This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Introduction In the past few years, Naturallanguageprocessing has evolved a lot using deep neural networks. BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers.
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. BERT T5 (Text-to-Text Transfer Transformer) : Introduced by Google in 2020 , T5 reframes all NLP tasks as a text-to-text problem, using a unified text-based format.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is NaturalLanguageProcessing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
NaturalLanguageProcessing (NLP) is integral to artificialintelligence, enabling seamless communication between humans and computers. Researchers from East China University of Science and Technology and Peking University have surveyed the integrated retrieval-augmented approaches to language models.
The following six free AI courses offer a structured pathway for beginners to start their journey into the world of artificialintelligence. Transformer Models and BERT Model : In this course, participants delve into the specifics of Transformer models and the Bidirectional Encoder Representations from Transformers (BERT) model.
Machines are demonstrating remarkable capabilities as ArtificialIntelligence (AI) advances, particularly with Large Language Models (LLMs). They process and generate text that mimics human communication. At the leading edge of NaturalLanguageProcessing (NLP) , models like GPT-4 are trained on vast datasets.
techcrunch.com The Essential ArtificialIntelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for naturallanguageprocessing tasks like answering questions, analyzing sentiment, and translation.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
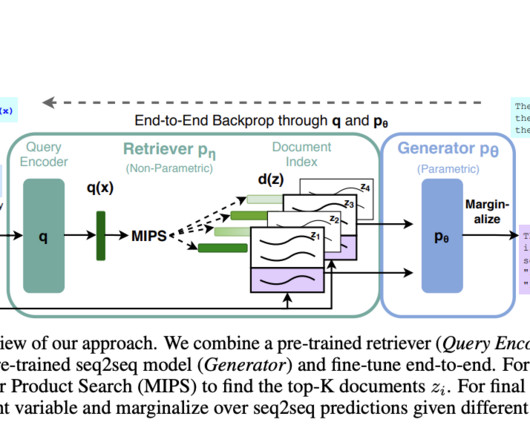
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. Existing research includes frameworks like REALM and ORQA, which integrate pre-trained neural language models with differentiable retrievers for enhanced knowledge access.
In a significant leap forward for artificialintelligence (AI), a team from the University of Geneva (UNIGE) has successfully developed a model that emulates a uniquely human trait: performing tasks based on verbal or written instructions and subsequently communicating them to others.
Photo by Amr Taha™ on Unsplash In the realm of artificialintelligence, the emergence of transformer models has revolutionized naturallanguageprocessing (NLP). In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection.
In recent years, there has been a great inclination toward Large Language Models (LLMs) due to their amazing text generation, analysis, and classification capabilities. These models use billions of parameters to execute a variety of NaturalLanguageProcessing (NLP) tasks.
Introduction Embark on a journey through the evolution of artificialintelligence and the astounding strides made in NaturalLanguageProcessing (NLP). The seismic impact of finetuning large language models has utterly transformed NLP, revolutionizing our technological interactions.
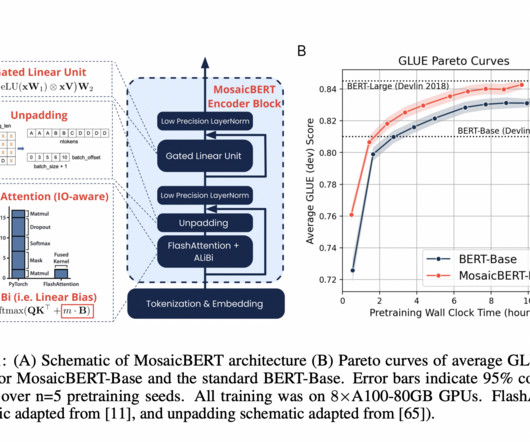
BERT is a language model which was released by Google in 2018. However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT. BERT-Base reached an average GLUE score of 83.2% hours compared to 23.35
The ArtificialIntelligence (AI) ecosystem has evolved rapidly in the last five years, with Generative AI (GAI) leading this evolution. What is Generative ArtificialIntelligence, how it works, what its applications are, and how it differs from standard machine learning (ML) techniques. billion in 2023.
