

Conservative Algorithms for Zero-Shot Reinforcement Learning on Limited Data
Marktechpost
SEPTEMBER 29, 2024
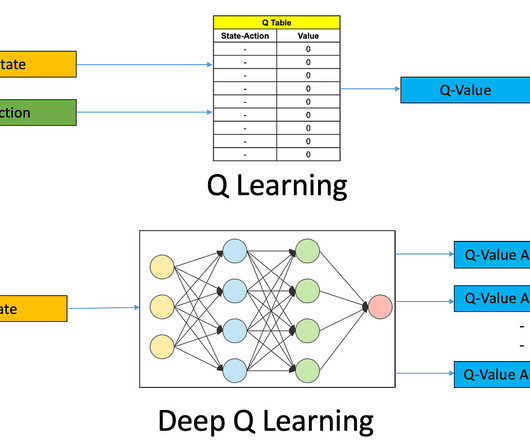
Consequently, most RL algorithms perform poorly when trained on small or homogeneous datasets, as they suffer from overestimating the values of out-of-distribution (OOD) state-action pairs, leading to ineffective policy generation. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!




































Let's personalize your content