This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post How to Detect COVID-19 Cough From Mel Spectrogram Using ConvolutionalNeuralNetwork appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon COVID-19 COVID-19 (coronavirus disease 2019) is a disease that causes respiratory.
Computervision is rapidly transforming industries by enabling machines to interpret and make decisions based on visual data. Learning computervision is essential as it equips you with the skills to develop innovative solutions in areas like automation, robotics, and AI-driven analytics, driving the future of technology.
In the current ArtificialIntelligence and Machine Learning industry, “ Image Recognition ”, and “ ComputerVision ” are two of the hottest trends. Despite some similarities, both computervision and image recognition represent different technologies, concepts, and applications. What is ComputerVision?
Introduction Video recognition is a cornerstone of modern computervision, enabling machines to understand and interpret visual content in videos. With the rapid evolution of convolutionalneuralnetworks (CNNs) and transformers, significant strides have been made in enhancing the accuracy and efficiency of video recognition systems.
In the past decade, ArtificialIntelligence (AI) and Machine Learning (ML) have seen tremendous progress. Additionally, they can generate text and speech that parallels human intelligence. The SEER model by Facebook AI aims at maximizing the capabilities of self-supervised learning in the field of computervision.
Introduction Computervision is a field of A.I. Since 2012 after convolutionalneuralnetworks(CNN) were introduced, we moved away from handcrafted features to an end-to-end approach using deep neuralnetworks. This article was published as a part of the Data Science Blogathon.
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of ConvolutionalNeuralNetworks (CNNs) to capture global contextual information. A team of researchers at UCAS, in collaboration with Huawei Inc.
ConvolutionalNeuralNetworks (CNNs) have become the benchmark for computervision tasks. Capsule Networks (CapsNets), first introduced by Hinton et al. Despite computational complexity and optimization challenges, ongoing research continues to enhance CapsNets’ performance and efficiency.
Fortunately, ArtificialIntelligence can help meet this challenge. These algorithms are called ConvolutionalNeuralNetworks (CNN), and they contain a database of the gyroscopic movements associated with a variety of daily living activities.
Vision Transformers (ViT) and ConvolutionalNeuralNetworks (CNN) have emerged as key players in image processing in the competitive landscape of machine learning technologies. Their development marks a significant epoch in the ongoing evolution of artificialintelligence.
Deep learning models like ConvolutionalNeuralNetworks (CNNs) and Vision Transformers achieved great success in many visual tasks, such as image classification, object detection, and semantic segmentation. If you like our work, you will love our newsletter.
Deep convolutionalneuralnetworks (DCNNs) have been a game-changer for several computervision tasks. Network depth and convolution are the two primary components of a DCNN that determine its expressive power.
There has been a dramatic increase in the complexity of the computervision model landscape. Many models are now at your fingertips, from the first ConvNets to the latest Vision Transformers. Our work comprehensively compares common vision models on "non-standard" metrics. (1/n)
To address this, various feature extraction methods have emerged: point-based networks and sparse convolutionalneuralnetworks CNNs ConvolutionalNeuralNetworks. Understanding the underlying reasons for this performance gap is crucial for advancing the capabilities of sparse CNNs.
This model incorporates a static ConvolutionalNeuralNetwork (CNN) branch and utilizes a variational attention fusion module to enhance segmentation performance. Hausdorff Distance Using ConvolutionalNeuralNetwork CNN and ViT Integration appeared first on MarkTechPost. Dice Score and 27.10
Healthcare in the United States is in the early stages of a significant potential disruption due to the use of Machine Learning and ArtificialIntelligence. Some of the earliest and most extensive work has occurred in the use of deep learning and computervision models. Several types of networks exist.
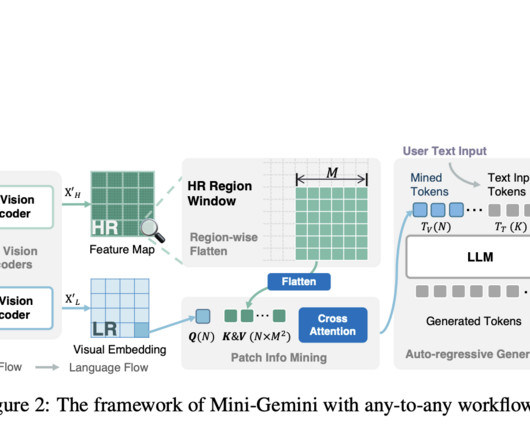
Vision Language Models (VLMs) emerge as a result of a unique integration of ComputerVision (CV) and Natural Language Processing (NLP). These innovations enable Mini-Gemini to process high-resolution images effectively and generate context-rich visual and textual content, setting it apart from existing models.