Researchers have focused on developing and building models to process and compare human language in naturallanguageprocessing efficiently. This technology is crucial for semantic search, clustering, and naturallanguage inference tasks.
Language model pretraining has significantly advanced the field of NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. For example, GTEs contrastive learning boosts retrieval performance but cannot compensate for BERTs obsolete embeddings.
The prowess of Large Language Models (LLMs) such as GPT and BERT has been a game-changer, propelling advancements in machine understanding and generation of human-like text. These models have mastered the intricacies of language, enabling them to tackle tasks with remarkable accuracy. Check out the Paper and Project.
This is why Machine Learning Operations (MLOps) has emerged as a paradigm to offer scalable and measurable values to ArtificialIntelligence (AI) driven businesses. LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code.
Examples of text-only LLMs include GPT-3 , BERT , RoBERTa , etc. Why is there a need for Multimodal Language Models The text-only LLMs like GPT-3 and BERT have a wide range of applications, such as writing articles, composing emails, and coding.
In recent years, NaturalLanguageProcessing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Beyond traditional search engines, these models represent a new era of intelligent Web browsing agents that go beyond simple keyword searches.
With the widespread attention, and potential applications of blockchain and artificialintelligence technologies, the privacy protection techniques that arise as a direct result of integration of the two technologies is gaining notable significance.
In the ever-evolving domain of ArtificialIntelligence (AI), where models like GPT-3 have been dominant for a long time, a silent but groundbreaking shift is taking place. Small Language Models (SLM) are emerging and challenging the prevailing narrative of their larger counterparts.
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. They have seen an increase of 56% transaction classification accuracy after moving to the new BERT based model.
NaturalLanguageProcessing (NLP) tasks extensively make use of text embeddings. Text embeddings encode semantic information contained in text by acting as vector representations of naturallanguage. These techniques, however, are unable to capture the rich contextual information included in real language fully.
Summary: Deep Learning vs Neural Network is a common comparison in the field of artificialintelligence, as the two terms are often used interchangeably. Use Cases: NaturalLanguageProcessing (NLP) (language modeling, machine translation, sentiment analysis), speech recognition, time series prediction, video analysis.
ArtificialIntelligence (AI) has seen tremendous growth, transforming industries from healthcare to finance. Across sectors like healthcare, finance, autonomous vehicles , and naturallanguageprocessing , the demand for efficient AI models is increasing. It uses high precision (e.g.,
ELIZA was built by Joseph Weizenbaum at the MIT ArtificialIntelligence Laboratory and was designed to imitate Rogerian psychotherapists. Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering.
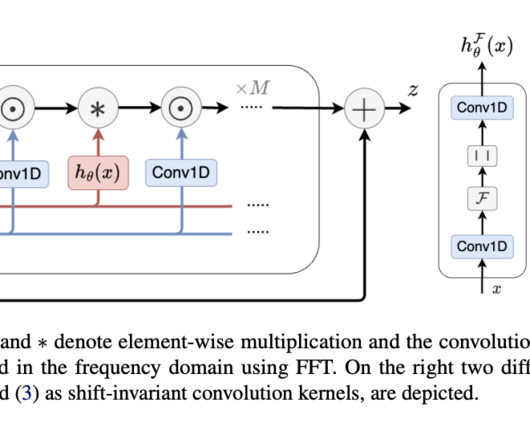
However, the computational complexity associated with these mechanisms scales quadratically with sequence length, which becomes a significant bottleneck when managing long-context tasks such as genomics and naturallanguageprocessing. Compared to the BERT-base, the Orchid-BERT-base has 30% fewer parameters yet achieves a 1.0-point
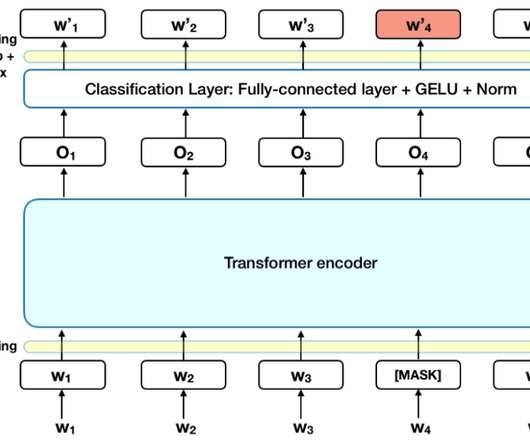
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). This is generally a positive thing, but it sometimes over-generalizes , leading to examples such as this: Figure 4: BERT guesses that the masked token should be a color, but fails to predict the correct color.
