This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Don’t Forget to join our 40k+ ML SubReddit The post The “Zero-Shot” Mirage: How DataScarcity Limits Multimodal AI appeared first on MarkTechPost. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
The rapid growth of artificialintelligence (AI) has created an immense demand for data. This approach has driven significant advancements in areas like natural language processing, computervision, and predictive analytics.
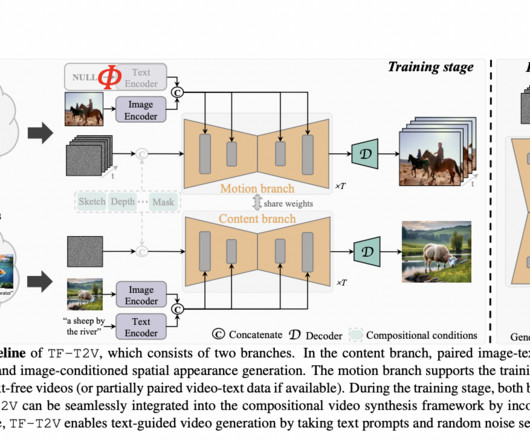
A fascinating field of study in artificialintelligence and computervision is the creation of videos based on written descriptions. This innovative technology combines creativity and computation and has numerous potential applications, including film production, virtual reality, and automated content generation.
One of the computervision applications we are most excited about is the field of robotics. By marrying the disciplines of computervision, natural language processing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology.
One of the computervision applications we are most excited about is the field of robotics. By marrying the disciplines of computervision, natural language processing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology.
Computervision (CV) is a rapidly evolving area in artificialintelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
Over the past decade, advancements in deep learning and artificialintelligence have driven significant strides in self-driving vehicle technology. These technologies have revolutionized computervision, robotics, and natural language processing and played a pivotal role in the autonomous driving revolution.
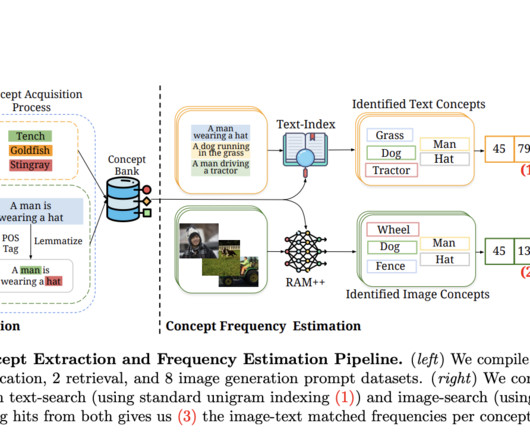
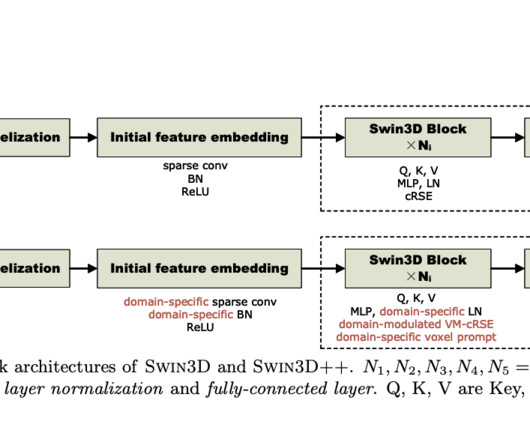
However, the scarcity and limited annotation of 3D data present significant challenges for the development and impact of 3D pretraining. One straightforward solution to address the datascarcity issue is to merge multiple existing 3D datasets and employ the combined data for universal 3D backbone pretraining.
The health, fashion, and fitness industries are highly interested in the difficult computervision problem of 3D reconstructing human body parts from pictures. They also make available a sizable collection of artificially photorealistic photos matched with ground truth labels for these kinds of signals to overcome datascarcity.
