This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. Let me explain. Our model gets a prompt and auto-completes it.
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Complete the following steps: Choose Prepare and analyze data. Complete the following steps: Choose Run Data quality and insights report. Choose Create. Choose Create.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. We explain the metrics and show techniques to deal with data to obtain better model performance. The F1 score provides a balanced evaluation of the model’s performance.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself.
Along with text generation it can also be used to text classification and text summarization. The auto-complete feature on your smartphone is based on this principle. When you type “how”, the auto-complete will suggest words like “to” or “are”. That’s the precise difference between GPT-3 and its predecessors.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. Can you see the complete model lineage with data/models/experiments used downstream? The platform provides a comprehensive set of annotation tools, including object detection, segmentation, and classification.
A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings. Skip the preamble or explanation, and provide the classification. Skip any preamble or explanation, and provide the classification.
In this article, we’ll focus on this concept: explaining the term and sharing an example of how we’ve used the technology at DLabs.AI. let’s first explain basic Robotic Process Automation. in action is from a project we completed here at DLabs.AI. Happy reading! The RPA market is currently valued at USD 1.1 from 2020 to 2027.
We’ll walk through the data preparation process, explain the configuration of the time series forecasting model, detail the inference process, and highlight key aspects of the project. In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. Auto-scale compute. In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells.
An output could be, e.g., a text, a classification (like “dog” for an image), or an image. It can perform visual dialogue, visual explanation, visual question answering, image captioning, math equations, OCR, and zero-shot image classification with and without descriptions. Basic structure of a multimodal LLM.
Then you can use the model to perform tasks such as text generation, classification, and translation. build_info = dr.CustomModelVersionDependencyBuild.start_build( custom_model_id=custom_model.id, custom_model_version_id=latest_version.id, max_wait=3600, ) print(f"Environment build completed with {build_info.build_status}.")
Michal, to warm you up for all this question-answering, how would you explain to us managing computer vision projects in one minute? You would address it in a completely different way, depending on what’s the problem. Michal: As I explained at some point to me, I wouldn’t say it’s much more complex.
There will be a lot of tasks to complete. This is the link [8] to the article about this Zero-Shot Classification NLP. BART stands for Bidirectional and Auto-Regression, and is used in processing human languages that is related to sentences and text. Are you ready to explore? Let’s begin! The approach was proposed by Yin et al.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. Data formats like image, video, text, etc.,
Once the exploratory steps are completed, the cleansed data is subjected to various algorithms like predictive analysis, regression, text mining, recognition patterns, etc depending on the requirements. Define and explain selection bias? It is the discounting of those subjects that did not complete the trial.
The Mayo Clinic sponsored the Mayo Clinic – STRIP AI competition focused on image classification of stroke blood clot origin. We can well explain this in a cancer detection example. Training Convolutional Neural Networks for image classification is time and resource-intensive. The model is trained on bags of observations.
Embeddings are essential for LLMs to understand natural language, enabling them to perform tasks like text classification, question answering, and more. Combine this with the serverless BentoCloud or an auto-scaling group on a cloud platform like AWS to ensure your resources match the demand.
It will further explain the various containerization terms and the importance of this technology to the machine learning workflow. Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Write a response that appropriately completes the request.nn### Instruction:nWhen did Felix Luna die?nn### Write a response that appropriately completes the request.nn### Instruction:nWhat is an egg laying mammal?nn###
This article focuses on auto-regressive models, but these methods are applicable to other architectures and tasks as well. input saliency is a method that explains individual predictions. The literature is most often concerned with this application for classification tasks, rather than natural language generation.
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. However, explaining why that decision was made requires next-level detailed reports from each affected model component of that AI system. It can take up to 20 minutes for the setup to complete.
Complete ML model training pipeline workflow | Source But before we delve into the step-by-step model training pipeline, it’s essential to understand the basics, architecture, motivations, challenges associated with ML pipelines, and a few tools that you will need to work with. Log the classification report and confusion matrix.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. Please explain the main clinical purpose of such image?Can
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. instance_type="ml.trn1n.32xlarge",
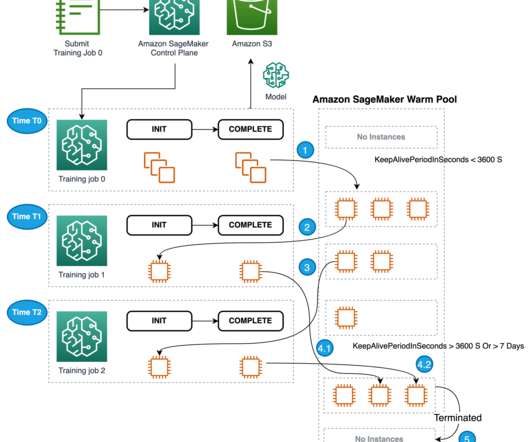
Best Egg trains multiple credit models using classification and regression algorithms. The trained model artifact is hosted on a SageMaker real-time endpoint using the built-in auto scaling and load balancing features. After the first training job is complete, the instances used for training are retained in the warm pool cluster.
On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax. 3] provides a more complete survey of Text2SQL data augmentation techniques.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















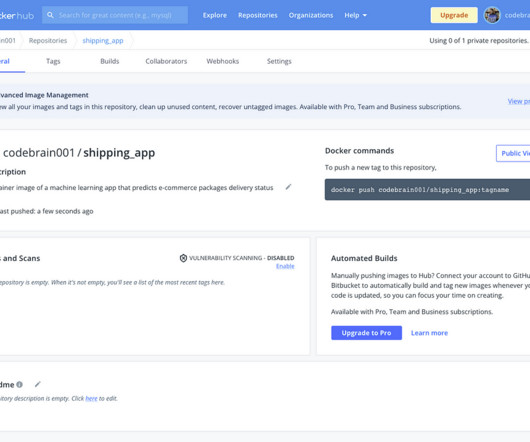













Let's personalize your content