Creating music using artificialintelligence began several decades ago. However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech.
Naturallanguageprocessing (NLP) focuses on enabling computers to understand and generate human language, making interactions more intuitive and efficient. T5 standardizes NLP tasks as text-to-text, while RoBERTa enhances BERT’s training process for superior performance.
Large Language Models (LLMs), like GPT, PaLM, LLaMA, etc., Their ability to utilize the strength of NaturalLanguageProcessing, Generation, and Understanding by generating content, answering questions, summarizing text, and so on have made LLMs the talk of the town in the last few months.
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process.
Self Supervised Learning models build representations of the training data using human annotated labels, and it’s one of the major reasons behind the advancement of the NLP or NaturalLanguageProcessing , and the Computer Vision technology.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
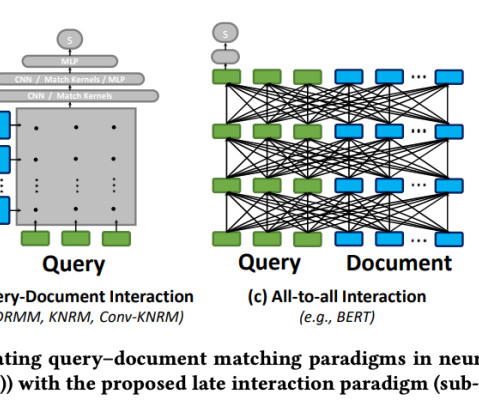
When it comes to naturallanguageprocessing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. ColBERT: Efficient and Effective Late Interaction One of the standout models in the realm of reranking is ColBERT ( Contextualized Late Interaction over BERT ).
Generative AI ( artificialintelligence ) promises a similar leap in productivity and the emergence of new modes of working and creating. They are now capable of naturallanguageprocessing ( NLP ), grasping context and exhibiting elements of creativity.
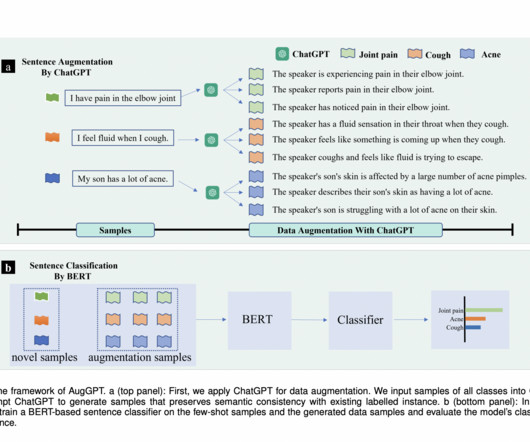
NLP, or NaturalLanguageProcessing, is a field of AI focusing on human-computer interaction using language. NLP aims to make computers understand, interpret, and generate human language. This process enhances data diversity. Prepare a novel dataset (Dn) with only a few labeled samples.
The term “foundation model” was coined by the Stanford Institute for Human-Centered ArtificialIntelligence in 2021. A foundation model is built on a neural network model architecture to process information much like the human brain does. An open-source model, Google created BERT in 2018.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large language models” on YouTube Channel “Google Cloud Tech” What are Large Language Models? NaturalLanguageProcessing (NLP) is a subfield of artificialintelligence.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content