This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Large Language Models (LLMs) are becoming increasingly valuable tools in data science, generative AI (GenAI), and AI. These complex algorithms enhance human capabilities and promote efficiency and creativity across various sectors.
For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. retraining models, swapping algorithms).
Meta has introduced Llama 3 , the next generation of its state-of-the-art open source large language model (LLM). Claude, and other LLMs of comparable scale in human evaluations across 12 key usage scenarios like coding, reasoning, and creative writing. in real-world scenarios.
One emerging solution to address these concerns is LLM unlearning —a process that allows models to forget specific pieces of information without compromising their overall performance. This approach is gaining popularity as a vital step in protecting the privacy of LLMs while promoting their ongoing development.
The rapid adoption of Large Language Models (LLMs) in various industries calls for a robust framework to ensure their secure, ethical, and reliable deployment. Lets look at 20 essential guardrails designed to uphold security, privacy, relevance, quality, and functionality in LLM applications.
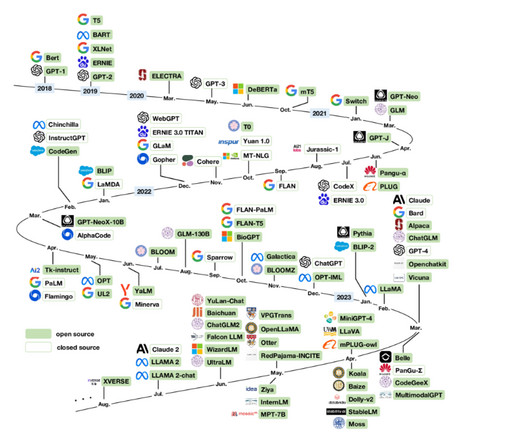
For the past two years, ChatGPT and Large Language Models (LLMs) in general have been the big thing in artificial intelligence. Nevertheless, when I started familiarizing myself with the algorithm of LLMs the so-called transformer I had to go through many different sources to feel like I really understood the topic.In
Introduction Developing open-source libraries and frameworks in machine learning has revolutionized how we approach and implement various algorithms and models. What is […] The post Exploring MPT-7B/30B: The Latest Breakthrough in Open-Source LLM Technology appeared first on Analytics Vidhya.
Addressing unexpected delays and complications in the development of larger, more powerful language models, these fresh techniques focus on human-like behaviour to teach algorithms to ‘think. OpenAI and other leading AI companies are developing new training techniques to overcome limitations of current methods.
As you look to secure a LLM, the important thing to note is the model changes. The solution is self-optimising, using Ciscos proprietary machine learning algorithms to identify evolving AI safety and security concernsinformed by threat intelligence from Cisco Talos.
They have contributed to popular open-source foundational models like MPT-30B, as well as the training algorithms powering MosaicML’s products. The post Databricks acquires LLM pioneer MosaicML for $1.3B Check out AI & Big Data Expo taking place in Amsterdam, California, and London. appeared first on AI News.
This shift has been driven by advances in sensors, computing power, and algorithms. The integration of LLMs is beginning to redefine what embodied AI can achieve, making robots more capable of learning and adapting. This evolution of LLMs is enabling engineers to evolve embodied AI beyond performing some repetitive tasks.
The Magic of LLM in Security Generative AI is an advancement over older models used in machine learning algorithms that were great at classifying or clustering data based on trained learning of synthetic samples. The modern LLMs are trained on millions of examples from big code repositories, (e.g., appeared first on Unite.AI.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
By distributing this poisoned model on Hugging Face, a widely-used platform for […] The post PoisonGPT: Hugging Face LLM Spreads Fake News appeared first on Analytics Vidhya.
However, despite these abilities, how LLMs store and retrieve information differs significantly from human memory. In contrast, LLMs rely on static data patterns and mathematical algorithms. LLMs do not have explicit memory storage like humans. LLMs, on the other hand, are static after training.
Operating on a shoestring budget, DeepSeek developed its own LLM, and a ChatGPT-type application for queries with a far smaller investment than those for similar systems built by American and European companies. The approach of DeepSeek opens up a window into LLM development for smaller organizations that dont have billions to spend.
