make the ML solution auto-deployable with a few configuration changes. In our case, we used AutoGluon with SageMaker to realize a two-stage prediction, including churn classification and lifetime value regression.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. For more information about version updates, refer to Shut down and Update Studio Apps. Write a response that appropriately completes the request.nn### Instruction:nWhen did Felix Luna die?nn###
The choice of how to encode positional information for transformers has been one of the key components of LLM architectures. LLMs are powerful but expensive to run, and generating responses or code auto-completion can quickly accumulate costs, especially when serving many users.
Machine learning extracts hidden information and insights from big data using statistical methods and techniques. It will assist the users and executives in identifying important information that is extracted from data. st.info() – function that displays an informational message, e.g. via pop-up window.
For example, access to timely, accurate health information is a significant challenge among women in rural and densely populated urban areas across India. To solve this challenge, ARMMAN developed mMitra , a free mobile service that sends preventive care information to expectant and new mothers. Pfam-NUniProt2 A set of 6.8
Life however decided to take me down a different path (partly thanks to Fujifilm discontinuing various films ), although I have never quite completely forgotten about glamour photography. Safety Checker —classification model that screens outputs for potentially harmful content. Image created by the author. Image created by the author.
Financial market participants are faced with an overload of information that influences their decisions, and sentiment analysis stands out as a useful tool to help separate out the relevant and meaningful facts and figures. script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources.
Then you can use the model to perform tasks such as text generation, classification, and translation. build_info = dr.CustomModelVersionDependencyBuild.start_build( custom_model_id=custom_model.id, custom_model_version_id=latest_version.id, max_wait=3600, ) print(f"Environment build completed with {build_info.build_status}.")
Today, the computer vision project has gained enormous momentum in mobile applications, automated image annotation tools , and facial recognition and image classification applications. It synthesizes the information from both the image and prompt encoders to produce accurate segmentation masks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content