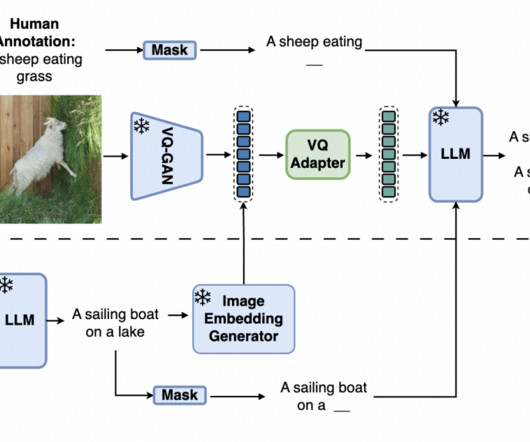
Recent advancements in high-quality image generators have sparked interest in using generative models for synthetic data generation. This trend impacts various computervision tasks, including semantic segmentation, human motion understanding, and image classification. The researchers from Google DeepMind have proposed Synth2.
A current PubMed search using the Mesh keywords “artificialintelligence” and “radiology” yielded 5,369 papers in 2021, more than five times the results found in 2011. Datascarcity and data imbalance are two of these challenges.
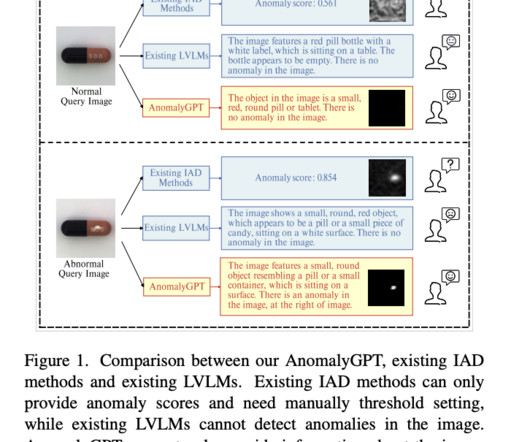
They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first. With just a few normal samples, AnomalyGPT can also learn in context, allowing for quick adjustment to new objects.
Access to synthetic data is valuable for developing effective artificialintelligence (AI) and machine learning (ML) models. Real-world data often poses significant challenges, including privacy, availability, and bias. To address these challenges, we introduce synthetic data as an ML model training solution.
By leveraging auxiliary information such as semantic attributes, ZSL enhances scalability, reduces data dependency, and improves generalisation. This innovative approach is transforming applications in computervision, Natural Language Processing, healthcare, and more.
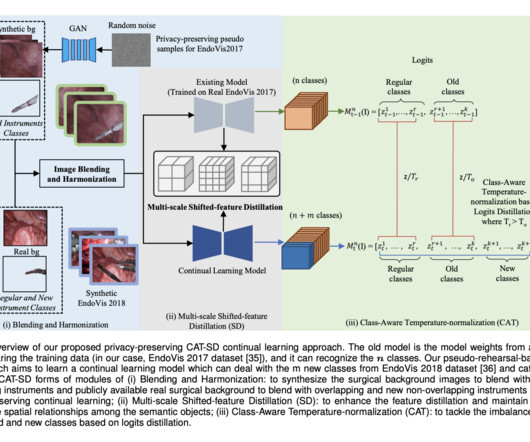
The developed CAT-SD scheme effectively mitigates catastrophic forgetting, addresses datascarcity, and ensures privacy in medical datasets. In conclusion, this study introduces a novel privacy-preserving synthetic continual semantic segmentation approach for robotic instrument segmentation.
Conclusion Tarsier2 marks a significant step forward in video understanding by addressing key challenges such as temporal alignment, hallucination reduction, and datascarcity.
A key finding is that for a fixed compute budget, training with up to four epochs of repeated data shows negligible differences in loss compared to training with unique data. However, beyond four epochs, the additional computational investment yields diminishing returns.