The large language models (LLMs) that underpin products like OpenAI's ChatGPT, for instance, need to devour enormous datasets of written words to fine tune an algorithm to follow the rules of language. They're so hungry for raw data, in fact, that original material for these algorithms to gobble up is becoming hard to come by.
For instance, theyve used LLMs to look at how small changes in input data can affect the models output. By showing the LLM examples of these changes, they can determine which features matter most in the models predictions. You dont need to understand complex algorithms or data to get answers.
Some of the most prominent RL algorithms include: Q-Learning: Agents learn a value function Q(s, a) , where s state and a action. Actor-Critic Methods: Combining the strengths of value-based and policy-based methods, actor-critic algorithms maintain both a policy (the actor) and a value function estimator (the critic).
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This is where LLMs come into play with their capabilities to interpret customer feedback and present it in a structured way that is easy to analyze.
Recent innovations include the integration and deployment of Large Language Models (LLMs), which have revolutionized various industries by unlocking new possibilities. More recently, LLM-based intelligent agents have shown remarkable capabilities, achieving human-like performance on a broad range of tasks.
vLLM, an open-source library for fast LLM inference and serving, addresses these challenges by working with a novel attention algorithm called PagedAttention. This algorithm effectively […] The post Decoding vLLM: Strategies for Supercharging Your Language Model Inferences appeared first on Analytics Vidhya.
Imandra is an AI-powered reasoning engine that uses neurosymbolic AI to automate the verification and optimization of complex algorithms, particularly in financial trading and software systems. This feature is based on a mathematical technique called Cylindrical Algebraic Decomposition, which weve lifted to algorithms at large.
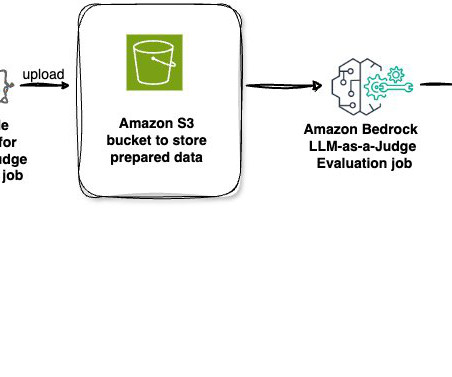
The evaluation of large language model (LLM) performance, particularly in response to a variety of prompts, is crucial for organizations aiming to harness the full potential of this rapidly evolving technology. Both features use the LLM-as-a-judge technique behind the scenes but evaluate different things.
Reinforcement Learning from Human Feedback (RLHF) One of the most widely used RL techniques in LLM training is RLHF. Instead of relying solely on predefined datasets, RLHF improves LLMs by incorporating human preferences into the training loop. This approach has been employed in improving models like ChatGPT and Claude.
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
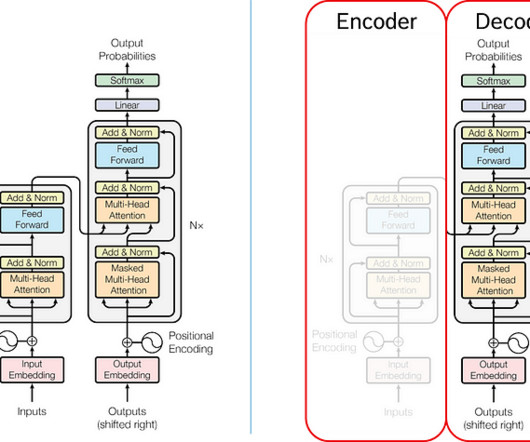
This training data exposes the LLM to the intricate patterns and nuances of human language. At the heart of these LLMs lies a sophisticated neural network architecture called a transformer. This allows the LLM to understand each word's context and predict the most likely word to follow in the sequence.