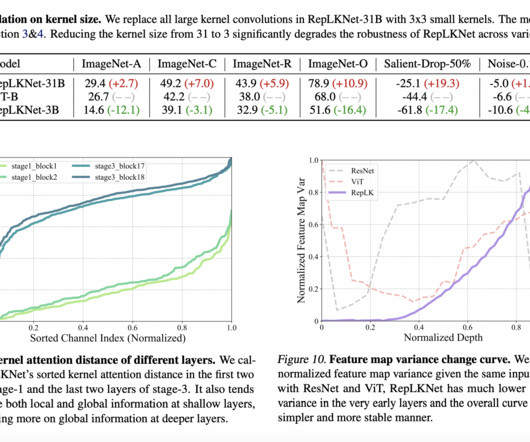
Don’t Forget to join our 46k+ ML SubReddit The post Exploring Robustness: Large Kernel ConvNets in Comparison to ConvolutionalNeuralNetwork CNNs and Vision Transformers ViTs appeared first on MarkTechPost. If you like our work, you will love our newsletter.
This article covers an extensive list of novel, valuable computervision applications across all industries. Find the best computervision projects, computervision ideas, and high-value use cases in the market right now. provides Viso Suite , the world’s only end-to-end ComputerVision Platform.
To combine computer-generated visuals or deduce the physical characteristics of a scene from pictures, computer graphics, and 3D computervision groups have been working to create physically realistic models for decades. If you like our work, you will love our newsletter. We are also on WhatsApp.
In The News ChatGPT developer OpenAI to locate first non-US office in London OpenAI, the developer of ChatGPT, has chosen London as the location for its first international office in a boost to the UK’s attempts to stay competitive in the artificialintelligence race. June 15, 2023 /PRNewswire/ -- Quantum Computing Inc. ("QCi"
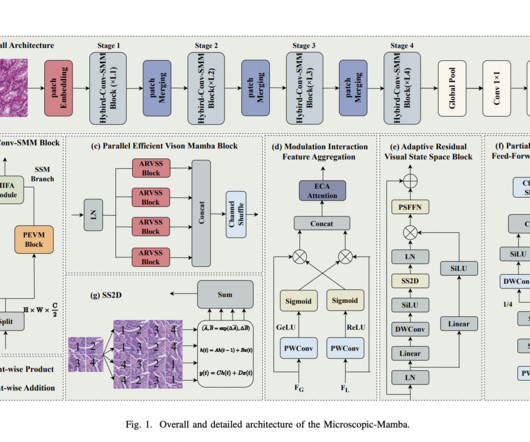
Traditional machine learning methods, such as convolutionalneuralnetworks (CNNs), have been employed for this task, but they come with limitations. Moreover, the scale of the data generated through microscopic imaging makes manual analysis impractical in many scenarios.
Stereo depth estimation plays a crucial role in computervision by allowing machines to infer depth from two images. These methods utilize 3D convolutionalneuralnetworks (CNNs) for cost filtering but struggle with generalization beyond their training data.
cryptopolitan.com Applied use cases Alluxio rolls out new filesystem built for deep learning Alluxio Enterprise AI is aimed at data-intensive deep learning applications such as generative AI, computervision, natural language processing, large language models and high-performance data analytics. voxeurop.eu
Summary: ConvolutionalNeuralNetworks (CNNs) are essential deep learning algorithms for analysing visual data. Introduction Neuralnetworks have revolutionised ArtificialIntelligence by mimicking the human brai n’s structure to process complex data. What are ConvolutionalNeuralNetworks?
Computervision is rapidly transforming industries by enabling machines to interpret and make decisions based on visual data. Learning computervision is essential as it equips you with the skills to develop innovative solutions in areas like automation, robotics, and AI-driven analytics, driving the future of technology.
The goal of computervision research is to teach computers to recognize objects and scenes in their surroundings. In this article, I would like to take a look at the current challenges in the field of robotics and discuss the relevance and applications of computervision in this area.
Contrastingly, agentic systems incorporate machine learning (ML) and artificialintelligence (AI) methodologies that allow them to adapt, learn from experience, and navigate uncertain environments. Image Embeddings: Convolutionalneuralnetworks (CNNs) or vision transformers can transform images into dense vector embedding.
Artificialintelligence (AI) has made considerable advances over the past few years, becoming more proficient at activities previously only performed by humans. The phenomenon known as artificialintelligence hallucination happens when an AI model produces results that are not what was anticipated.
