This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
Jump Right To The Downloads Section Building on FastAPI Foundations In the previous lesson , we laid the groundwork for understanding and working with FastAPI. Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Looking for the source code to this post?
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Use case overview The use case outlined in this post is of heart disease data in different organizations, on which an ML model will run classification algorithms to predict heart disease in the patient. Choose the Training Status tab and wait for the training run to complete. You can also download these models from the website.
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. Next, when creating the classifier object, the model was downloaded.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. yaml locally.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Complete the following steps: Choose Prepare and analyze data. Upload the dataset you downloaded in the prerequisites section. For Problem type , select Classification.
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. Note that although the MMS configurations don’t apply in this case, the policy considerations still do.)
Another option is to downloadcomplete data for your ML model training use cases using SageMaker Data Wrangler processing jobs. After you check out the data type matching applied by SageMaker Data Wrangler, complete the following steps: Choose the plus sign next to Data types and choose Add analysis. This is a one-time setup.
In this release, we’ve focused on simplifying model sharing, making advanced features more accessible with FREE access to Zero-shot NER prompting, streamlining the annotation process with completions and predictions merging, and introducing Azure Blob backup integration. With the 5.4 substantially upgrades our annotation capabilities.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
In short: RPA is a set of algorithms that integrate different applications, simplifying mundane, monotonous, and repetitive tasks; these include switching between applications, logging into a system, downloading files, and copying data. in action is from a project we completed here at DLabs.AI. used Robotic Process Automation 2.0
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. Auto-scale compute. In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells.
Life however decided to take me down a different path (partly thanks to Fujifilm discontinuing various films ), although I have never quite completely forgotten about glamour photography. Safety Checker —classification model that screens outputs for potentially harmful content. Image created by the author.
According to OpenAI , “Over 300 applications are delivering GPT-3–powered search, conversation, text completion, and other advanced AI features through our API.” With limited input text and supervision, GPT-3 auto-generated a complete essay using conversational language peculiar to humans. Download now. Believe me.”.
Can you see the complete model lineage with data/models/experiments used downstream? Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. Is it accessible from your language/framework/infrastructure, framework, or infrastructure?
We selected the model with the most downloads at the time of this writing. In your application, take time to imagine the diverse set of questions available in your images to help your classification or regression task. In social media platforms, photos could be auto-tagged for subsequent use.
Hugging Face model hub is a platform offering a collection of pre-trained models that can be easily downloaded and used for a wide range of natural language processing tasks. Then you can use the model to perform tasks such as text generation, classification, and translation. Install dependencies !pip pip install transformers==4.25.1
Read more Benchmarks Download trained pipelines New trained pipelines spaCy v3.0 Download pipelines New training workflow and config system spaCy v3.0 The quickstart widget auto-generates a starter config for your specific use case and setup You can use the quickstart widget or the init config command to get started.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Write a response that appropriately completes the request.nn### Instruction:nWhen did Felix Luna die?nn### Write a response that appropriately completes the request.nn### Instruction:nWhat is an egg laying mammal?nn###
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M Bazel GitHub Metrics A dataset with GitHub download counts of release artifacts from selected bazelbuild repositories. UGIF A multi-lingual, multi-modal UI grounded dataset for step-by-step task completion on the smartphone.
There will be a lot of tasks to complete. This is the link [8] to the article about this Zero-Shot Classification NLP. BART stands for Bidirectional and Auto-Regression, and is used in processing human languages that is related to sentences and text. Are you ready to explore? Let’s begin! The approach was proposed by Yin et al.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). are getting famous with use cases like image classification, object detection, chat-bots, text generation, and more. Data formats like image, video, text, etc.,
You would address it in a completely different way, depending on what’s the problem. What’s your approach to different modalities of classification detection and segmentation? If you have images and then the task is to do the classification, then there’s quite not too much information in a given image.
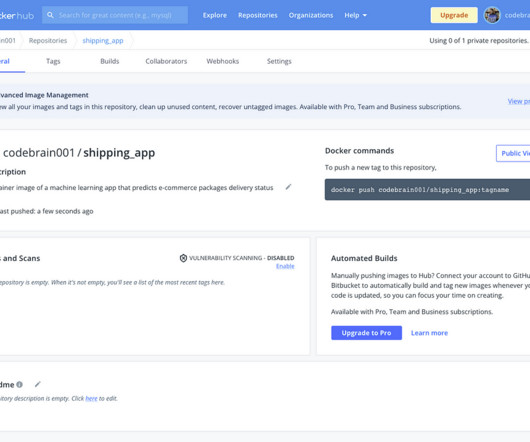
Use Case To drive the understanding of the containerization of machine learning applications, we will build an end-to-end machine learning classification application. image { width: 95%; border-radius: 1%; height: auto; }.form-header Docker APIs interact with the Docker daemon through the CLI commands or scripting.
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
The models can be completely heterogenous, with their own independent serving stack. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. instance_type="ml.trn1n.32xlarge",
AmazonBedrockFullAccess AmazonS3FullAccess AmazonEC2ContainerRegistryFullAccess Open SageMaker Studio To open SageMaker studio, complete the following steps: On the SageMaker console, choose Studio in the navigation pane. Auto scaling helps make sure the endpoint can handle varying workloads efficiently. Choose Create domain.
In HPO mode, SageMaker Canvas supports the following types of machine learning algorithms: Linear learner: A supervised learning algorithm that can solve either classification or regression problems. Auto: Autopilot automatically chooses either ensemble mode or HPO mode based on your dataset size. Otherwise, it chooses ensemble mode.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content