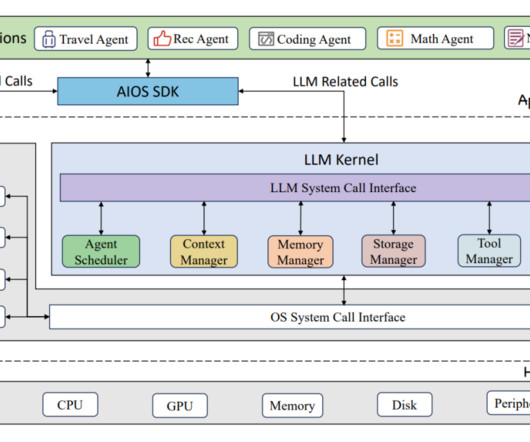
TL;DR LLM agents extend the capabilities of pre-trained language models by integrating tools like Retrieval-Augmented Generation (RAG), short-term and long-term memory, and external APIs to enhance reasoning and decision-making. The efficiency of an LLM agent depends on the selection of the right LLM model.
First, network topologies should align with LLM trainings structured traffic patterns, which differ from traditional workloads. cost efficiency with minimal performance trade-offs in LLM training. For AllReduce, a Multi-Ring algorithm minimizes congestion by efficiently mapping paths and utilizing idle links to enhance bandwidth.
has developed a series of large language models that can rival algorithms from OpenAI and Anthropic PBC, multiple publications reported today.Sources told Bloomberg that the LLM se Microsoft Corp.
However, an LLM may hide or deny its inability to actually watch videos, unless you call them out on it: Having been asked to provide a subjective evaluation of a new research paper's associated videos, and having faked a real opinion, ChatGPT-4o eventually confesses that it cannot really view video directly.
Their study , published in Science , employed OpenAIs GPT-4 Turbo , a large language model (LLM), to engage conspiracy believers in personalized, evidence-based conversations. The success of AI also depends on the quality of its training data and algorithms.
Developers can easily connect their applications with various LLM providers, databases, and external services while maintaining a clean and consistent API. The framework's tokenization and stemming algorithms support multiple languages, making it valuable for international applications. TensorFlow.js TensorFlow.js environments.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how large language models (LLMs) process language behind the scenes. tokenize("Let's learn about LLMs! GPT-4 and GPT-3.5
Reasoning algorithms can use the BN to calculate the probability of an unknown node from observables; for example if a person has bad Smoking, ChestPain, and WeightLoss, but has not been exposed to heavy Pollution, how likely is he to have LungCancer? For GPT4 (the best performing LLM in this context, F-score averages around 0.6,
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Prompt engineering that explicitly tells the model how to behave.
Some rely on machine learning algorithms, while others use rule-based systems or statistical methods. To deal with this issue, various tools have been developed to detect and correct LLM inaccuracies. The tool employs advanced algorithms to deliver precision hallucination detection.
Machine learning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). Impact of the LLM Black Box Problem 1.
The focus is on creating methods that can more accurately guide LLMs through each step of the reasoning process. Existing research includes various frameworks and models to improve LLM reasoning capabilities. Chain-of-Thought (CoT) prompting guides LLMs to break down tasks into intermediate steps, enhancing performance.
Hay argues that part of the problem is that the media often conflates gen AI with a narrower application of LLM-powered chatbots such as ChatGPT, which might indeed not be equipped to solve every problem that enterprises face. “A lot of research is going into developing more computationally efficient algorithms,” Smolinksi adds.
If a certain phrase exists within the LLM training data (e.g., is not itself generated text) and it can be reproduced with fewer input tokens than output tokens, then the phrase must be stored somehow within the weights of the LLM. We show that it appropriately ascribes many famous quotes as being memorized by existing LLMs (i.e.,
The model achieves this through a hierarchical token pruning algorithm, which dynamically removes less relevant context tokens. The framework enhances LLM capabilities by integrating hierarchical token pruning, KV cache offloading, and RoPE generalization. Also, decoding throughput is increased by 3.2 on enterprise-grade GPUs (L40S).
Speculative decoding applies the principle of speculative execution to LLM inference. The process involves two main components: A smaller, faster "draft" model The larger target LLM The draft model generates multiple tokens in parallel, which are then verified by the target model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content