The success of this model reflects a broader shift in computervision towards machine learning approaches that leverage large datasets and computational power. Previously, researchers doubted that neuralnetworks could solve complex visual tasks without hand-designed systems. by the next-best model.
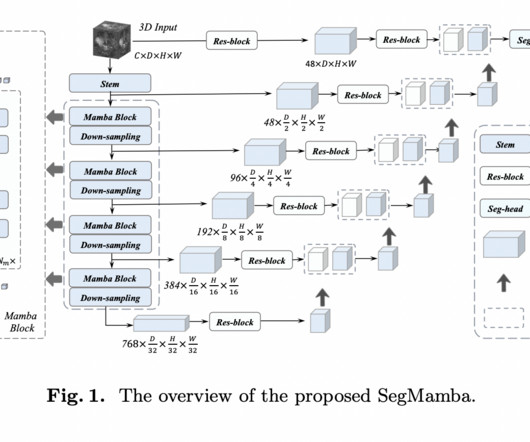
Traditional convolutionalneuralnetworks (CNNs) often struggle to capture global information from high-resolution 3D medical images. One proposed solution is the utilization of depth-wise convolution with larger kernel sizes to capture a wider range of features.
With the rapid advancements in ArtificialIntelligence, it’s essential to gain practical experience alongside theoretical knowledge. Deep Learning is a specialized subset of ArtificialIntelligence (AI) and machine learning that employs multilayered artificialneuralnetworks to analyze and interpret complex data.
To overcome the challenge presented by single modality models & algorithms, Meta AI released the data2vec, an algorithm that uses the same learning methodology for either computervision , NLP or speech. For computervision, the model practices block-wise marking strategy.
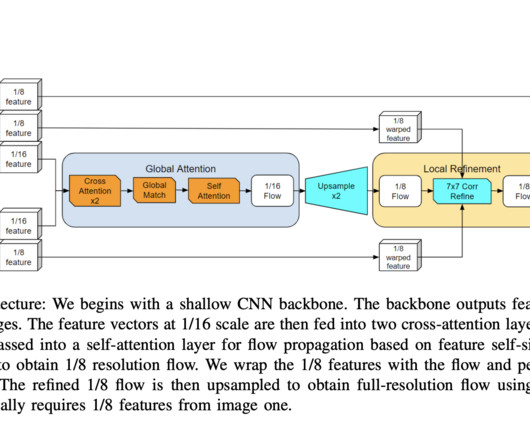
Real-time, high-accuracy optical flow estimation is critical for analyzing dynamic scenes in computervision. Traditional methodologies, while foundational, have often stumbled upon the computational versus accuracy problem, especially when executed on edge devices. Check out the Paper and Github.
Project Structure Accelerating ConvolutionalNeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating ConvolutionalNeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
Computervision is a field of artificialintelligence that aims to enable machines to understand and interpret visual information, such as images or videos. Computervision has many applications in various domains, such as medical imaging, security, autonomous driving, and entertainment.
Machine learning and deep neuralnetwork models can effectively analyze this data to identify patterns, correlations and relationships, which is particularly useful for understanding a patient’s unique profile.
If you want a gentle introduction to machine learning for computervision, you’re in the right spot. Here at PyImageSearch we’ve been helping people just like you master deep learning for computervision. Also, you might want to check out our computervision for deep learning program before you go.
Limitations of ANNs: Move to ConvolutionalNeuralNetworks This member-only story is on us. The journey from traditional neuralnetworks to convolutional architectures wasnt just a technical evolution it was a fundamental reimagining of how machines should perceive visual information.
This article covers everything you need to know about image classification – the computervision task of identifying what an image represents. Today, the use of convolutionalneuralnetworks (CNN) is the state-of-the-art method for image classification. It’s a powerful all-in-one solution for AI vision.
Computervision enables machines to interpret & understand visual information from the world. Innovations in this area have been propelled by developing advanced neuralnetwork architectures, particularly ConvolutionalNeuralNetworks (CNNs) and, more recently, Transformers.
Photo by Tobias Reich on Unsplash In the ever-evolving world of artificialintelligence, ConvolutionalNeuralNetworks (CNNs) have emerged as a revolutionary technology, reshaping the fields of computervision and image recognition. Filters, also known as kernels. red, green, blue).
A Hybrid CNN-Transformer Architecture for Medical Image Segmentation with DDConv and SW-ACAM, compatible with quantitative and qualitative analysis Limi Change on Unsplash The convolutionalneuralnetworks are limited to capturing global features, whereas, transformers are limited to extracting local features.
AI emotion recognition is a very active current field of computervision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. provides the end-to-end computervision platform Viso Suite. About us: Viso.ai
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content