This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its because the foundational principle of data-centric AI is straightforward: a model is only as good as the data it learns from. No matter how advanced an algorithm is, noisy, biased, or insufficient data can bottleneck its potential. Another promising development is the rise of explainabledata pipelines.
Answering them, he explained, requires an interdisciplinary approach. tweaktown.com Research Researchers unveil time series deep learning technique for optimal performance in AI models A team of researchers has unveiled a time series machine learning technique designed to address datadrift challenges.
In this process, the AI system's training data, model parameters, and algorithms are updated and improved based on input generated from within the system. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments. Let’s discuss this in more detail.
Baseline job datadrift: If the trained model passes the validation steps, baseline stats are generated for this trained model version to enable monitoring and the parallel branch steps are run to generate the baseline for the model quality check. Monitoring (datadrift) – The datadrift branch runs whenever there is a payload present.
True to its name, Explainable AI refers to the tools and methods that explain AI systems and how they arrive at a certain output. Artificial Intelligence (AI) models assist across various domains, from regression-based forecasting models to complex object detection algorithms in deep learning.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive software development and data science experience who wanted to implement MLOps. All looks good, but the (numerical) result is clearly incorrect.
Learn more The Best Tools, Libraries, Frameworks and Methodologies that ML Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP] Key use cases and/or user journeys Identify the main business problems and the data scientist’s needs that you want to solve with ML, and choose a tool that can handle them effectively.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
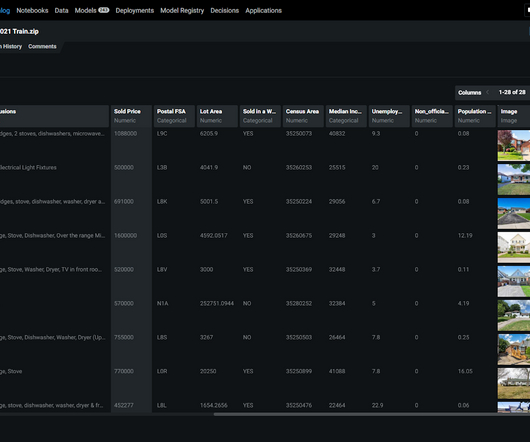
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Conduct exploratory analysis and data preparation. Determine the ML algorithm, if known or possible. Improve model accuracy: In-depth feature engineering (example, PCA) Hyperparameter optimization (HPO) Quality assurance and validation with test data. Monitoring setup (model, datadrift).
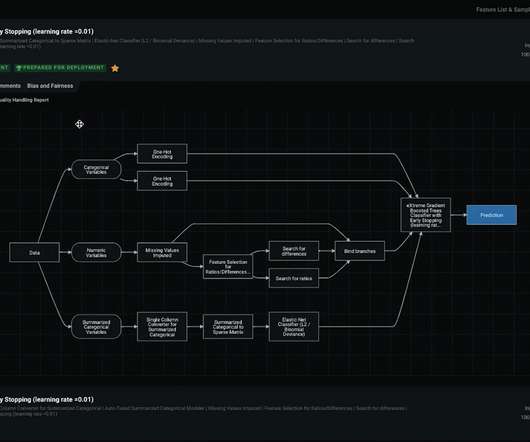
The model training process is not a black box—it includes trust and explainability. You can see the entire process from data to predictions with all of the different steps—as well as the supportive documentation on every stage and an automated compliance report, which is very important for highly regulated industries.
DataRobot does a great job of explaining exactly how it got to this feature. It joins the primary data with the city-level dataset and calculates the moving 90-day median. Delivering Explainable and Transparent Models with DataRobot Explainability is a key differentiator in DataRobot that allows for smoother collaboration on your team.
This explainability of the predictions can help you see how and why the AI came to these predictions. Set up a data pipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set. Ultimately, only the best algorithms that solve specific problems will survive.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes data quality, privacy, and compliance. To address this problem, an automated fraud detection and alerting system was developed using insurance claims data.
Monitoring Monitor model performance for datadrift and model degradation, often using automated monitoring tools. Optimization: Use database optimizations like approximate nearest neighbor ( ANN ) search algorithms to balance speed and accuracy in retrieval tasks.
along with the EU AI Act , support various principles such as accuracy, safety, non-discrimination, security, transparency, accountability, explainability, interpretability, and data privacy. This would enable developers worldwide to thoroughly examine, analyze, and improve AI, particularly focusing on training data and processes.
Elements of a machine learning pipeline Some pipelines will provide high-level abstractions for these components through three elements: Transformer : an algorithm able to transform one dataset into another. Estimator : an algorithm trained on a dataset to produce a transformer. Data preprocessing. Model deployment.
This vision is embraced by conversational interfaces which allow humans to interact with data using language, our most intuitive and universal channel of communication. After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. in the data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content