This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. This post focuses on the Cost Optimization pillar of the IDP solution.
With this new feature, you can use your own identity provider (IdP) such as Okta , Azure AD , or Ping Federate to connect to Snowflake via Data Wrangler. Solution overview In the following sections, we provide steps for an administrator to set up the IdP, Snowflake, and Studio. Provide the users within the IdP access to Data Wrangler.
This represents a major opportunity for businesses to optimize this workflow, save time and money, and improve accuracy by modernizing antiquated manual document handling with intelligent document processing (IDP) on AWS. These samples demonstrate using various LLMs. pip install unstructured !pip
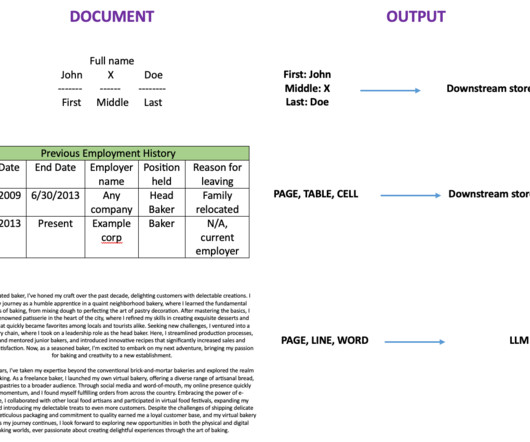
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Categorizing documents is an important first step in IDP systems. For optimal performance, you should customize the solution to your specific use case and existing IDP pipeline setup.
Document processing has witnessed significant advancements with the advent of Intelligent Document Processing (IDP). With IDP, businesses can transform unstructured data from various document types into structured, actionable insights, dramatically enhancing efficiency and reducing manual efforts.
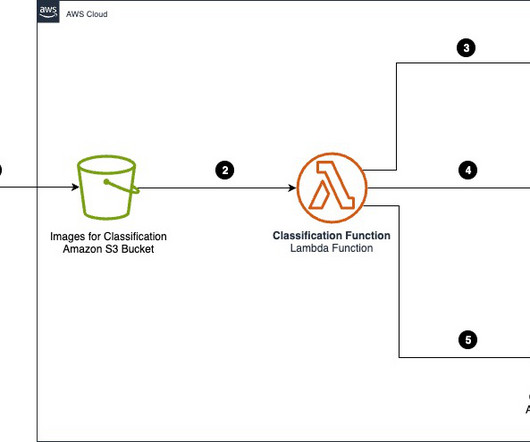
With Intelligent Document Processing (IDP) leveraging artificialintelligence (AI), the task of extracting data from large amounts of documents with differing types and structures becomes efficient and accurate. The following diagram is how we visualize these IDP phases.
AWS intelligent document processing (IDP), with AI services such as Amazon Textract , allows you to take advantage of industry-leading machine learning (ML) technology to quickly and accurately process data from any scanned document or image. In this post, we share how to enhance your IDP solution on AWS with generative AI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content