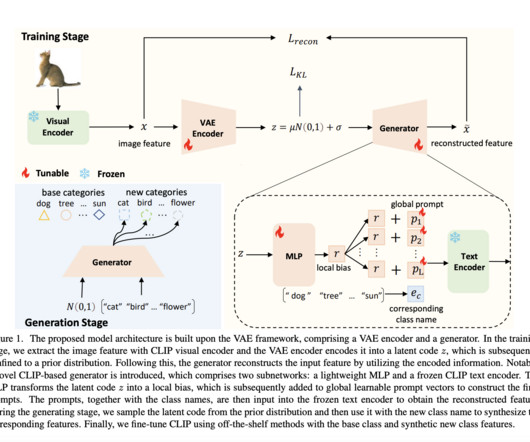
Overall, the paper presents a significant contribution to the field by addressing the challenge of datascarcity for certain classes and enhancing the performance of CLIP fine-tuning methods using synthesized data. Check out the Paper. All Credit For This Research Goes To the Researchers on This Project.
SegGPT Many successful approaches from NLP are now being translated into computervision. For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computervision. Finally, the resulting segmentation, along with additional classification information.
The SRDF approach addresses the long-standing challenge of datascarcity in VLN by automating dataset refinement. The researchers also reported enhanced instruction diversity and richness, with over 10,000 unique words incorporated into the SRDF-generated dataset, addressing the vocabulary limitations of previous datasets.
The SFM method marks a meaningful advancement in atmospheric science, setting a new benchmark in model accuracy for high-resolution weather data, especially when conventional models face limitations due to datascarcity and resolution misalignment. Check out the Paper.
However, the method requires a sufficient volume of labeled training data. This prevents you from applying artificialintelligence (AI) in several real-world industrial use cases, such as healthcare, retail, and manufacturing, where data is scarce. Viso Suite is the end-to-end, No-Code ComputerVision Solution.
Thus it reduces the amount of data and computational need. Transfer Learning has various applications like computervision, NLP, recommendation systems, and robotics. This technology allows models to be fine-tuned using a limited amount of data. All this will eventually help in boosting up your career growth.
Dealing with limited target data – In some cases, there is limited real-world data available for the target task. Model customization uses the pre-trained weights learned on larger datasets to overcome this datascarcity. He focuses on AI/ML technologies with a keen interest in Generative AI and ComputerVision.
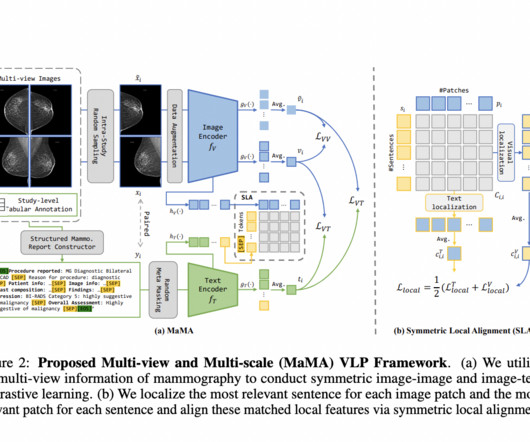
This allows the framework to overcome datascarcity and perform better on mammography tasks. It also uses a symmetric local alignment module to focus on detailed features and a parameter-efficient fine-tuning approach to enhance pre-trained LLMs with medical knowledge.
SegGPT Many successful approaches from NLP are now being translated into computervision. For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computervision. Finally, the resulting segmentation, along with additional classification information.
AI music is revolutionizing the music industry through a wide range of artificialintelligence (AI) applications. These intelligent models have transcended their traditional linguistic boundaries to influence music generation. Music-generative AI changes how we understand, create, and interact with music.
Overcoming datascarcity with translation and synthetic data generation When fine-tuning a custom version of the Mistral 7B LLM for the Italian language, Fastweb faced a major obstacle: high-quality Italian datasets were extremely limited or unavailable. In his free time, Giuseppe enjoys playing football.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content